ELK Stack
ELK Stack es un conjunto de herramientas de código abierto diseñado para la recolección, análisis y visualización de datos en tiempo real. Su nombre proviene de las iniciales de sus tres componentes principales: Elasticsearch, Logstash y Kibana. Este conjunto de herramientas es ampliamente utilizado en el monitoreo de sistemas, análisis de registros (logs) y seguridad informática.
Con la creciente cantidad de datos generados por sistemas modernos, la necesidad de soluciones eficientes para procesar, indexar y visualizar estos datos ha llevado a ELK Stack a convertirse en una de las alternativas preferidas frente a otras herramientas.
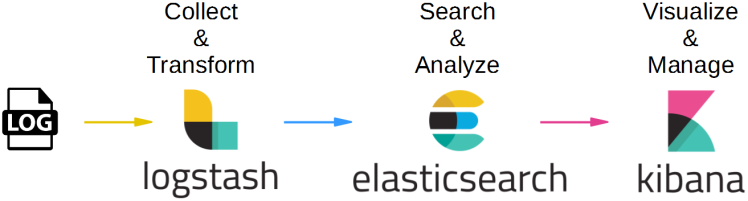
Componentes de ELK Stack
- ⌬
Elasticsearch: Es el motor de búsqueda y análisis que sirve como base del stack. Elasticsearch está diseñado para almacenar grandes volúmenes de datos y proporcionar búsquedas rápidas y eficientes. Utiliza un modelo de almacenamiento basado en documentos JSON y es altamente escalable gracias a su arquitectura distribuida. - ⌬
Logstash: Es la herramienta encargada de la ingesta, transformación y carga de datos. Logstash permite recolectar datos desde diversas fuentes, como archivos de registros, bases de datos y colas de mensajes, y procesarlos para normalizarlos antes de enviarlos a Elasticsearch. - ⌬
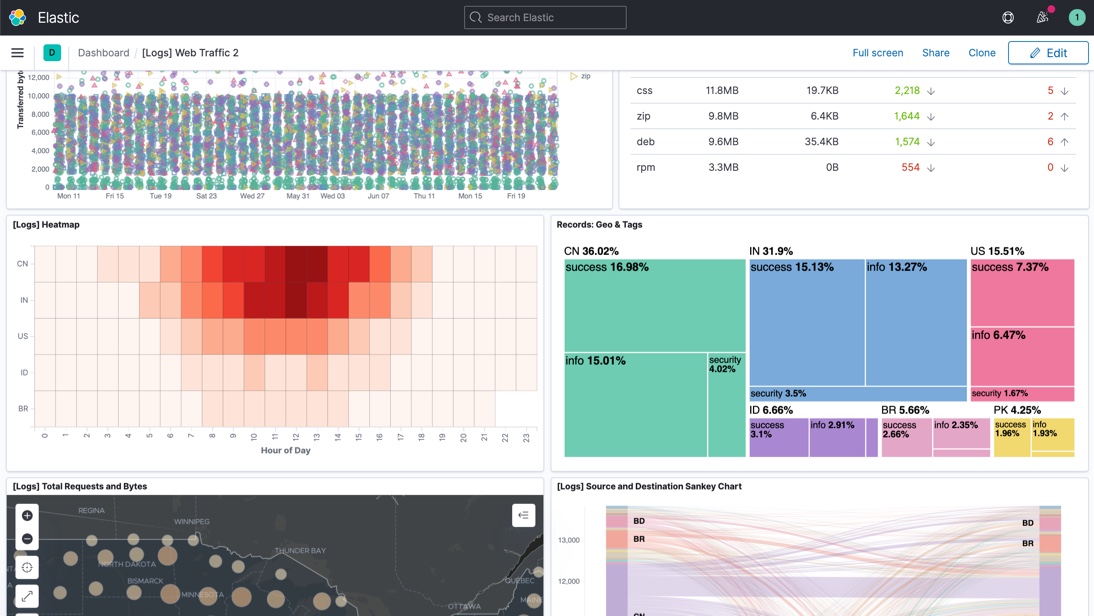
Kibana: Es la interfaz de visualización de datos. Permite crear dashboards interactivos, realizar búsquedas avanzadas y analizar tendencias a través de gráficos, mapas y otras herramientas visuales.
Adicionalmente, se puede integrar Beats, una colección de agentes ligeros diseñados para enviar datos desde los servidores a Logstash o directamente a Elasticsearch.
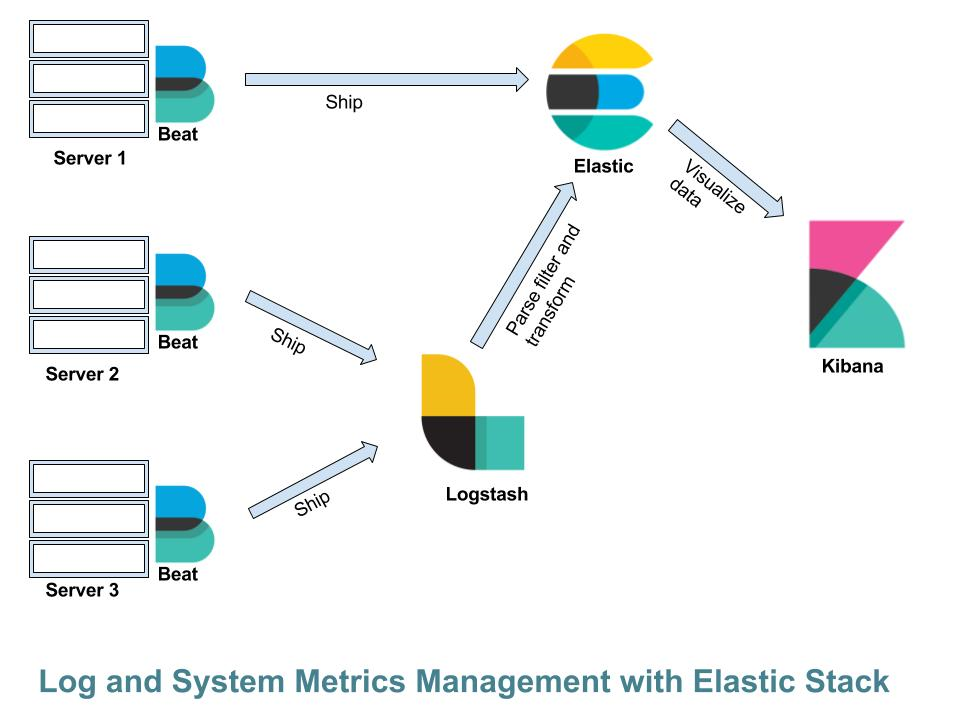
Funcionamiento de ELK Stack
El flujo de datos dentro de ELK Stack puede describirse en los siguientes pasos:
Recolecta de datos: Logstash (o Beats) recopila datos desde fuentes como archivos de logs, bases de datos, APIs o eventos de red.Procesamiento y transformación: Logstash aplica filtros y transforma los datos para estructurarlos correctamente antes de enviarlos a Elasticsearch.Indexación y almacenamiento: Elasticsearch recibe los datos procesados y los almacena en su índice distribuido, permitiendo consultas rápidas y eficientes.Análisis y visualización: Kibana se conecta a Elasticsearch para proporcionar dashboards y herramientas de visualización interactivas.

Ventajas frente a otras alternativas
Open Source: A diferencia de otras soluciones comerciales como Splunk, ELK Stack es de código abierto, lo que significa que puede ser implementado sin costos de licencia y con acceso a una comunidad activa de desarrolladores.Escalabilidad y Flexibilidad: Elasticsearch permite escalar horizontalmente agregando nuevos nodos al clúster, lo que facilita la gestión de grandes volúmenes de datos sin comprometer el rendimiento.Integración: ELK Stack puede integrarse con plataformas cloud, bases de datos, herramientas de automatización y servicios de mensajería, lo que lo hace altamente adaptable a distintas necesidades empresariales.Personalización y Análisis Avanzado: Kibana permite la creación de dashboards altamente personalizados con alertas, paneles de control interactivos y compatibilidad con Machine Learning para análisis predictivos.
Elasticsearch
Instalación
❏ Puedes instalar Elasticsearch desde los repositorios de Elastic.
❏ Configurar Elasticsearch para un único nodo.
ryuzak1@ubuntu: ~
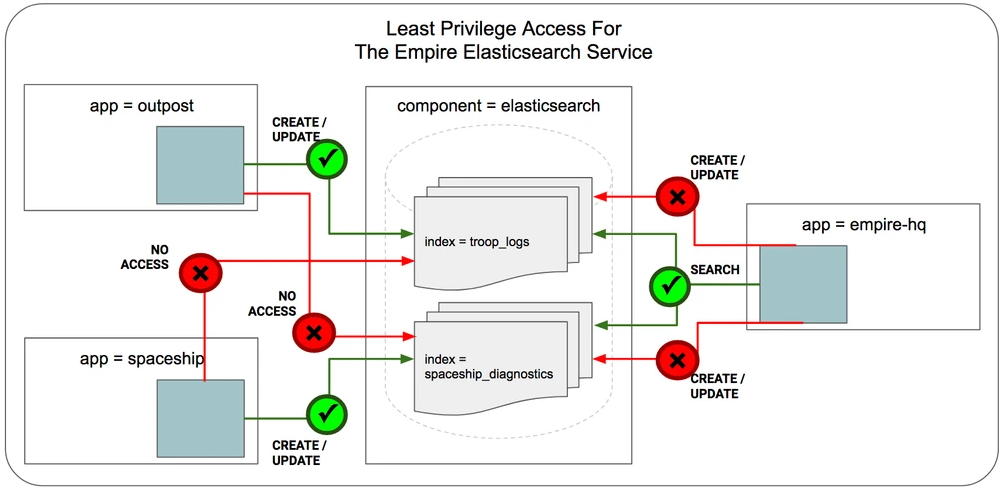
Desactivar la seguridad en Elasticsearch puede ser útil en entornos de pruebas locales o aislados, pero no es recomendable en entornos de producción o accesibles desde Internet. Si decides desactivarla, asegúrate de restringir el acceso a Elasticsearch y de volver a habilitar la seguridad una vez que termines las pruebas.
Desactivar la seguridad en Elasticsearch tiene las siguientes implicaciones:
- Cualquier persona con acceso a la red donde está corriendo Elasticsearch podrá acceder a los datos sin necesidad de autenticarse.
- Las comunicaciones entre los nodos de Elasticsearch y entre Elasticsearch y los clientes no estarán cifradas.
- No habrá restricciones basadas en roles o permisos. Todos los usuarios tendrán acceso completo a los índices y datos.
Si necesitas cambiar el puerto predeterminado, debes editar el archivo de configuración de Elasticsearch.
Busca la línea "http.port: 9200" y reemplaza 9200 por el puerto que desees utilizar.
❏ Cambiar la cantidad de memoria utilizada.
❏ Habilitar y arrancar Elasticsearch.
❏ Verificar que Elasticsearch está corriendo.
ryuzak1@ubuntu: ~
Usa curl para verificar que el servicio está activo:
ryuzak1@ubuntu: ~
Uso Básico de Elasticsearch
Elasticsearch es un motor de búsqueda basado en documentos que almacena datos en formato JSON. Se organiza en índices, que contienen documentos, los cuales tienen campos con valores estructurados o no estructurados.
Antes de agregar documentos, debes definir un índice. Si no lo defines, Elasticsearch lo creará automáticamente cuando insertes el primer documento.
❏ Para crear un índice:
ryuzak1@ubuntu: ~
- ⌭
number_of_shards: Número de fragmentos en los que se divide el índice. - ⌭
number_of_replicas: Número de copias de seguridad de los datos.
Los documentos se almacenan en JSON dentro de un índice. Puedes insertar un documento usando POST o PUT.
❏ Ejemplo de agregar un documento con POST:
ryuzak1@ubuntu: ~
❏ Esto creará un documento con un ID autogenerado. Si quieres asignar un ID específico, usa PUT:
ryuzak1@ubuntu: ~
❏ Para recuperar un documento específico por su ID:
ryuzak1@ubuntu: ~
❏ Cuando se necesita buscar un usuario por nombre sin conocer su ID, se puede usar una consulta como esta que filtra por el campo nombre, en este caso buscando todos los documentos que contengan el valor "Ana" dentro del índice test.
ryuzak1@ubuntu: ~
❏ Puedes buscar documentos que cumplan ciertos criterios usando _search:
ryuzak1@ubuntu: ~
❏ Para actualizar un campo de un documento sin reemplazarlo por completo, usa _update:
ryuzak1@ubuntu: ~
❏ Si quieres borrar un documento por su ID:
ryuzak1@ubuntu: ~
Esto elimina el documento con ID 1 del índice test.
❏ Puedes obtener solo una parte de los resultados con size y from:
ryuzak1@ubuntu: ~
Esto devuelve 3 documentos empezando desde el número 2.
❏ Para ordenar los resultados por la edad de menor a mayor:
ryuzak1@ubuntu: ~
❏ Para buscar documentos donde "edad" esté entre 25 y 28 años:
ryuzak1@ubuntu: ~
Formatos de Datos en Elasticsearch
Elasticsearch acepta documentos en JSON, y dentro de cada documento puedes usar los siguientes tipos de datos:
Texto (text, keyword): Para almacenar cadenas de caracteres.Números (integer, float, double, long, short): Para datos numéricos.Booleanos (boolean): Para true o false.Fechas (date): Formatos como YYYY-MM-DD.Objetos (object): Datos anidados dentro de un documento.Geo (geo_point, geo_shape): Para almacenar ubicaciones geográficas.
Ejemplo de un documento con varios tipos de datos:
Logstash
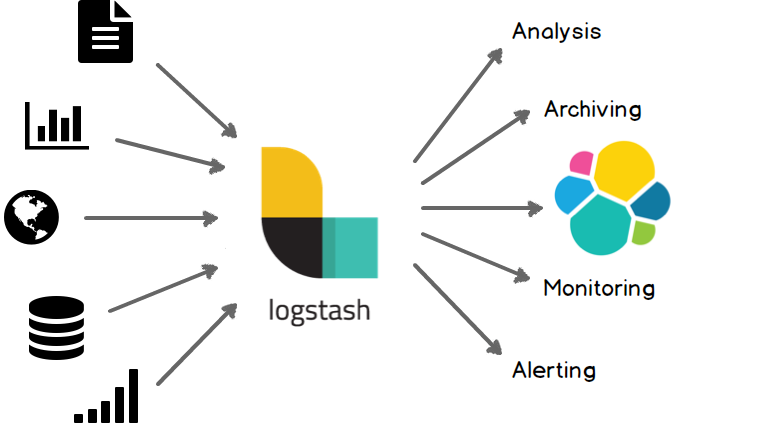
Logstash es un motor de procesamiento de datos en tiempo real que puede ingerir, enriquecer, transformar y transportar datos desde una variedad de fuentes a diversos destinos. En su esencia, Logstash actúa como un pipeline de datos flexible y extensible.
Logstash destaca en la ingesta de datos de fuentes dispares, como archivos de registro, bases de datos, colas de mensajes y servicios web. Una vez ingeridos, los datos pueden ser enriquecidos con información adicional, como geolocalización de direcciones IP o resolución de nombres de dominio. Logstash también ofrece capacidades de filtrado condicional y de control de flujo, lo que permite enrutar los datos a diferentes destinos o realizar acciones específicas según su contenido.
Logstash usa archivos de configuración .conf con tres secciones principales:
- ▱
input: Define la fuente de los datos (archivos, bases de datos, syslog, Kafka, etc.). - ▱
filter: Aplica transformaciones a los datos (parseo, eliminación, enriquecimiento, etc.). - ▱
output: Define el destino de los datos (Elasticsearch, bases de datos, archivos, etc.).
Logstash ofrece una amplia gama de filtros que permiten transformar y enriquecer tus datos antes de enviarlos a tu destino (generalmente Elasticsearch). Aquí te presento los tipos de filtros más comunes y útiles:
- Filtros de Análisis y Extracción de Datos:
- ⌭
grok: Este es uno de los filtros más poderosos. Permite analizar y extraer campos específicos de cadenas de texto no estructuradas utilizando patrones predefinidos o personalizados. - ⌭
dissect: Similar a Grok, pero más rápido para datos estructurados con delimitadores consistentes. - ⌭
csv: Analiza datos en formato CSV y los convierte en campos individuales. - ⌭
json: Analiza datos en formato JSON y los convierte en campos estructurados. - ⌭
xml: Analiza datos en formato XML y los convierte en campos estructurados. - ⌭
kv: Analiza pares clave-valor en cadenas de texto y los convierte en campos individuales. - Filtros de Transformación y Enriquecimiento de Datos:
- ⌭
mutate: Permite realizar diversas transformaciones en los campos, como renombrar campos, eliminar campos, reemplazar valores, dividir cadenas y convertir tipos de datos. - ⌭
date: Analiza cadenas de texto que representan fechas y las convierte en objetos de fecha y hora. - ⌭
geoip: Enriquece los eventos con información geográfica basada en direcciones IP. - ⌭
dns: Realiza búsquedas de DNS inversas para obtener nombres de host a partir de direcciones IP. - ⌭
ruby: Permite ejecutar código Ruby para realizar transformaciones personalizadas complejas. - Filtros Condicionales y de Control de Flujo:
- ⌭
if/else: Permite aplicar filtros condicionalmente según ciertas condiciones. - ⌭
drop: Descarta eventos que no cumplen con ciertos criterios. - ⌭
clone: Duplica eventos para procesarlos de diferentes maneras. - ⌭
aggregate: Combina múltiples eventos en un solo evento. - Filtros de Codificación y Decodificación:
- ⌭
urldecode: Decodifica cadenas de texto codificadas en formato URL. - ⌭
base64: Codifica o decodifica datos en formato Base64.
Es ideal para procesar registros de logs con formatos variados.
Útil para procesar registros CSV o datos con patrones predecibles.
Esencial para trabajar con datos basados en tiempo.
Permite obtener la ubicación, el país y otros detalles geográficos.
Esencial para crear pipelines de procesamiento de datos flexibles.
Útil para filtrar datos no deseados.
Instalación
❏ Puedes descargar Logstash para Windows desde la web oficial de Elastic.
Para probar que Logstash esté en funcionamiento, se puede crear un archivo con el siguiente contenido. Esto permitirá verificar la entrada estándar de la terminal de Linux y reportar todo por la salida estándar, utilizando
Uso Básico de Logstash
❏ Generar Tráfico de Registro:
- ⌭
Autenticación (auth.log): Intenta iniciar sesión con un nombre de usuario incorrecto:sudo su - usuario_incorrecto (esto generará un intento de autenticación fallido). - ⌭
Cron (cron.log): Añade una tarea cron sencilla que se ejecute en el próximo minuto:(crontab -l ; echo "* * * * * echo 'Prueba Cron' >> /tmp/cron_test.log") | crontab - (esto generará una entrada encron.log cuando la tarea se ejecute). - ⌭
Kernel (kern.log): Conecta o desconecta un dispositivo USB. - ⌭
Syslog (syslog): Usa el comando logger para enviar mensajes directamente a syslog:logger "Mensaje de prueba syslog" . - ⌭
Mail (mail.log): Si tienes un servidor de correo configurado, envía o recibe un correo electrónico.
O intenta usar
Si deseas que la tarea deje de ejecutarse, debes eliminarla del crontab. Para hacerlo, sigue estos pasos: primero, abre el crontab en modo edición ejecutando
Puedes intentar cargar o descargar un módulo del kernel (con precaución):
❏ Crear un Archivo de Configuración Básico.
Y agrega lo siguiente:
input: Se define como fuente el archivo/var/log/syslog .filter: Usa grok para extraer campos estructurados del log.output: Envía los datos a un índice en Elasticsearch llamado logs-syslog y los muestra en la terminal (stdout).
Para ciertos registros, también se pueden visualizar en rutas como
❏ Ejecutar Logstash con el Archivo de Configuración.
❏ Ejecutar Logstash para Data Streams.
Logstash puede crear un índice para Data Streams en Elasticsearch, lo cual es común si has habilitado ILM (Index Lifecycle Management) o Data Streams en tu configuración.
Un Data Stream es una abstracción en Elasticsearch que permite manejar índices basados en el tiempo (time-series) de manera más eficiente.
Para configurar un data stream en Logstash, necesitarás configurar un pipeline de Logstash que pueda consumir datos desde una fuente (como un archivo, un servidor de base de datos o un servicio) y luego enviarlos a un destino (como Elasticsearch).
Para esto es necesario específicarlo en el output del archivo de configuración de Logstash:
Filtrado de datos con Logstash
Logstash permite filtrar y transformar datos de diversas maneras. Aquí te muestro un ejemplo:
❏ Configuración de un Pipeline de Logstash.
Para crear un pipeline de Logstash que filtre y transforme datos, puedes usar la siguiente configuración:
Después puedes probar que esté capturando correctamente los registros ejecutando comandos como superusuario, como podrían ser
Ejemplos de Configuración de Logstash
❏ Leer Datos desde Diferentes Fuentes.
- Leer desde un Archivo
- Leer desde Syslog en Tiempo Real
- Recibir Datos desde HTTP (API REST)
Si tienes un archivo de logs llamado
sincedb_path => "/dev/null" hace que siempre lea el archivo desde el inicio.
Si quieres procesar logs del sistema:
Esto captura logs enviados a través de syslog en el puerto 5514.
Si una aplicación quiere enviar datos a Logstash mediante HTTP POST:
❏ Procesamiento Avanzado con Filtros
- Uso de GROK para Extraer Datos
- Convertir Formato de Fechas
- Convertir Datos a Minúsculas o Mayúsculas
- Ve a Stack Management → Data Views → Create data view.
- Escribes el nombre del índice que cargaste (ej: logs-*, ventas, etc).
- Y ¡listo! Ya puedes visualizarlo desde Discover.
- Para definir una "Regla" (Rule) que evalúe condiciones y dispare alertas en Kibana, navega a Alerts → Manage Rules, que es la sección designada para esta configuración, y luego haz clic en el botón "Create rule" para comenzar el proceso de creación.
- Para monitorear datos directamente desde Elasticsearch, como los documentos que visualizas en Discover, debes elegir la opción "Elasticsearch Query".
- En esta sección, debes escribir la query en KQL (Kibana Query Language). Si lo que te interesa es detectar cuando aparece host.name: "Ubuntu"
- También puedes definir una nueva alerta con condiciones específicas (por ejemplo, si un servidor está caído).
- Configura las acciones: Enviar un email, webhook o Slack notification.
- Buscar errores en logs:
message: "error" - Filtrar registros de usuarios de México:
country: "Mexico" - Ve a Stack Management → Data Views → Create data view.
- Crea un patrón de índice para logs*.
- Visualiza los datos en "Discover".
Si tienes logs en texto sin formato y necesitas estructurarlos:
Esto estructura logs de Apache automáticamente.
Si un campo llamado timestamp tiene un formato incorrecto:
Ajusta fechas al formato estándar de Elasticsearch.
Esto convierte Usuario a usuario.
❏ Enviar Datos a Múltiples Destinos.
Puedes enviar los datos a Elasticsearch, un archivo y stdout al mismo tiempo:
Esto almacena los logs en Elasticsearch, los guarda en un archivo y los imprime en la consola.
❏ Verificar Errores en Logstash.
Kibana
Instalación
❏ Puedes descargar Kibana para Windows desde la web oficial de Elastic.
❏ Configurar Kibana.
ryuzak1@ubuntu: ~
Accede en un navegador a: http://localhost:5601 y luego haz clic en el botón "Explore on my own" para acceder a la interfaz principal de Kibana y empezar a explorar.
Importar Datos en Kibana.
Desde Elasticsearch:
Alertas y Monitorización en Kibana.
Si quieres recibir alertas cuando los datos cumplan ciertas condiciones:
Uso Básico de Kibana
❏ Buscar y Filtrar Datos en Kibana.
Puedes buscar datos en tiempo real usando KQL (Kibana Query Language).
Ejemplo:
❏ Conectar Kibana con Logstash y Elasticsearch.
Si Logstash envía datos a Elasticsearch, Kibana puede visualizarlos.
Ejemplo de configuración en
Luego, en Kibana: