Apache Airflow
Apache Airflow es una plataforma de código abierto creada por Airbnb y gestionada por la Apache Software Foundation, que permite diseñar, programar y monitorizar flujos de trabajo (workflows) programables. Airflow no ejecuta código por sí mismo, sino que coordina cuándo, cómo y en qué orden deben ejecutarse tareas definidas por el usuario. Es una herramienta fundamental en entornos de ingeniería de datos moderna, donde se requiere que procesos complejos se ejecuten en etapas secuenciales o paralelas con condiciones lógicas.
Airflow es útil porque permite automatizar y gestionar pipelines de datos complejos con lógica condicional, dependencias entre tareas, manejo de errores, reintentos, programación periódica y visibilidad total desde una interfaz web. Su diseño modular y extensible permite integrarse con servicios en la nube, bases de datos, APIs, sistemas de ficheros, y más. Además, está pensado para escalar horizontalmente y adaptarse tanto a pequeños scripts diarios como a grandes flujos de datos empresariales.
Arquitectura
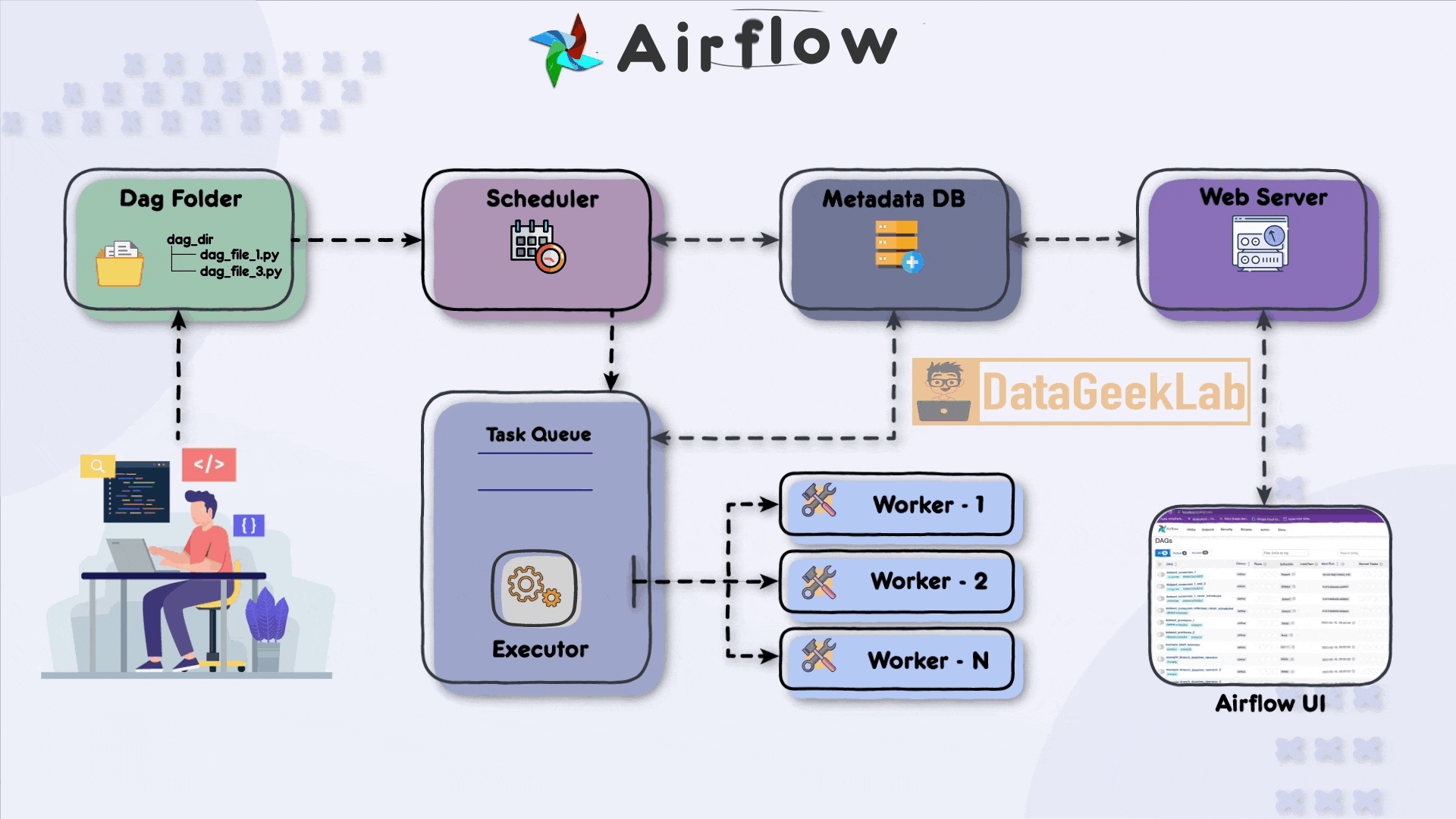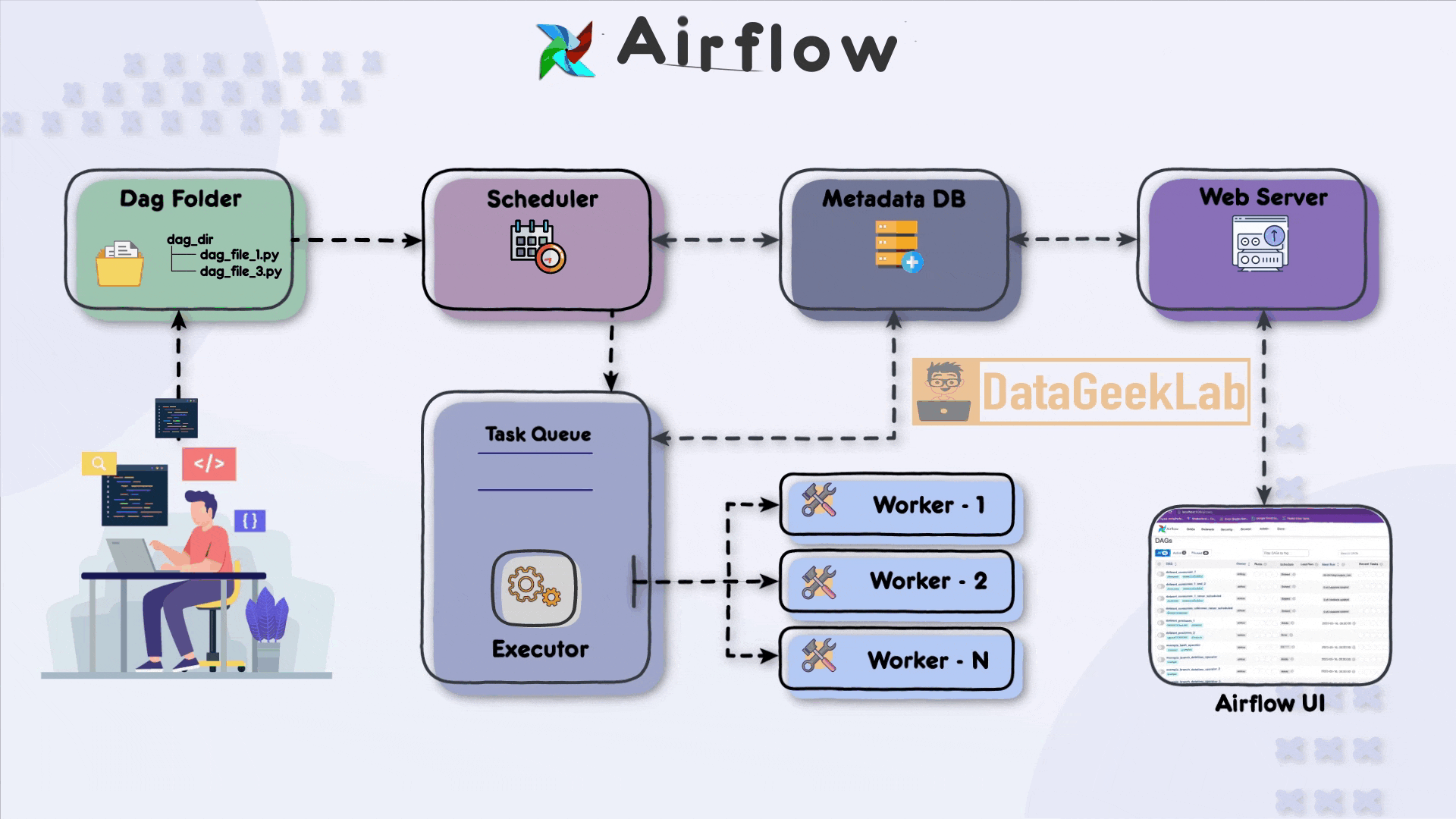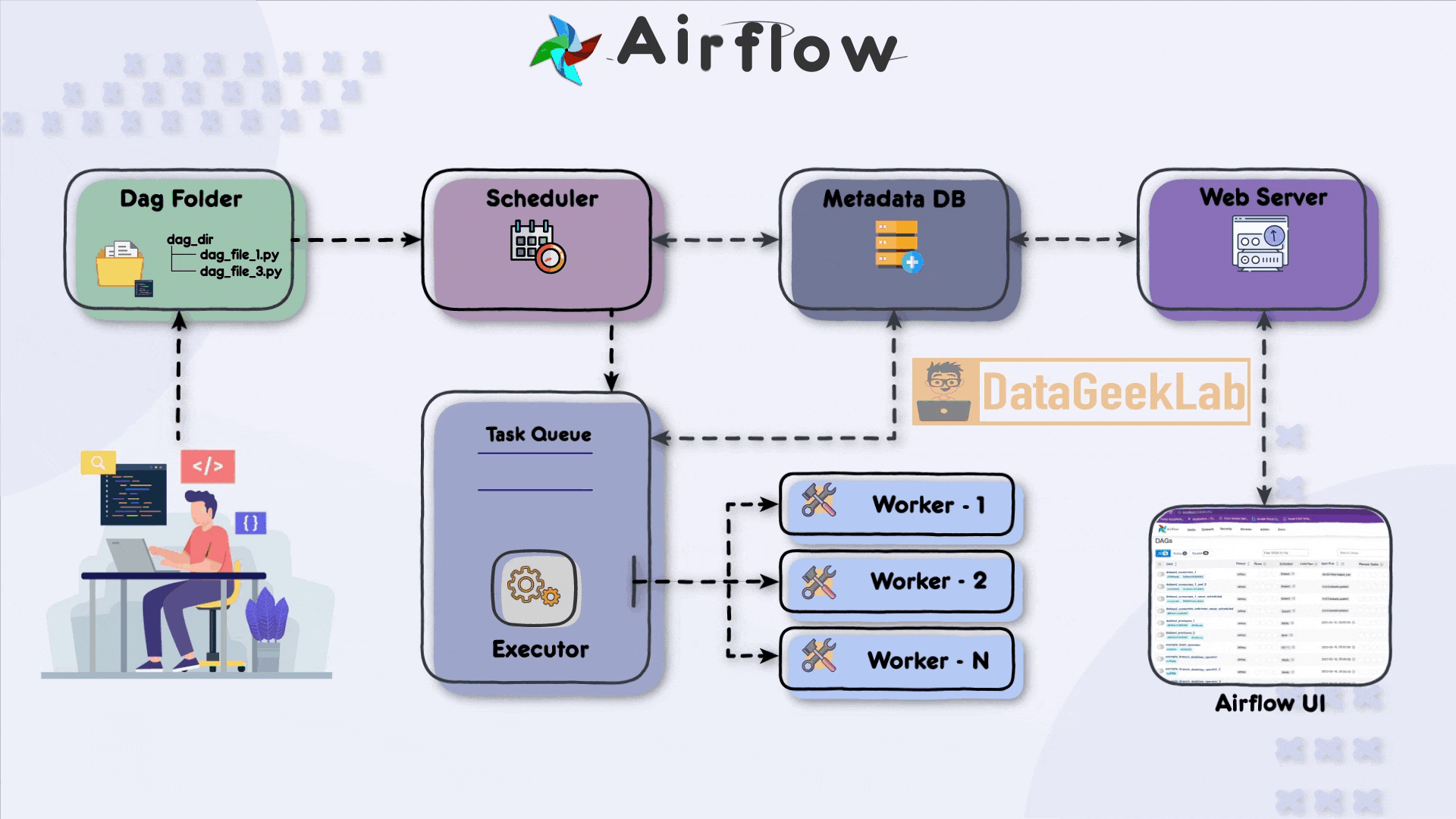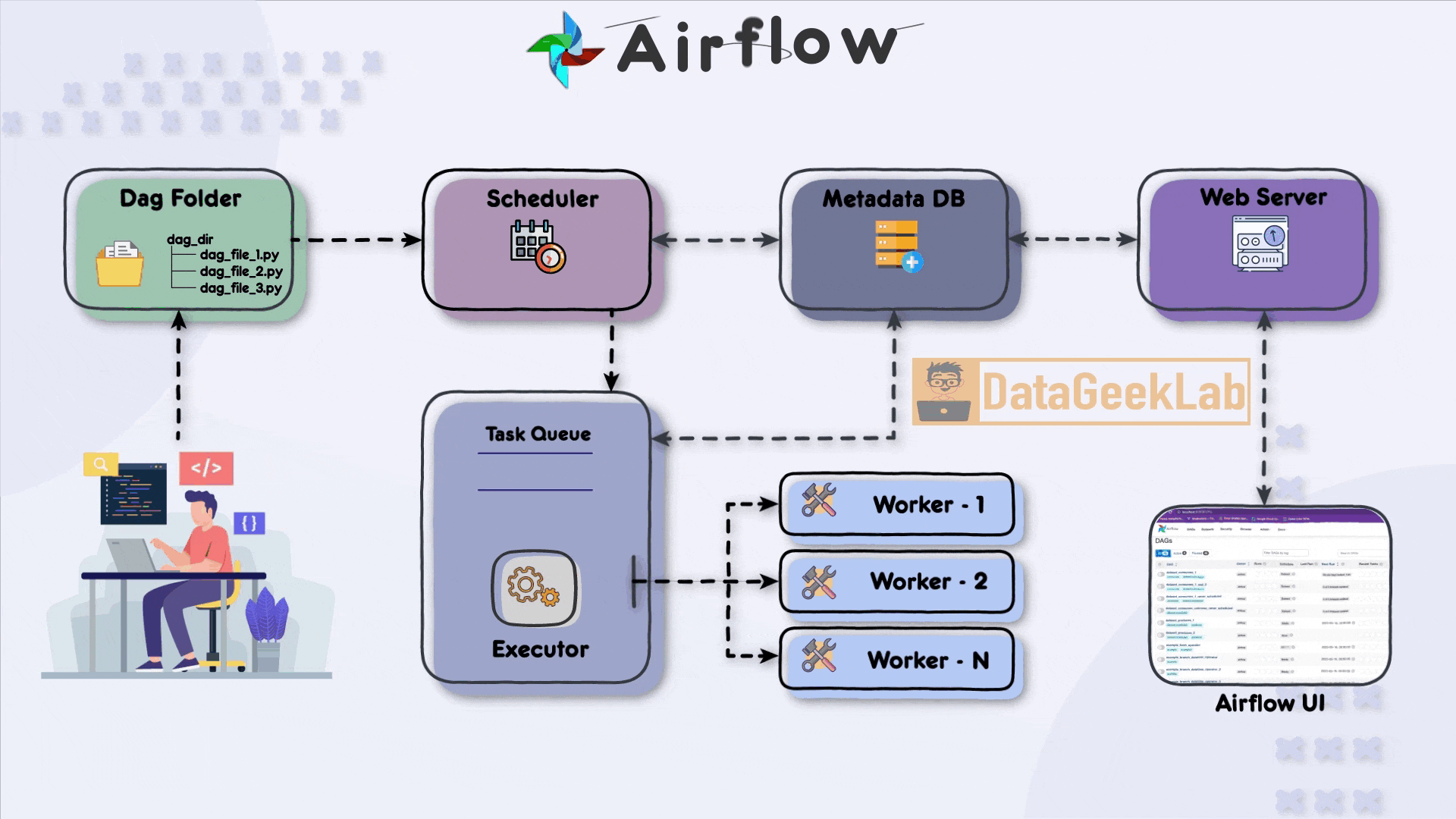
Airflow se compone de varios servicios que trabajan juntos:
- 🪁
Scheduler: Escanea los DAGs y programa las tareas según su definición temporal y dependencias. - 🪁
Webserver: Proporciona la interfaz web para visualizar el estado de los DAGs, logs, ejecuciones pasadas y detalles de las tareas. - 🪁
Worker(s): Ejecutan las tareas que han sido programadas. Pueden escalarse horizontalmente. - 🪁
Metadata Database: Guarda toda la información sobre DAGs, tareas, logs, estados y configuraciones. Usa PostgreSQL o MySQL. - 🪁
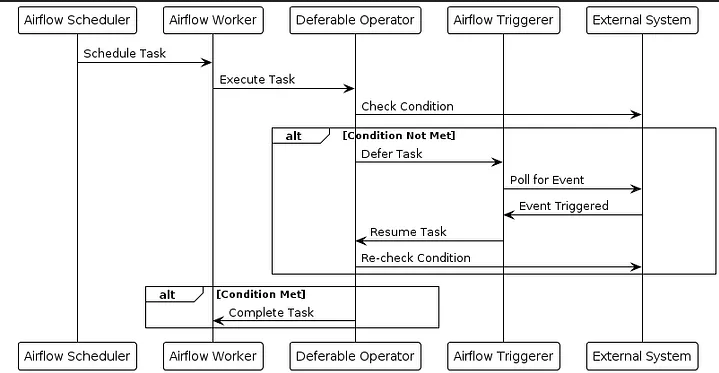
Triggerer (a partir de Airflow 2): Gestiona los Deferrable Operators y reduce el consumo de recursos al esperar eventos externos.
Componentes Fundamentales
DAGs (Directed Acyclic Graphs)
Los DAGs son la unidad principal de Airflow. Representan un flujo de trabajo como un grafo dirigido sin ciclos. Cada nodo es una tarea, y las aristas representan dependencias entre ellas. Están definidos en archivos Python que se cargan dinámicamente.
Tasks y Operators
Una Task es una unidad de trabajo. Se define a través de un Operator, que es una plantilla que encapsula una acción específica.
- 📑
PythonOperator: ejecuta una función Python. - 📑
BashOperator: ejecuta comandos de bash. - 📑
EmailOperator: envía correos. - 📑
DockerOperator: ejecuta tareas dentro de un contenedor Docker. - 📑
KubernetesPodOperator: ejecuta pods en Kubernetes.
Sensors
Los Sensors son tareas que esperan a que ocurra una condición externa. Por ejemplo, un archivo aparezca, una tabla esté disponible, o una API responda. Existen sensores como FileSensor, S3KeySensor, ExternalTaskSensor.
Deferrable Operators y Triggerer
A partir de Airflow 2, se introdujeron los Deferrable Operators, que permiten suspender una tarea en espera de un evento sin ocupar un worker. Estas tareas son gestionadas por el Triggerer, que utiliza async IO para mantenerlas vivas de manera eficiente.
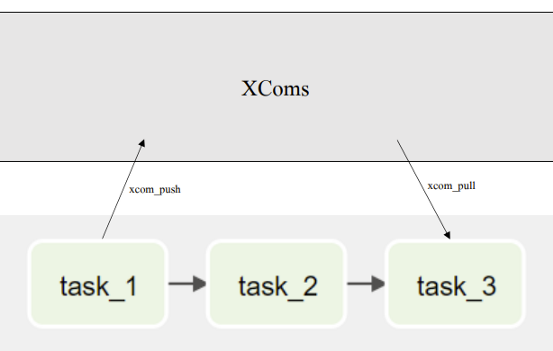
XCom (Cross-Communication)
XCom (Cross-Communication) es el mecanismo de Airflow para compartir pequeños datos entre tareas de un mismo DAG. Los datos se almacenan en la base de datos de Airflow (tabla xcom).
📄 Puedes “empujar” un valor desde una tarea y “jalarlo” desde otra.
- 🔸
xcom_push() - ∘
execution_date: Siempre se guarda en XCom y determina a qué ejecución (DAGRun) pertenece el dato. - ∘ Puedes sobrescribir el execution_date.
- 🔸
xcom_pull() - ⊡ Mismo dag_id (DAG actual).
- ⊡ Mismo execution_date (solo datos de la ejecución actual).
📄 Se usa para enviar datos. Internamente, Airflow ejecuta:
Se usa para recuperar datos. Por defecto, busca registros con:
📄 Por defecto, se filtran los resultados por la ejecución actual.
∘ No mezcla datos entre diferentes ejecuciones del DAG.
El execution_date es crucial porque Airflow, por defecto, aísla los XComs entre ejecuciones, requiriendo que se especifique manualmente un execution_date diferente para acceder a datos de otros DAGRuns.
No abuses de XCom, no está diseñado para datos grandes (usa sistemas externos como S3 o Redis para eso).
Hooks y Providers
- 🔸
Hooks: Son interfaces reutilizables para interactuar con sistemas externos: S3, MySQL, BigQuery, etc. - ∘
Interfaz unificada: Proporcionan una forma estandarizada de interactuar con sistemas externos. - ∘
Manejo de conexiones: Gestionan automáticamente las conexiones, sesiones y autenticaciones. - ∘
Reutilizables: Pueden ser usados múltiples veces en diferentes tareas y DAGs. Database Hooks: - ∘
PostgresHook: Para PostgreSQL (conexiones a PostgreSQL). - ∘
MySqlHook: Para MySQL (gestión de MySQL). Cloud Hooks: - ∘
S3Hook: Interactúa con Amazon S3 (almacenamiento en S3). - ∘
GCSHook: Para Google Cloud Storage (acceso a GCS). API Hooks: - ∘
HttpHook: Para llamadas HTTP (solicitudes HTTP). - ∘
SlackHook: Notificaciones en Slack (mensajes a Slack). - 🔸
Providers: Son paquetes que agrupan hooks, operators, sensors y configuraciones para integrar servicios como Google Cloud, AWS, Slack, Snowflake, etc.
Los hooks, también conocidos como "conectores" o "enlaces", son componentes fundamentales en Airflow que actúan como interfaces, puentes o conectores entre Airflow y sistemas externos. Estos hooks permiten la interacción, conexión y comunicación con diversas plataformas, bases de datos y servicios.
Características clave:
Tipos Comunes de Hooks:
Los hooks de Airflow simplifican la interacción con sistemas externos al abstraer la lógica de conexión, recuperando credenciales de las Connections de Airflow, estableciendo la conexión, ejecutando operaciones y cerrándola automáticamente al finalizar su uso.
📄 Ejemplo de Uso:
Variables y Connections
- ∘
Variables: Claves/valores que se almacenan en la base de datos y pueden usarse desde cualquier DAG. - ∘
Connections: Configuraciones predefinidas de conexión con servicios externos (host, puerto, usuario, contraseña, etc.).
📄 Estas se configuran desde la UI o vía CLI:
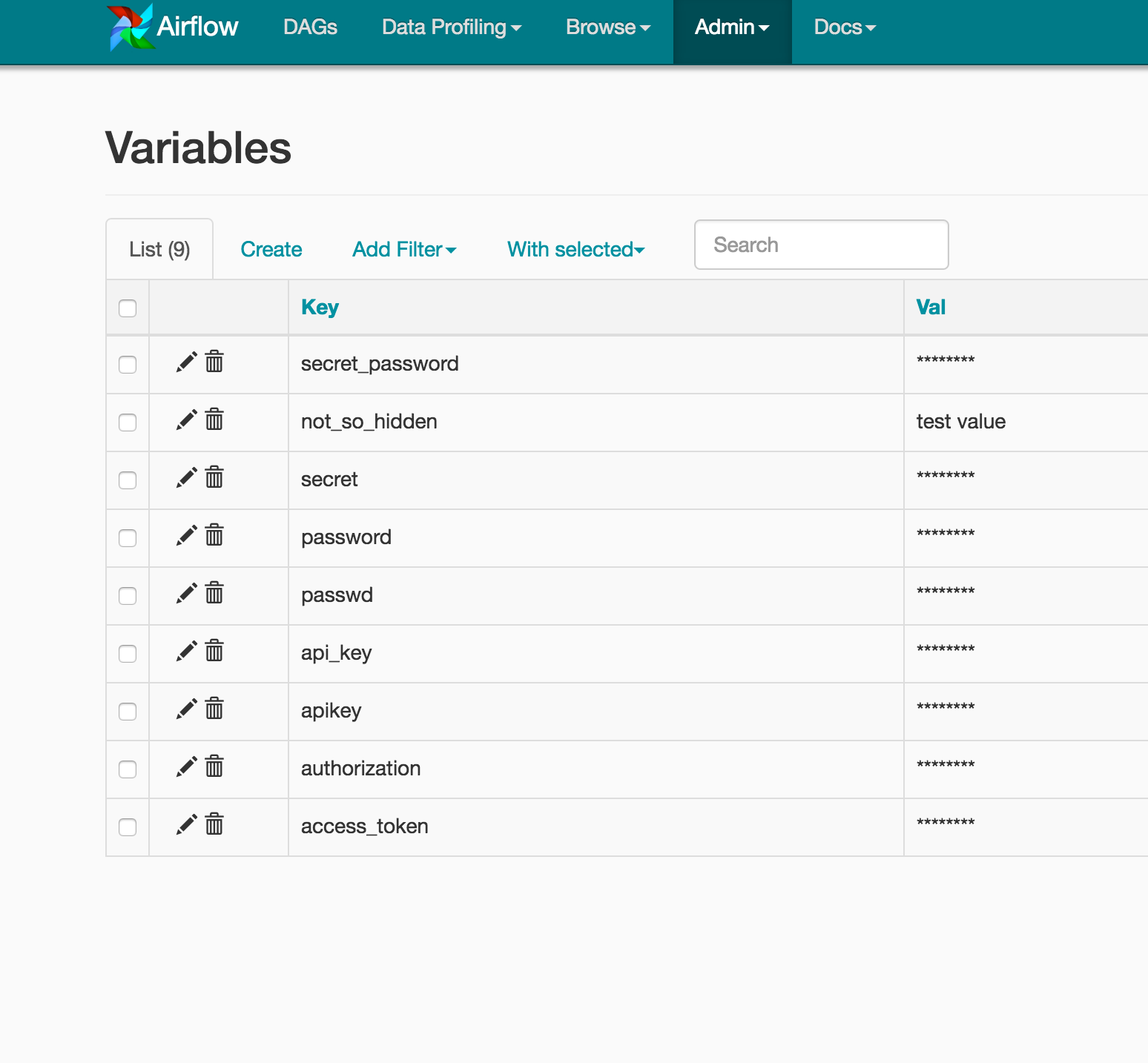
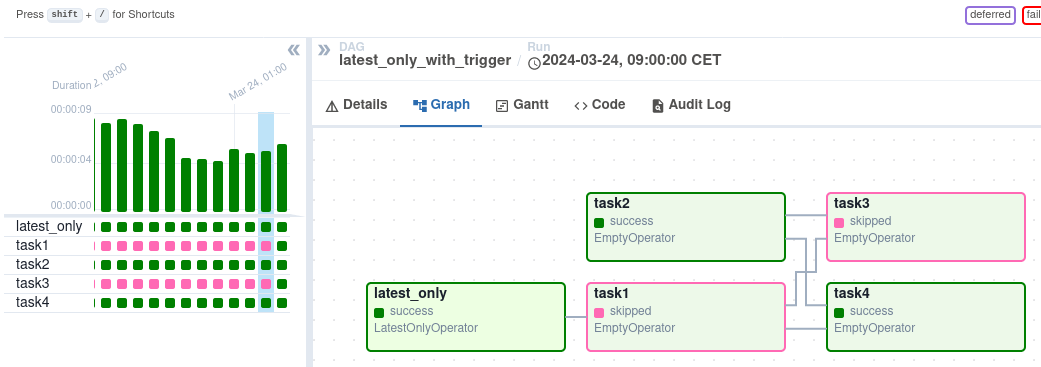
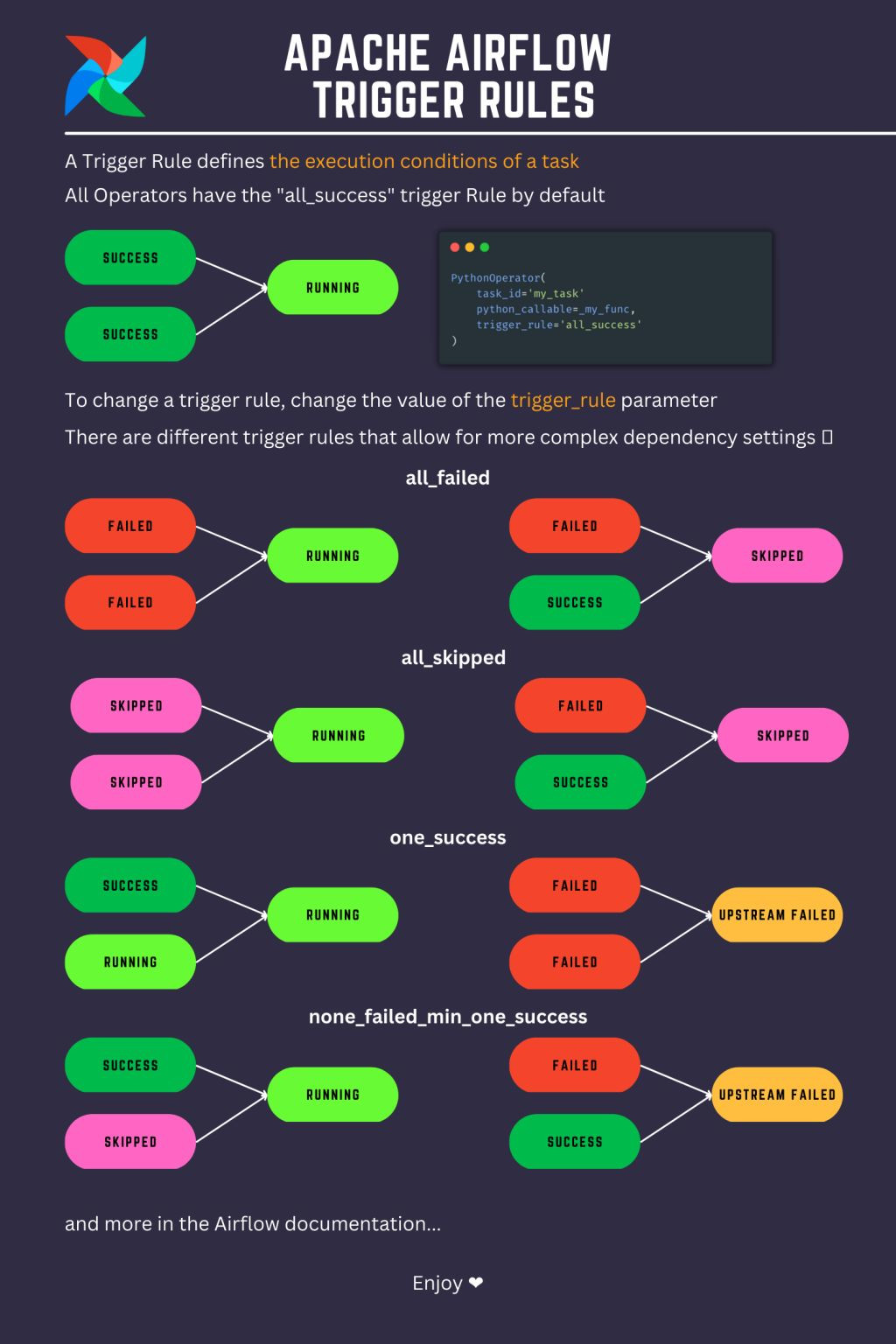
Trigger Rules y Condicionales
Las Trigger Rules controlan cuándo se ejecuta una tarea según el estado de las tareas anteriores. Ejemplo: all_success, one_failed, all_done, etc.
📄 Puedes crear flujos condicionales dinámicos usando operadores como BranchPythonOperator:
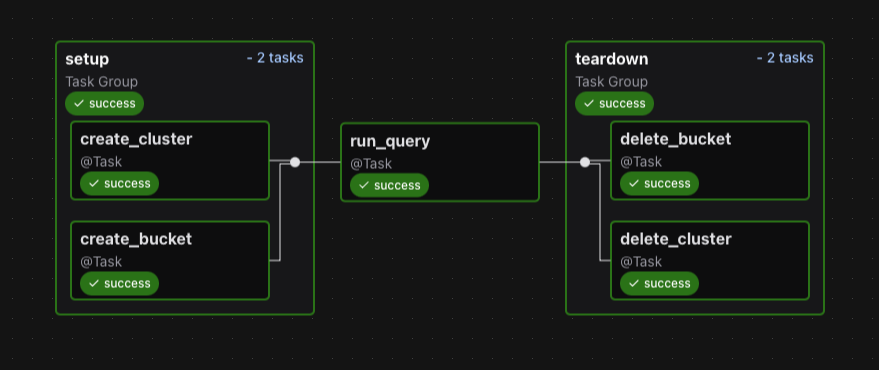
Setup y Teardown
A partir de Airflow 2.6, se introdujo setup y teardown para definir tareas que deben ejecutarse al inicio o al final de un DAG (como preparar o limpiar recursos), independientemente del éxito o fallo de otras tareas.
Decorators
Los Decorators (@task, @dag) permiten definir tareas y DAGs de forma más limpia y funcional desde Python puro.

Proyecto con Docker Compose en Linux
Puedes consultar la documentación oficial de Apache Airflow para instalarlo utilizando Docker Compose.
En tu máquina, puedes corregir los permisos (50000:1000) para que el contenedor corra como un usuario no-root.
Edita el archivo
Revisa con
La contraseña predeterminada para el usuario airflow en las instalaciones iniciales de Apache Airflow es también airflow.
⌭ Modificar el
La contraseña predeterminada para el usuario admin@admin.com en el panel de login de la base de datos pgAdmin es root.

❏ Buscar el contenedor postgre.
ryuzak1@ubuntu: ~
❏ Buscar la IP del contenedor postgre.
ryuzak1@ubuntu: ~
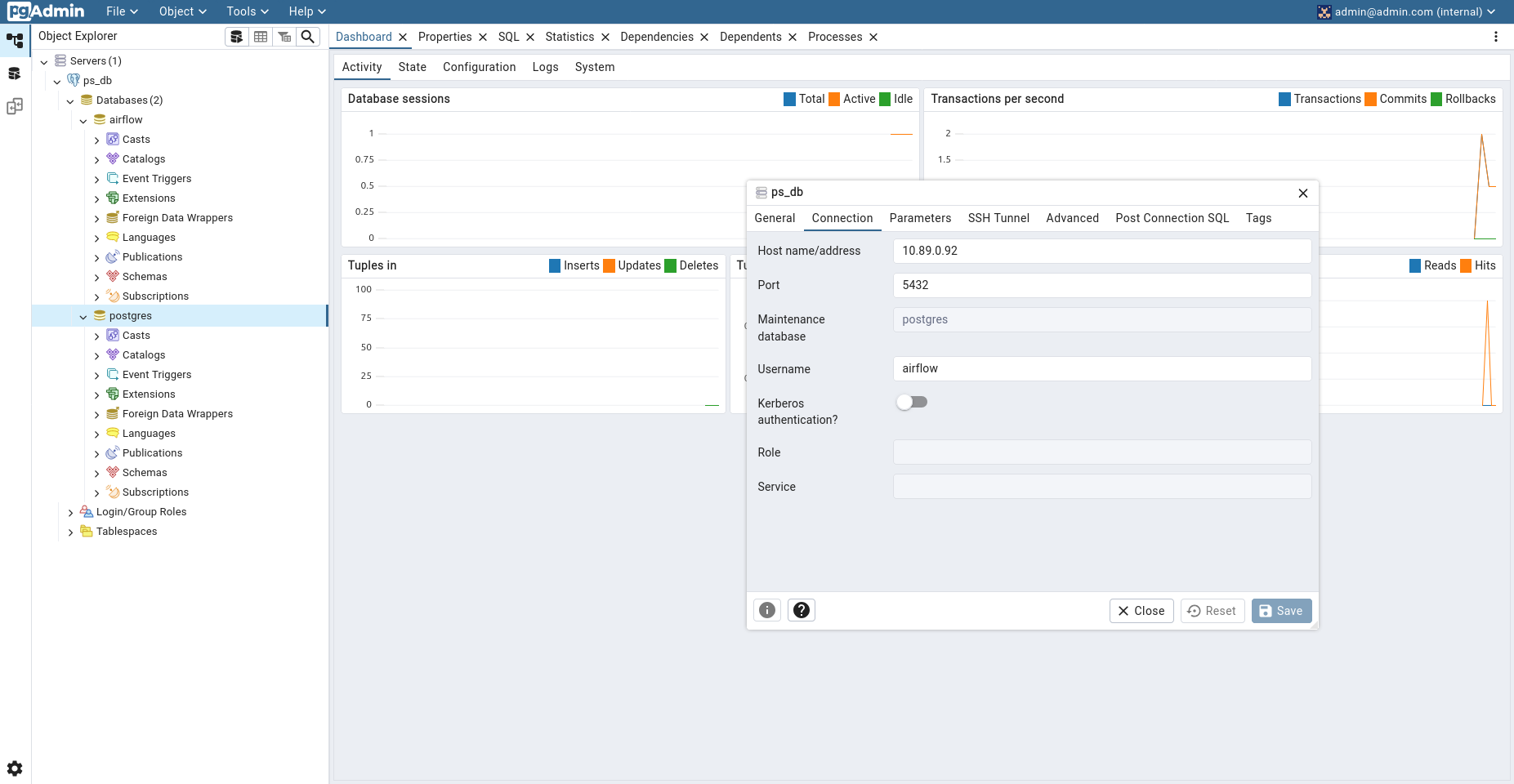
Se tiene que añadir un nuevo servidor con los siguientes valores: en Name, poner 'ps_db'. En la sección de Connections, colocar la IP en el campo Hostname, y 'airflow' en Username y Password. Por último, hacer clic en Save.
El proyecto requiere una base de datos para almacenar la información extraída de productos de la web de Amazon. Para crearla, haz clic derecho sobre "Databases" y establece el nombre 'amazon_books'.
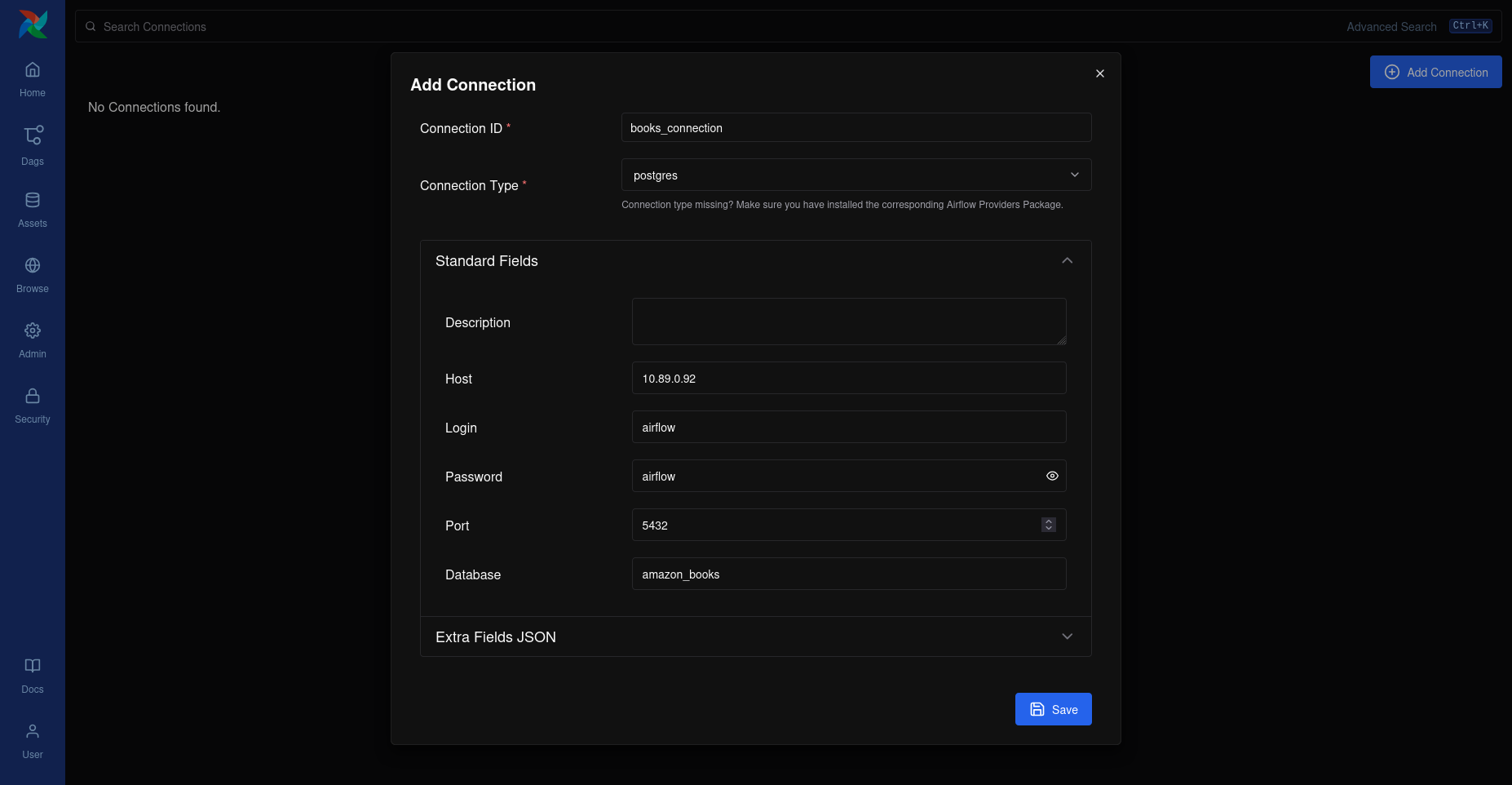
En la sección de "Admin" y luego en "Connections", crea una nueva conexión con los siguientes valores:
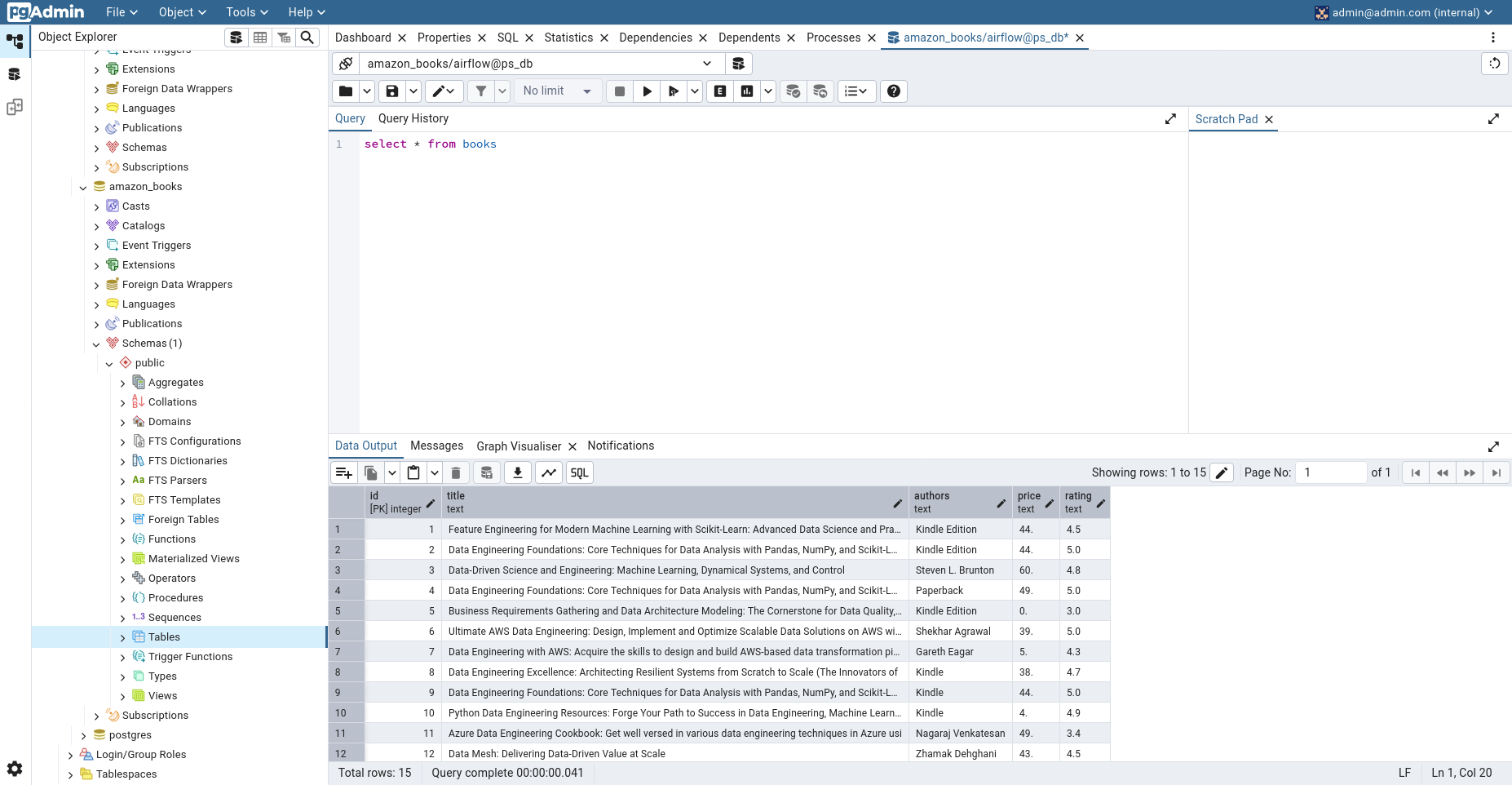
Este proyecto de Airflow automatiza la extracción de información de libros de ingeniería de datos desde la página de resultados de búsqueda de Amazon. Utiliza Python para realizar el scraping web, parseando el HTML con BeautifulSoup para extraer títulos, autores, precios y calificaciones. Los datos extraídos se almacenan temporalmente utilizando XComs y luego se insertan en una base de datos PostgreSQL. El flujo de trabajo incluye la creación de la tabla en PostgreSQL (si no existe), la obtención de los datos de Amazon y la posterior inserción de estos datos en la tabla, todo orquestado por Airflow de forma diaria.
⌭ Crear un script con el nombre dag.py en la carpeta dags y modificar la fecha.
En la sección de DAGs, localiza y ejecuta el DAG denominado fetch_and_store_amazon_books haciendo clic en el botón de "Play".
Posteriormente, dirígete a pgAdmin para verificar los datos recopilados de Amazon. Para ello, haz clic derecho sobre la sección "Tables" y selecciona la opción "Query Tool".
Proyecto en la Nube
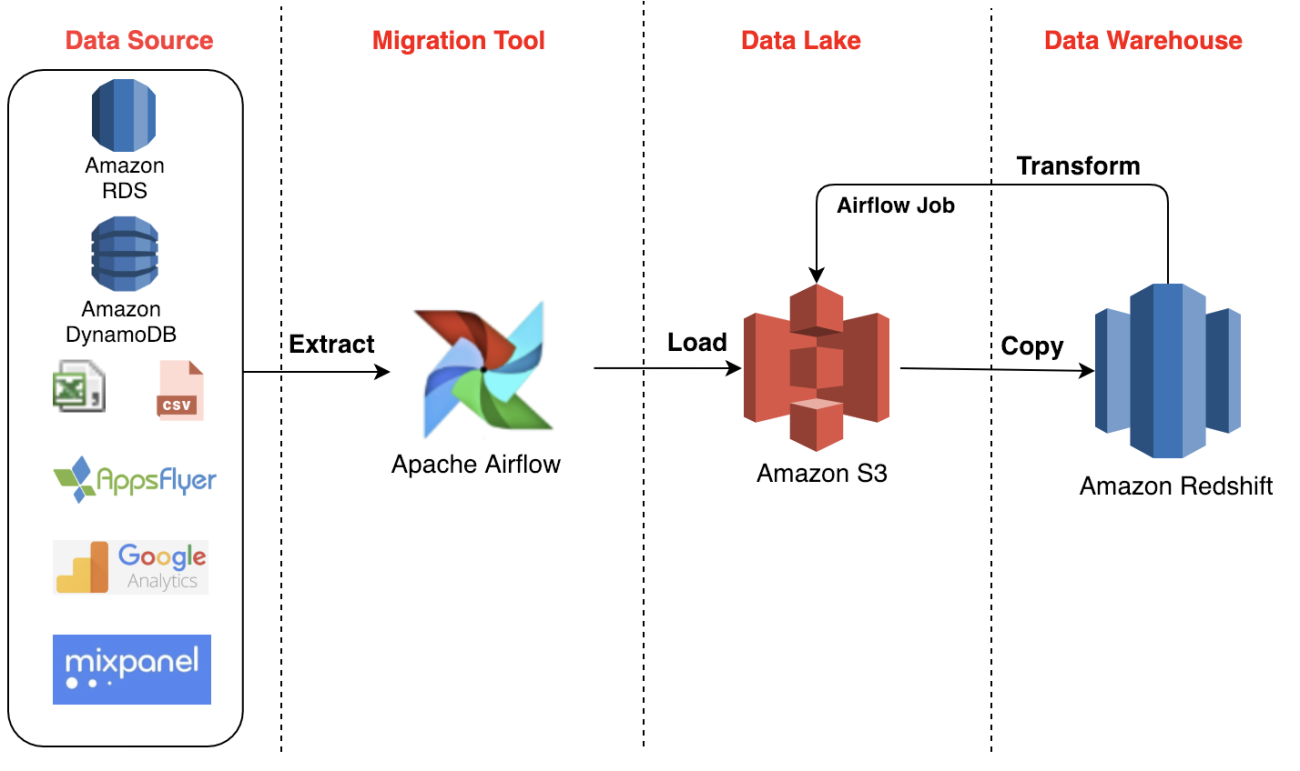
En el mundo del análisis de datos, la capacidad de extraer información valiosa de redes sociales como Twitter y almacenarla de manera eficiente es fundamental. Un proyecto ETL (Extract, Transform, Load) que utiliza Python para conectarse a la API de Twitter, procesar los datos y cargarlos en un bucket de Amazon S3 puede ser una solución escalable y automatizada para este propósito.
El proyecto consiste en un flujo automatizado que:
Extrae tweets en tiempo real o históricos mediante la API de Twitter (usando bibliotecas como tweepy o python-twitter).Transforma los datos crudos, aplicando filtros, limpieza de texto, análisis de sentimientos o estructurado en un formato óptimo (como CSV, JSON o Parquet).Carga la información procesada en un bucket de Amazon S3, utilizando el SDK de AWS (boto3), donde podrá ser consultada por herramientas de analytics o machine learning.
Este proceso puede ejecutarse periódicamente mediante servicios como AWS Lambda o Airflow, garantizando una base de datos actualizada para su posterior análisis.
Generar un Access Token para Twitter
Para comenzar a usar la API de Twitter, dirígete a Twitter Developer Platform, inicia sesión con tu cuenta de Twitter, y luego solicita el acceso de desarrollador gratuito a través del nivel "Essential".
Una vez dentro del panel de desarrollador de Twitter, navega a la sección "Projects & Apps" y selecciona "Overview". Aquí, procederás a usar el proyecto default. Este proyecto te proporcionará las credenciales esenciales para interactuar con la API de Twitter: el Bearer Token , con las opciones de generar el Bearer Token.
Conexión con la API de Twitter
⌭ Crear un script en Python que se conecta a la API de Twitter usando tweepy y recupera los 10 últimos tweets de un usuario, mostrándolos por pantalla. Sirve para analizar o monitorear contenido público de una cuenta.
⌭ El siguiente script se conecta con la API v2 de Twitter para extraer los últimos tweets del usuario especificado (en este caso, elonmusk), y luego guarda información relevante como el texto del tweet, número de likes, retweets y la fecha de creación en un archivo CSV llamado refined_tweets.csv.
Como variante se puede utilizar la API de YouTube Data v3 para extraer y procesar todos los comentarios de un video específico de YouTube. Primero se configura la conexión con la API, luego se realizan solicitudes paginadas para obtener los comentarios (hasta 100 por petición) y las procesa para extraer información clave como el autor, el texto del comentario y la fecha de publicación. La aplicación maneja automáticamente la paginación para recolectar todos los comentarios disponibles. Los datos son estructurados en una lista de diccionarios para su fácil análisis, mostrando finalmente un resumen con el total de comentarios recolectados. El código incluye manejo de errores para casos donde la estructura de los comentarios no sea la esperada, y está diseñado para ser fácilmente integrable en sistemas más grandes de análisis de datos o moderación de contenido.
Para obtener una Clave de API, ve a la Consola de APIs de Google, donde podrás crear un nuevo proyecto o seleccionar uno ya existente. Después, activa la API de YouTube Data API v3 y dirígete a la sección "Credenciales" para crear una nueva Clave de API, la cual deberás copiar una vez generada.
⌭ El script para obtener comentarios de YouTube quedaría de la siguiente forma:
Creación de Recusos en AWS
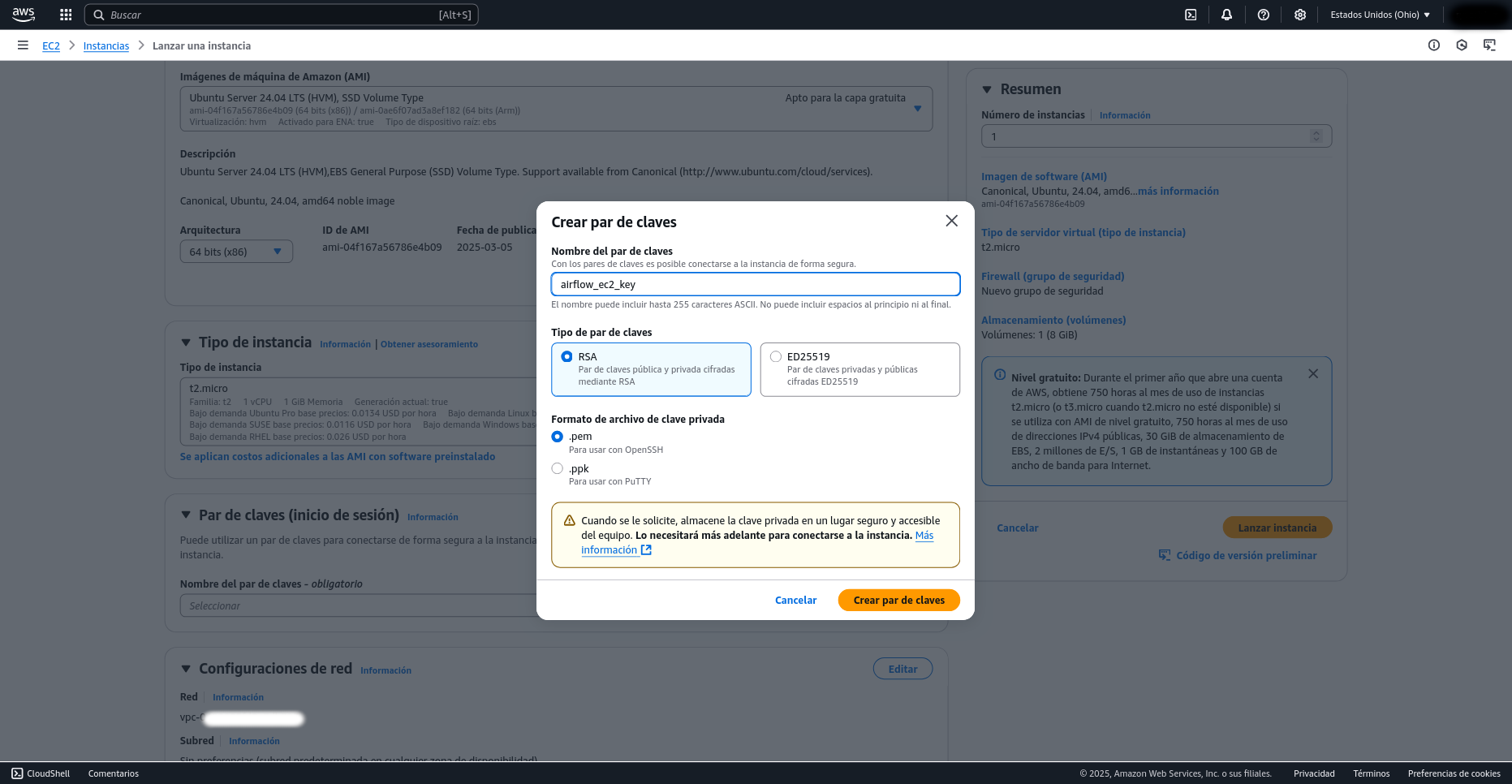
Para desplegar Apache Airflow en una instancia EC2 de AWS, primero debes iniciar sesión en la consola de AWS y dirigirte al servicio EC2 para lanzar una nueva instancia. Elige una Amazon Machine Image (AMI) basada en Ubuntu, como Ubuntu Server 24.04 LTS, ya que es compatible y ampliamente usada. Luego, selecciona un tipo de instancia adecuado; para pruebas, una t2.micro es suficiente si estás en el plan gratuito. Configura el almacenamiento (el valor por defecto de 8 GB suele ser suficiente) y elige o crea un par de claves SSH para acceder de forma segura a tu máquina. Asegúrate de configurar correctamente el grupo de seguridad: permitiendo el tráfico en el puerto 22 para el acceso SSH y el puerto 8080 para la interfaz web de Airflow.
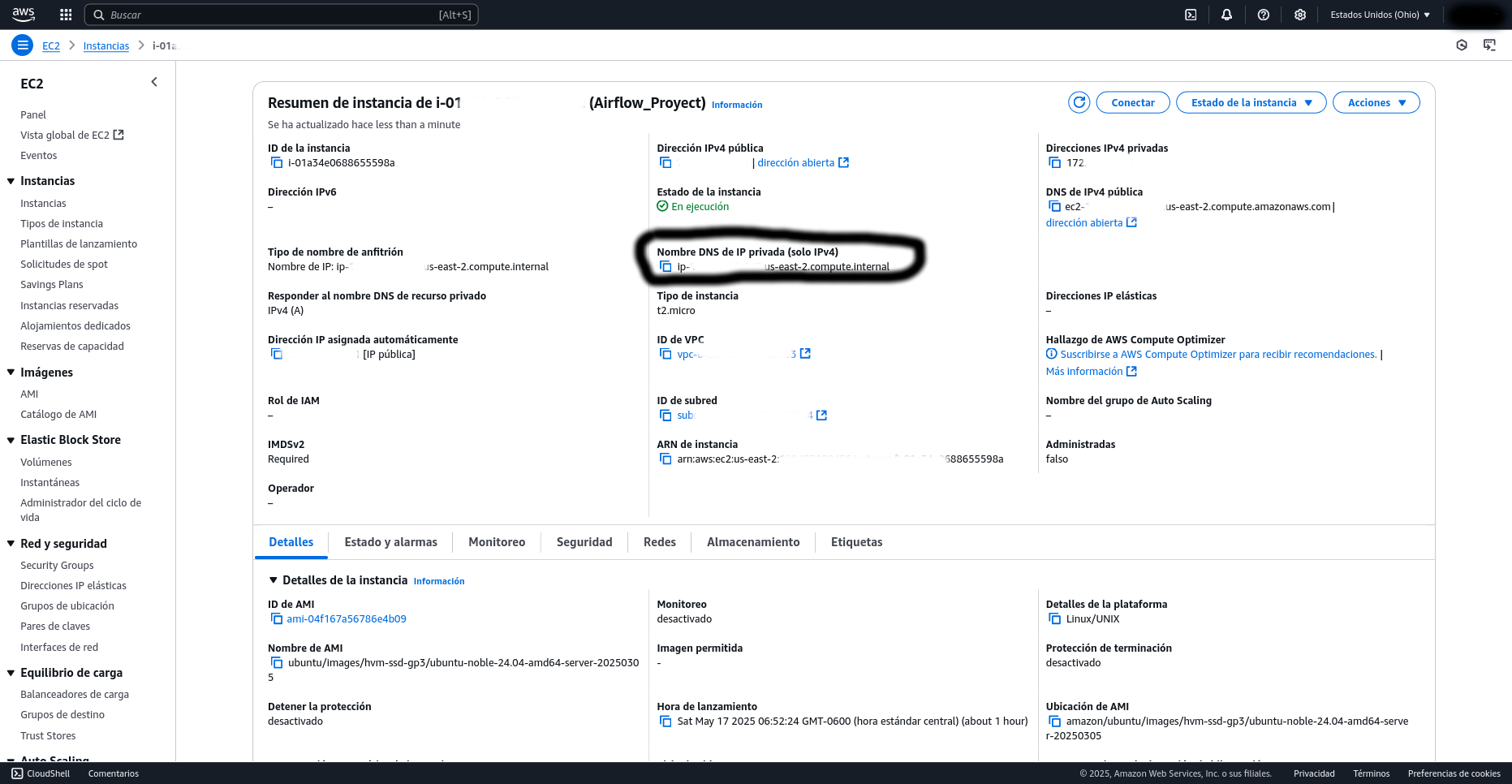
Para iniciar una sesión SSH en tu instancia EC2, primero necesitas ubicarte en el directorio donde se encuentran las claves SSH que descargaste previamente, ya que estas son esenciales para la autenticación segura. Una vez en la carpeta correcta, dirígete a la consola de AWS, selecciona tu instancia de Airflow en la sección EC2, y haz clic en el botón "Conectar"; allí encontrarás los detalles y el comando SSH exacto que debes usar para acceder a tu máquina.
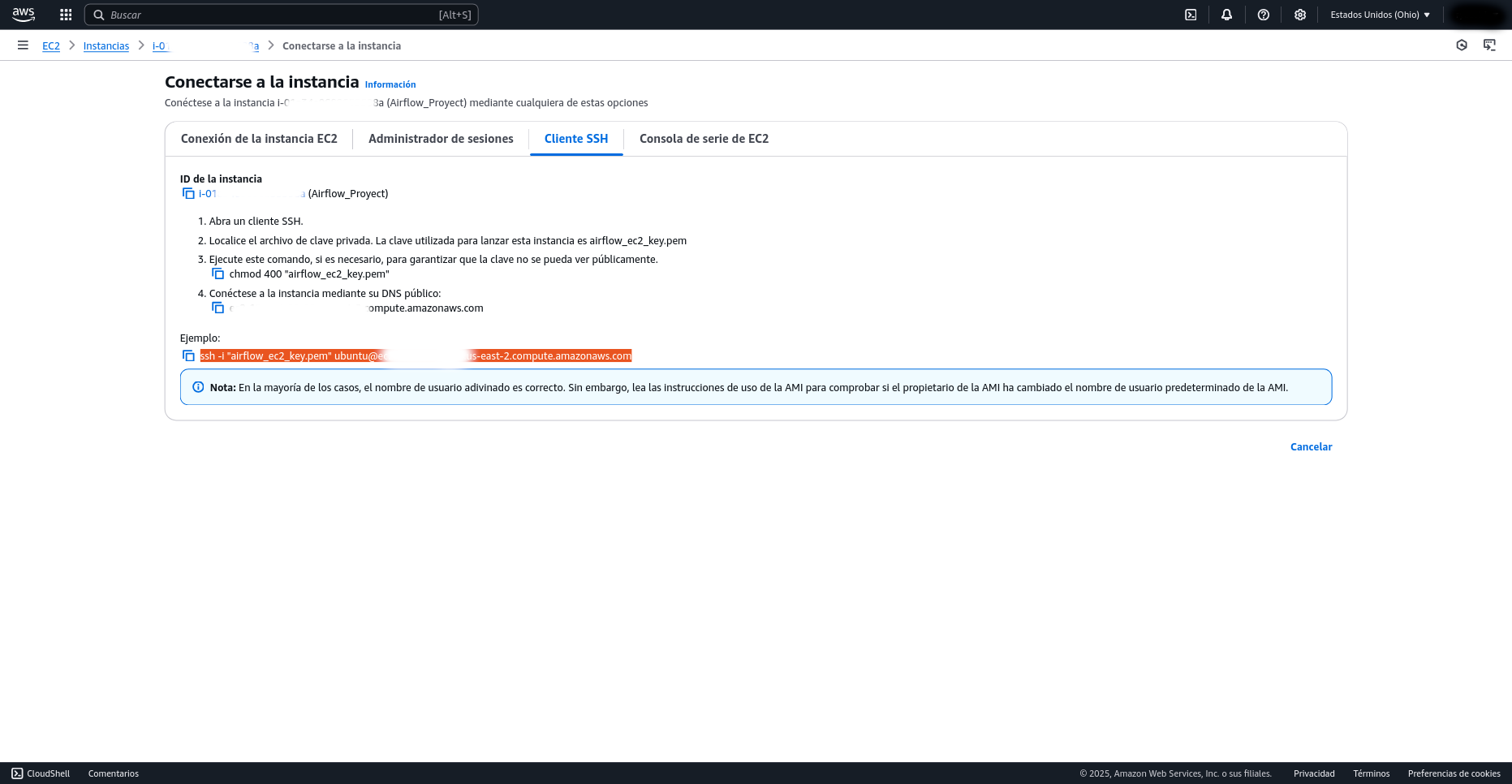
Posteriormente, deberás editar el archivo de configuración de Airflow,
Usar el SequentialExecutor es la mejor opción para tu servidor con recursos limitados, ya que es más simple y ligero. Para configurarlo, deberás abrir tu archivo
Adicionalmente, dentro del mismo archivo
Si te encuentras con problemas para añadir un nuevo usuario mediante los comandos habituales, una alternativa es utilizar
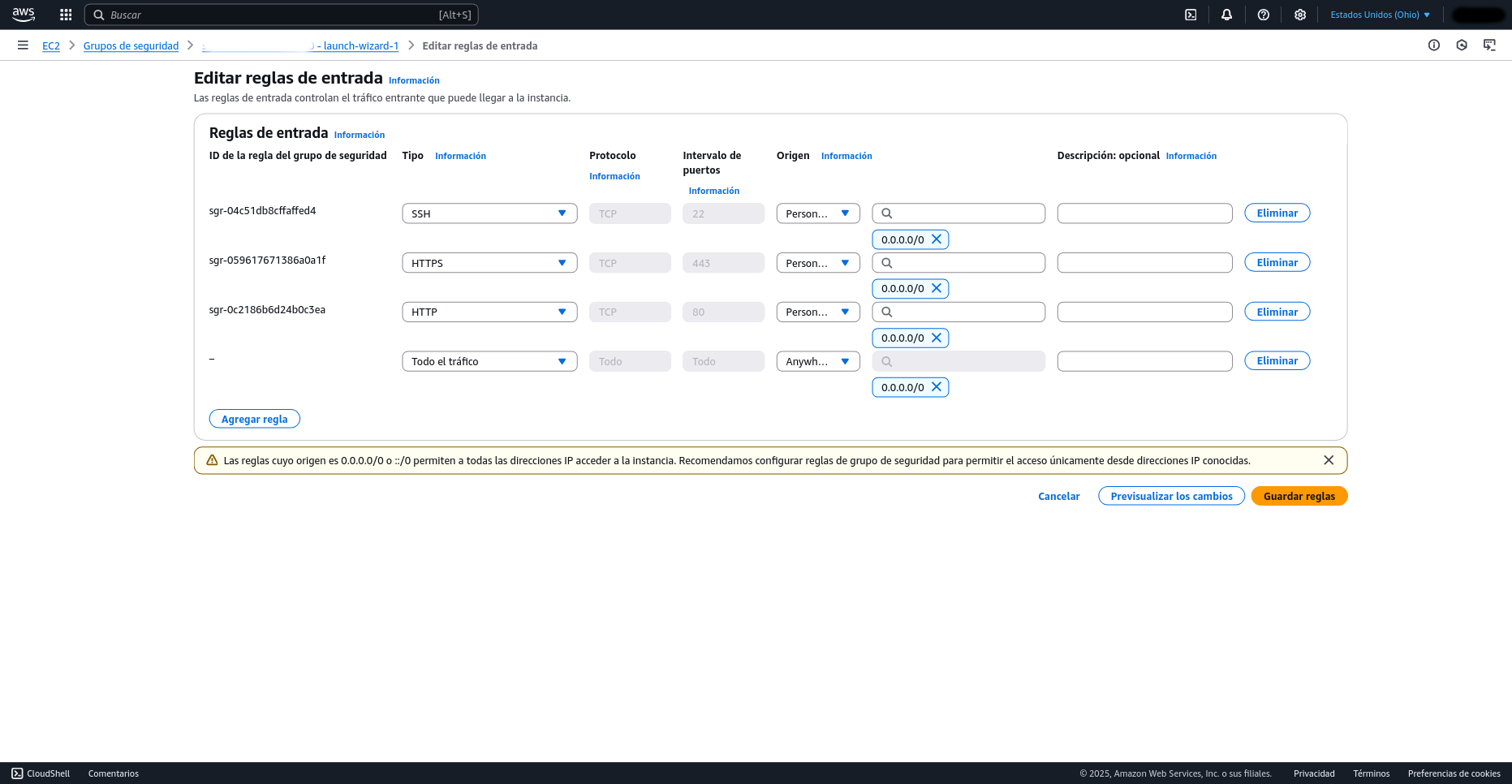
Para acceder a la interfaz web de Airflow en tu instancia EC2, primero dirígete a la sección de instancias en la consola de AWS y haz clic sobre tu instancia de Airflow para obtener su DNS público. Luego, pega este DNS en tu navegador web, asegurándote de apuntar al puerto 8080 (ej. http://tu-dns-publico:8080). Es crucial que la aplicación sea accesible externamente; para ello, navega hasta la sección de "Seguridad" dentro de los detalles de tu instancia, entra en el grupo de seguridad asociado y, a través del botón "Editar reglas de entrada" (Edit inbound rules), añade una nueva regla que permita todo el tráfico (All traffic) desde cualquier origen (Anywhere-IPv4).
Ten en cuenta que permitir todo el tráfico desde cualquier origen es un riesgo de seguridad. Sin embargo, dado que esta instancia es solo para pruebas y se eliminará después de terminar para evitar el consumo de recursos gratuitos, es aceptable en este contexto.
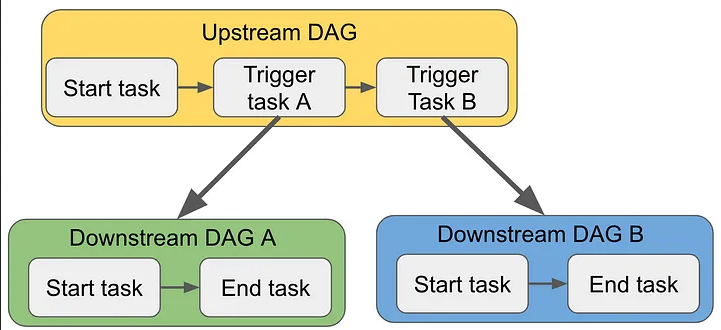
Ahora que Airflow está funcional, es necesario tener nuestro DAG listo. Este DAG, llamado twitter_dag.py, hará una llamada a la función run_twitter_etl que se encuentra dentro de nuestro script de Twitter, twitter_etl.py.
⌭ El siguiente DAG corre diariamente y ejecuta una función Python llamada run_twitter_etl, la cual conecta a la API de Twitter, extrae datos y los transforma o guarda en S3 de AWS.
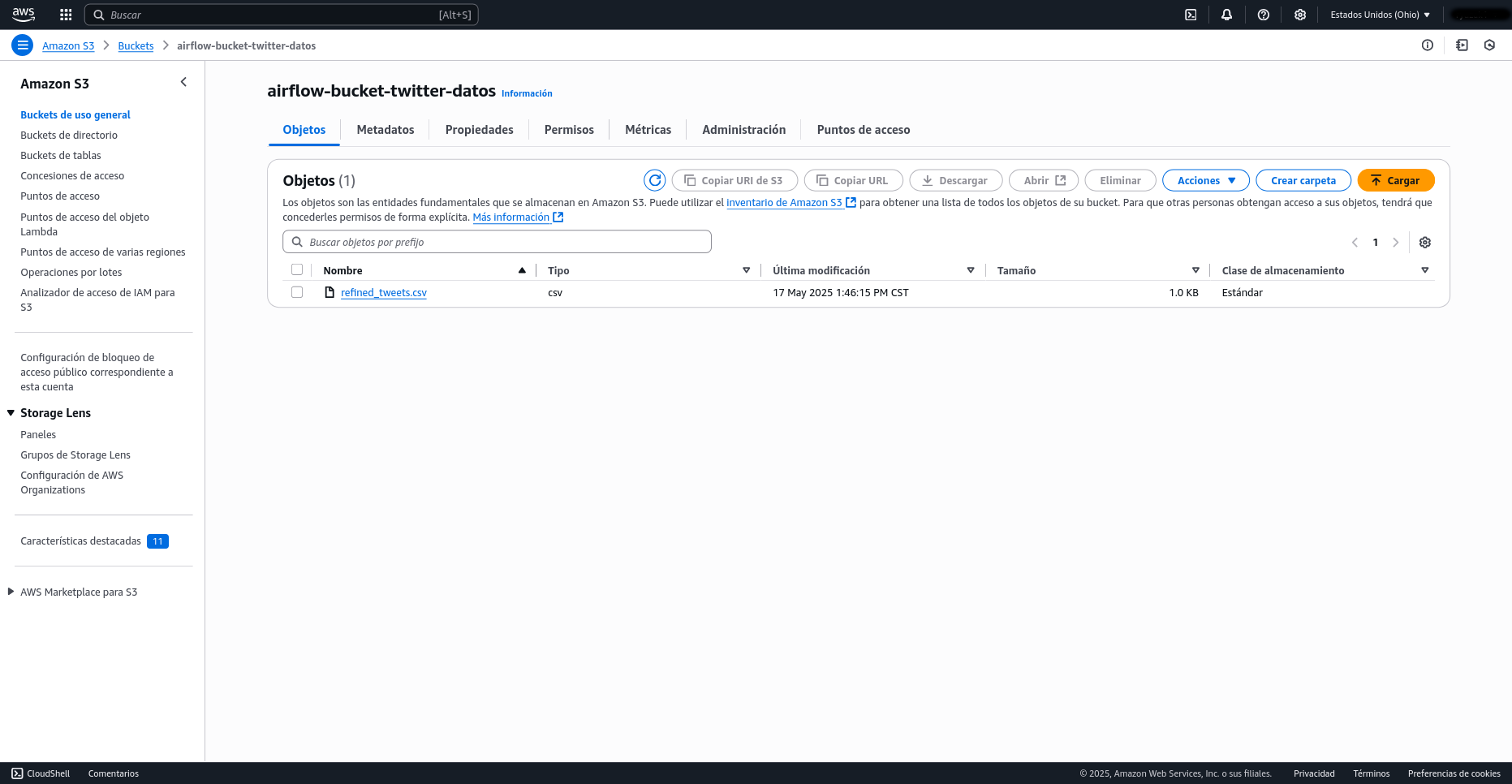
Para crear un bucket S3, inicia sesión en la Consola de AWS y navega hasta el servicio S3. Una vez allí, haz clic en "Crear bucket" y asígnale un nombre único que sea globalmente distintivo (por ejemplo, airflow-bucket-twitter-datos). Puedes dejar las configuraciones de bloqueo de acceso público y el resto de las opciones por defecto para empezar, a menos que tengas requisitos de seguridad específicos. Finalmente, haz clic en "Crear bucket" para completar el proceso.
En el script ETL es necesario modificar la línea donde se guarda el DataFrame para que apunte al bucket de Amazon S3. Esto se logra reemplazando la ruta local por df.to_csv('s3://airflow-bucket-twitter-datos/refined_tweets.csv', index=False), lo cual permite que los datos procesados se almacenen directamente en el bucket especificado.
En una terminal separada, necesitarás establecer una nueva conexión SSH a tu instancia EC2. Una vez que hayas accedido exitosamente a la instancia, el siguiente paso es navegar hasta el directorio de Airflow, que es donde se almacenan y gestionan los DAGs de tu proyecto.
Ahora, dentro del directorio
Después de realizar esos cambios, es necesario detener y reiniciar los servicios de Airflow para que detecte las nuevas configuraciones. Y luego, vuelve a ejecutar los comandos
Asegúrate de detener cualquier proceso que esté ocupando el puerto antes de iniciar el scheduler.
Cuidado: reset elimina todo lo que tengas en la base de datos de Airflow (DAGs ejecutados, conexiones, variables, etc.).
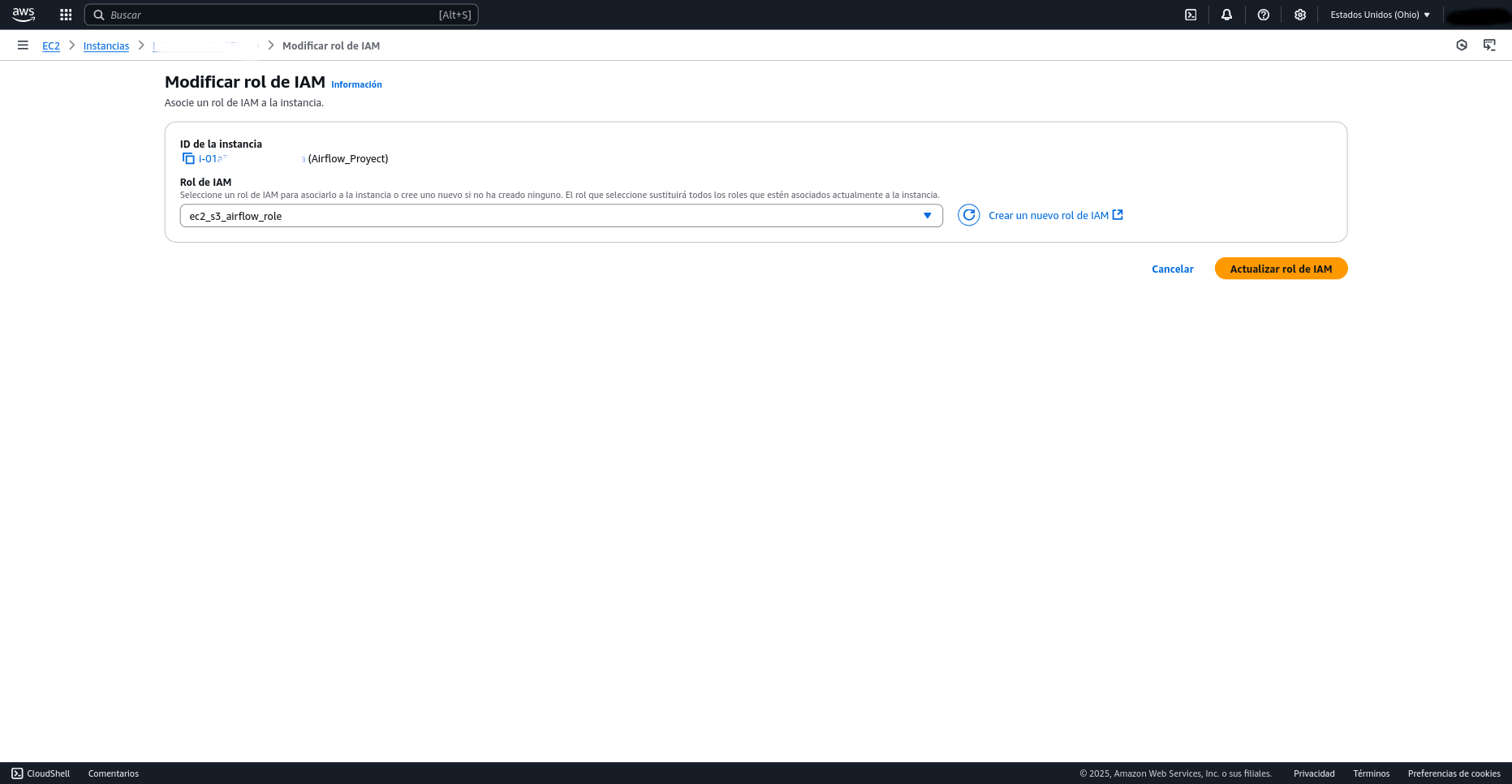
Para otorgar permisos de escritura a tu bucket S3, ve a la sección de Instancias en la consola de AWS. Arriba, en el menú desplegable de "Acciones" (Actions), selecciona "Seguridad" (Security) y luego "Modificar rol de IAM" (Modify IAM role). Aquí, crea un nuevo rol de IAM, asignándolo al servicio EC2 para permitirle interactuar con otros servicios de AWS. A continuación, busca y adjunta las políticas AmazonS3FullAccess y AmazonEC2FullAccess (esta última es opcional para el contexto de S3, pero útil para gestión de EC2). Finalmente, nombra el rol ec2_s3_airflow_role. Tras refrescar la página, el nuevo rol debería aparecer y estar listo para ser asociado a tu instancia.
Fue imposible hacer que los DAGs corrieran en la interfaz web usando la instancia gratuita de AWS EC2. Aunque se intentó especificar y reiniciar rutas alternativas en el archivo de configuración, Airflow simplemente no detectaba los DAGs al iniciar el scheduler y la interfaz web por separado. El modo standalone de Airflow, que podría haber sido una solución, tampoco funcionó debido a la limitación de recursos de la instancia gratuita. Sin embargo, al ejecutar todo el proceso de forma manual, el flujo completo se completó sin errores, lo que sugiere que el problema reside en la capacidad de la instancia para gestionar simultáneamente todos los servicios de Airflow necesarios para la detección automática de DAGs.
En una instancia con más recursos, el modo standalone de Airflow debería ejecutarse sin ningún problema.