Apache Kafka
Apache Kafka es una plataforma de mensajería distribuida diseñada para manejar grandes volúmenes de datos en tiempo real. Originalmente desarrollado por LinkedIn y posteriormente donado a la Apache Software Foundation, Kafka se ha convertido en una solución ampliamente adoptada para la transmisión de datos en entornos distribuidos.
Este sistema se basa en el concepto de "publicar y suscribirse" (publish-subscribe) y permite que los sistemas intercambien datos de manera confiable, eficiente y escalable. Su arquitectura distribuida lo hace ideal para aplicaciones que requieren alta disponibilidad y tolerancia a fallos.
Kafka es un sistema diseñado para procesar flujos de eventos en tiempo real. Esto significa que está optimizado para capturar y responder a sucesos que ocurren de manera continua. Los "productores" envían estos eventos a Kafka, organizándolos en "topics" (temas) que actúan como canales de datos.
Los "brokers" de Kafka almacenan estos eventos de forma duradera y los distribuyen a los "consumidores". Estos consumidores son aplicaciones que procesan los eventos a medida que llegan, permitiendo reacciones casi instantáneas. La capacidad de Kafka para manejar grandes volúmenes de datos y su arquitectura distribuida aseguran que estas reacciones ocurran de manera eficiente y escalable.

¿Para qué sirve Apache Kafka?
Apache Kafka se utiliza para la ingesta y procesamiento de grandes cantidades de datos en tiempo real. Su funcionalidad es útil en diversos escenarios, tales como:
- 🔸
Procesamiento de eventos en tiempo real: Empresas que necesitan analizar datos al instante, como plataformas de redes sociales, comercio electrónico y sistemas de detección de fraudes. - 🔸
Monitoreo de logs y métricas: Kafka facilita la recolección y análisis de registros y métricas en sistemas distribuidos. - 🔸
Integración de sistemas: Permite la comunicación entre distintos servicios y aplicaciones a través de su sistema de eventos. - 🔸
Procesamiento de flujos de datos: Gracias a Kafka Streams, se pueden procesar datos en tiempo real con baja latencia. - 🔸
Mensajería escalable: Sirve como alternativa a sistemas de mensajería tradicionales como RabbitMQ o ActiveMQ, pero con una mayor capacidad de escalabilidad.
Arquitectura
Kafka está compuesto por varios elementos clave que permiten su funcionamiento:
- ▱
Producers: Los productores son la primera línea en el ecosistema de Kafka. Son aplicaciones que generan datos y los envían a Kafka. Estos datos pueden ser de cualquier tipo: registros de actividad de usuarios, datos de sensores, logs de aplicaciones, transacciones financieras, etc. - ▱
Topics: Los productores tienen la flexibilidad de elegir a qué "topic" (tema) enviar sus mensajes, lo que permite organizar los datos en categorías lógicas. - ▱
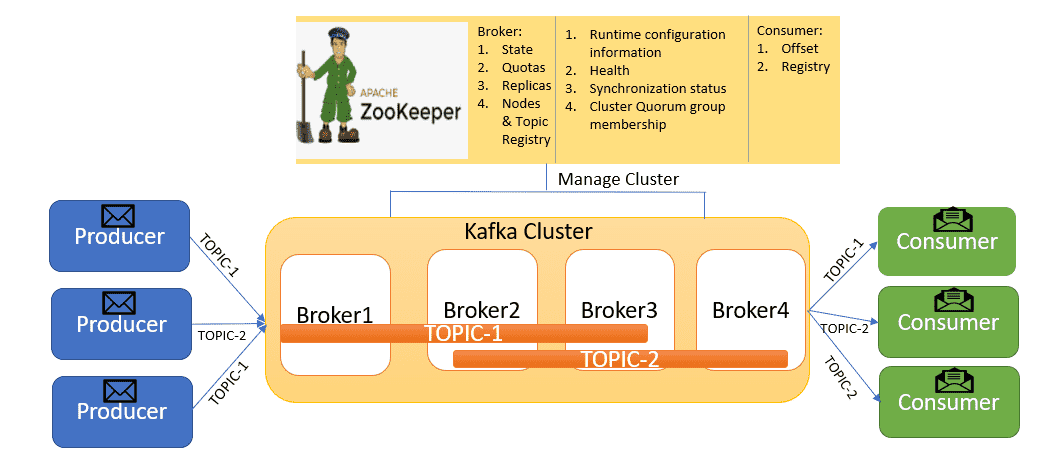
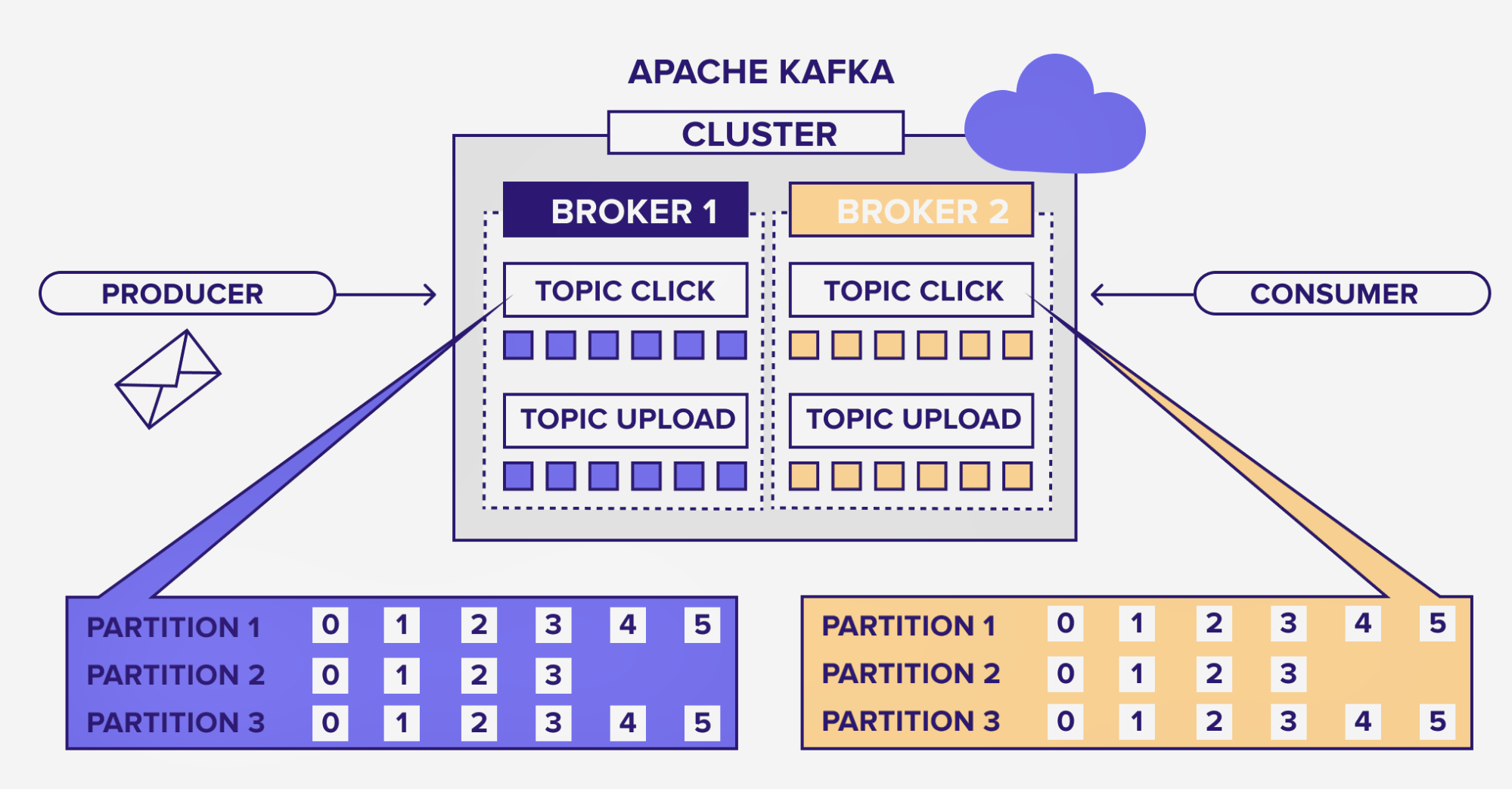
Brokers: Los brokers son los servidores que componen el clúster de Kafka. Son responsables de almacenar los mensajes y distribuirlos a los consumidores. - ▱
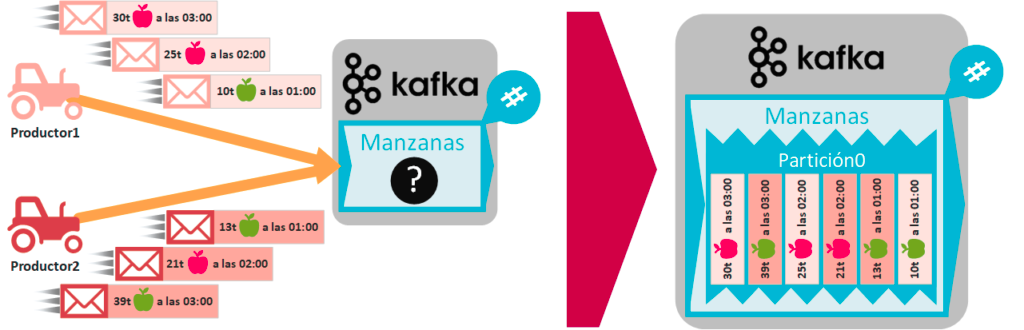
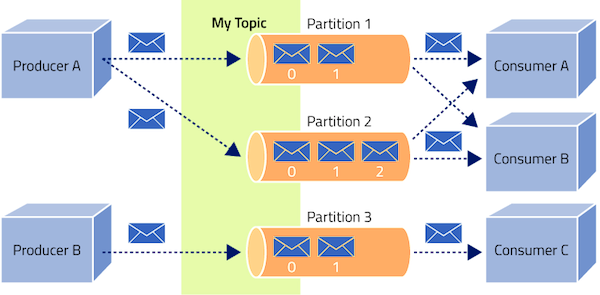
Partitions: Para mejorar la escalabilidad y el rendimiento, cada topic puede dividirse en múltiples particiones. - ▱
Consumers: Los consumidores son aplicaciones que leen los mensajes almacenados en Kafka. - ▱
Zookeeper: Zookeeper es un servicio de coordinación que se utiliza para gestionar el clúster de Kafka.
∘ La clave de los productores es su capacidad para enviar datos de forma asíncrona y a alta velocidad. Esto permite que las aplicaciones continúen funcionando sin tener que esperar a que los datos sean procesados.
∘ Los productores tienen la flexibilidad de elegir a qué "topic" (tema) enviar sus mensajes, lo que permite organizar los datos en categorías lógicas.
∘ Cada mensaje enviado a Kafka debe pertenecer a un topic. Por ejemplo, podrías tener un topic para "logs de usuarios", otro para "transacciones de ventas" y otro para "datos de sensores".
∘ Los topics permiten que diferentes aplicaciones (productores y consumidores) interactúen con flujos de datos específicos.
∘ Un clúster de Kafka puede estar compuesto por múltiples brokers, lo que proporciona alta disponibilidad y tolerancia a fallos.
∘ Cuando un productor envía un mensaje, este se almacena en uno o varios brokers, dependiendo de la configuración del topic.
∘ Los brokers son los responsables de la persistencia de los datos, guardando los mensajes en el disco. Esto asegura que los datos no se pierdan, incluso en caso de fallos del sistema.
∘ Cada partición es una secuencia ordenada de mensajes, y cada mensaje dentro de una partición tiene un offset único.
∘ Las particiones permiten distribuir la carga de trabajo entre múltiples brokers, lo que aumenta el rendimiento y la capacidad de procesamiento de Kafka.
∘ Además, las particiones permiten que múltiples consumidores procesen los mensajes en paralelo, lo que acelera el procesamiento de datos.
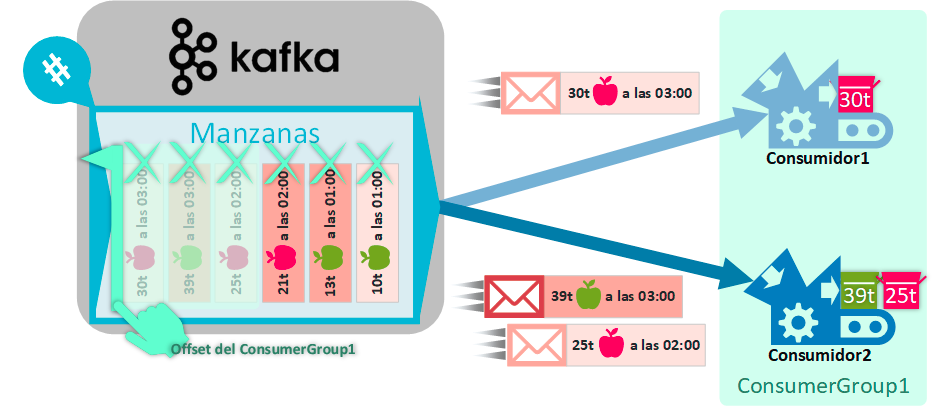
∘ Los consumidores se suscriben a uno o varios topics y procesan los mensajes a medida que llegan.
∘ Kafka permite que múltiples consumidores trabajen en paralelo para procesar los mensajes de un topic. Esto se logra mediante la asignación de particiones a los consumidores.
∘ Los consumidores pueden agruparse en grupos de consumidores (consumer groups), lo que permite distribuir la carga de trabajo y asegurar que cada mensaje sea procesado una sola vez dentro de un grupo.
∘ Zookeeper se encarga de mantener la información de configuración del clúster, como la lista de brokers, los topics y las particiones.
∘ También se encarga de la elección del líder de las particiones, que es el broker responsable de recibir las escrituras de los productores.
∘ Zookeeper es crucial para la estabilidad y la fiabilidad de Kafka, ya que garantiza que todos los componentes del clúster estén sincronizados.
Tecnologías Compatibles
Kafka es compatible con diversas tecnologías y frameworks, lo que lo hace una opción versátil en arquitecturas modernas:
Bases de Datos: Puede integrarse con bases de datos relacionales (MySQL, PostgreSQL) y NoSQL (MongoDB, Cassandra).Sistemas de Big Data: Funciona con Apache Spark, Hadoop, y Flink para el procesamiento de datos a gran escala.Lenguajes de Programación: Ofrece soporte para Java, Python, Scala, Go, y más.Sistemas de Mensajería: Puede complementar o reemplazar soluciones como RabbitMQ y ActiveMQ.Servicios en la Nube: Se puede implementar en AWS, Azure y Google Cloud Platform.
Flujo de Apache Kafka
Imagina una plataforma de comercio electrónico en tiempo real. Cada vez que un usuario realiza una compra, se genera un evento. Este evento, que contiene detalles como el ID del producto, el precio, la ubicación del usuario y la hora de la compra, es producido por una aplicación (el productor) y enviado a un topic de Kafka llamado "compras". Este topic está dividido en varias particiones para manejar el alto volumen de transacciones.
Los brokers de Kafka, que forman un clúster, reciben estos eventos y los almacenan de forma duradera en las particiones del topic "compras". Como el topic está particionado, los eventos se distribuyen entre múltiples brokers, lo que permite manejar una gran cantidad de datos y asegurar la disponibilidad. Zookeeper se encarga de coordinar el clúster, asegurando que todos los brokers estén sincronizados y que las particiones tengan líderes designados.
Ahora, imagina que el equipo de análisis de datos necesita procesar estas compras en tiempo real para generar informes y detectar anomalías. Tienen una aplicación (el consumidor) que se suscribe al topic "compras". El consumidor lee los eventos de las particiones y los procesa. Como el topic está particionado, pueden tener múltiples instancias del consumidor trabajando en paralelo, cada una procesando una o varias particiones. Esto permite un procesamiento en tiempo real y escalable de los datos de compra.
Además, el equipo de marketing tiene otra aplicación (otro consumidor) que también se suscribe al topic "compras". Esta aplicación utiliza los datos de compra para personalizar las recomendaciones de productos para los usuarios. Como tienen su propio grupo de consumidores, pueden procesar los mismos eventos de compra sin interferir con el trabajo del equipo de análisis de datos.
En resumen, Kafka actúa como un sistema de mensajería centralizado y escalable que permite la transmisión y el procesamiento de datos en tiempo real. Los productores generan eventos, los brokers los almacenan y los consumidores los procesan, todo ello coordinado por Zookeeper.
Configuración
Para instalar y configurar Kafka, se requieren algunos pasos básicos:
Para instalar Apache Kafka en Linux, necesitas descargar los archivos binarios directamente desde el sitio web oficial de Apache Kafka.
El directorio /tmp está diseñado para archivos temporales. Los sistemas Linux suelen limpiar este directorio periódicamente, especialmente al reiniciar. Esto significa que los datos de Zookeeper podrían perderse, lo que podría provocar la corrupción de los datos de Kafka.
Para un entorno de producción crea un directorio dedicado para los datos de Zookeeper en una ubicación persistente, como /var/lib/zookeeper o un directorio dentro de tu directorio de inicio (/home/$USER/zookeeper).
Edita el archivo config/zookeeper.properties y modifica "dataDir=/var/lib/zookeeper" para que apunten a tu directorio dedicado:
Nota: dar permisos 777 es muy permisivo, para un entorno de producción, se recomienda configurar permisos mas restrictivos.
❏ Crear un Topic en Kafka:
ryuzak1@ubuntu: ~
- ⌭
topic mi-topic: Nombre del topic a crear. - ⌭
partitions 3: Número de particiones del topic. - ⌭
replication-factor 2: Número de réplicas del topic para tolerancia a fallos.
❏ Enviar Mensajes:
ryuzak1@ubuntu: ~
❏ Leer Mensajes:
ryuzak1@ubuntu: ~
Para permitir conexiones remotas, edita el archivo config/server.properties:
En el host remoto, usa la IP del servidor para conectarte.
Cluster de Apache Kafka
Crear un clúster de Apache Kafka con Docker es una excelente manera de experimentar y desarrollar con Kafka de forma rápida y sencilla. Aquí te explico cómo puedes hacerlo, junto con algunas consideraciones importantes:
Es necesario crear 3 contenedores en diferentes terminales, para cada uno de los nodos del cluster.
❏ Configurar Zookeeper en el nodo 1.
ryuzak1@ubuntu: ~
❏ Configurar el nodo 2:
ryuzak1@ubuntu: ~
- ⌭
broker.id: Este es el identificador único del broker de Kafka. Cada broker en un clúster debe tener un broker.id diferente. - ⌭
listeners: Define las direcciones y puertos en los que el broker de Kafka escuchará las conexiones de los clientes y otros brokers (es la IP del contenedor en sí). - ⌭
log.dirs: Especifica el directorio o directorios donde Kafka almacenará los archivos de registro (logs) de los mensajes. - ⌭
zookeeper.connect: Define la cadena de conexión para el clúster de Zookeeper.
❏ Configurar el nodo 3:
ryuzak1@ubuntu: ~
Con la configuración actual, la interacción con el clúster de Kafka resulta flexible, permitiendo realizar peticiones tanto desde el sistema anfitrión como directamente desde cualquiera de los contenedores; la clave reside en especificar correctamente la dirección del host al que se dirige la solicitud, ya sea un nodo worker o master.
❏ Crear un Topic en el cluster Kafka:
ryuzak1@ubuntu: ~
❏ Listar los Topics en el cluster Kafka:
ryuzak1@ubuntu: ~
❏ Enviar Mensajes:
ryuzak1@ubuntu: ~
❏ Leer Mensajes:
ryuzak1@ubuntu: ~
Las peticiones al clúster de Kafka se pueden llevar a cabo desde la máquina anfitriona o desde los contenedores. Solo es necesario conectarse al productor o al consumidor, asegurándose de apuntar a la IP de algún contenedor que tenga Kafka iniciado.