



Kubernetes
Kubernetes es un sistema de orquestación de contenedores de código abierto que permite automatizar el despliegue, la administración y la escalabilidad de aplicaciones en contenedores. Desarrollado inicialmente por Google, Kubernetes es ahora mantenido por la Cloud Native Computing Foundation (CNCF). Gracias a su versatilidad y capacidad de escalabilidad, Kubernetes se ha convertido en un pilar fundamental en la adopción de arquitecturas modernas de microservicios, permitiendo que las aplicaciones sean más resistentes y fácilmente escalables.
Características
Escalabilidad Automática: Kubernetes permite escalar las aplicaciones de manera automática, adaptándose al aumento o disminución de la carga de trabajo mediante el ajuste dinámico de recursos.Despliegues Rápidos y Consistentes: Facilita el despliegue de aplicaciones y actualizaciones sin interrupciones, lo que permite una integración y entrega continua.Portabilidad: Kubernetes es compatible con múltiples plataformas, desde nubes públicas hasta servidores locales, facilitando la portabilidad de aplicaciones.Recuperación Ante Fallos: Kubernetes garantiza la disponibilidad y fiabilidad de las aplicaciones mediante la reiniciación de contenedores fallidos y el reemplazo de nodos no saludables.
Archivos de Configuración
Metadata: La sección metadata de un archivo de configuración en Kubernetes contiene información descriptiva sobre el recurso, como el nombre, las etiquetas (labels), y las anotaciones. Estos datos ayudan a identificar y categorizar los recursos dentro del clúster. El camponameasigna un nombre único, ylabelspermite clasificar los recursos para organizarlos o seleccionarlos durante las operaciones de despliegue y escalado.Spec: La sección spec define las especificaciones del recurso, detallando cómo debe comportarse y sus características esenciales. En un Pod, por ejemplo,specincluye el contenedor que se desplegará, la imagen de Docker a usar, y las configuraciones de red o almacenamiento necesarias. Este campo también puede contener las directrices de réplicas, las políticas de reinicio y la configuración de puertos para aplicaciones más complejas.Status: La sección status proporciona información en tiempo real sobre el estado de un recurso. Este campo lo gestiona Kubernetes y no se incluye en los archivos de configuración que el usuario crea, ya que se actualiza automáticamente conforme cambia el estado del recurso. En el caso de un Pod,statuspuede mostrar si está en fase de ejecución, si tiene errores o si se encuentra en espera.Kind: El campo kind especifica el tipo de recurso que se desea crear, como Pod, Service, Deployment o ConfigMap. Este campo es esencial para que Kubernetes entienda qué tipo de recurso se está configurando y le asigne los controladores necesarios para su administración en el clúster.API Version: La sección apiVersion define la versión de la API de Kubernetes que se utilizará para el recurso. Es esencial seleccionar la versión correcta, ya que las versiones definen las funcionalidades disponibles y pueden variar entre tipos de recursos. Las versiones comunes incluyenv1para recursos básicos yapps/v1para controladores de aplicaciones más avanzadas.Selector: El campo selector define un criterio de selección que permite a Kubernetes identificar y asociar objetos, como pods, con otros recursos, como servicios o deployments. Este campo es crucial para asegurar que el recurso se aplique solo a los pods que cumplen con los criterios definidos, generalmente especificados mediante etiquetas (labels). Por ejemplo, un selector en un Service puede dirigir el tráfico solo a los pods que comparten la misma etiqueta app: mongo.Env: El campo env establece variables de entorno que se pasarán al contenedor en el momento de la creación. Estas variables permiten configurar el contenedor sin modificar el código dentro de la imagen y son especialmente útiles para manejar configuraciones, credenciales, y URLs que el contenedor necesita. Puedes asignar valores directamente o referenciarlos desde secretos o ConfigMaps para mayor seguridad y flexibilidad.
⌭ Ejemplo de metadata:
En este ejemplo, el nombre "my-app-pod" identifica el recurso, mientras que las etiquetas "app" y "env" lo clasifican para su administración.
⌭ Ejemplo de spec en un Pod:
Esta especificación indica el contenedor a desplegar (my-app-container), la imagen (my-app-image), y el puerto expuesto (8080).
⌭ Ejemplo de status (información generada automáticamente):
Aquí, el estado indica que el Pod está en fase "Running" y que está "Ready" para procesar solicitudes.
Pasos para Aplicar un CronJob
- Crear un archivo YAML con la configuración del CronJob. Guárdalo, por ejemplo, como
my-cronjob.yaml . - Ejecuta el comando
kubectl apply -f my-cronjob.yaml para aplicar la configuración en el clúster. - Verifica si el CronJob está ejecutándose con
kubectl get jobs --watch . Este comando permite ver las instancias de trabajo que el CronJob está creando en tiempo real. - Accede a los registros de los Pods para verificar la salida de ejecución del CronJob con el comando
kubectl logs <nombre-del-pod> .
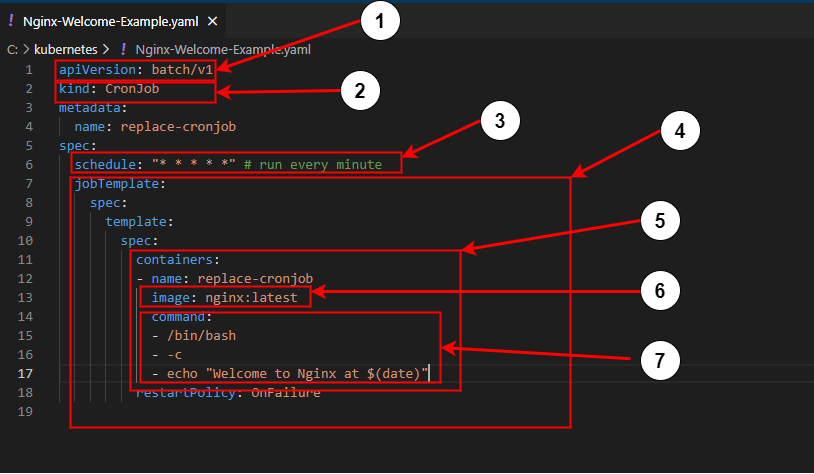
Componentes
Nodes y Pods
Node: En Kubernetes, un Node es una máquina (física o virtual) que ejecuta aplicaciones en contenedores. Cada Node forma parte del clúster de Kubernetes y contiene los recursos necesarios para ejecutar Pods. Además, en cada Node se encuentran los componentes necesarios para ejecutar Pods y comunicarse con el resto del clúster, tales como:- ▱
Kubelet: Este agente garantiza que los contenedores estén en ejecución, monitorea los Pods asignados al nodo y se comunica con el API Server para reportar el estado. - ▱
Kube-proxy: Es un proxy de red que asegura la comunicación entre los servicios y gestiona las reglas de red en el nodo. - ▱
Container Runtime: Un entorno que ejecuta los contenedores, como Docker o containerd. Pod: Un Pod es la unidad de despliegue más pequeña en Kubernetes, encapsulando uno o más contenedores que comparten almacenamiento, red y un espacio de nombres (namespace) de Linux. En casos simples, cada Pod contiene un único contenedor, pero en arquitecturas más complejas, un Pod puede agrupar contenedores que trabajan juntos (por ejemplo, una aplicación y su contenedor de monitoreo).
Los Nodes trabajan juntos bajo el control del plano de control (Control Plane) de Kubernetes, distribuyendo y gestionando las aplicaciones en el clúster.
⌭ Ejemplo de configuración de un Pod:
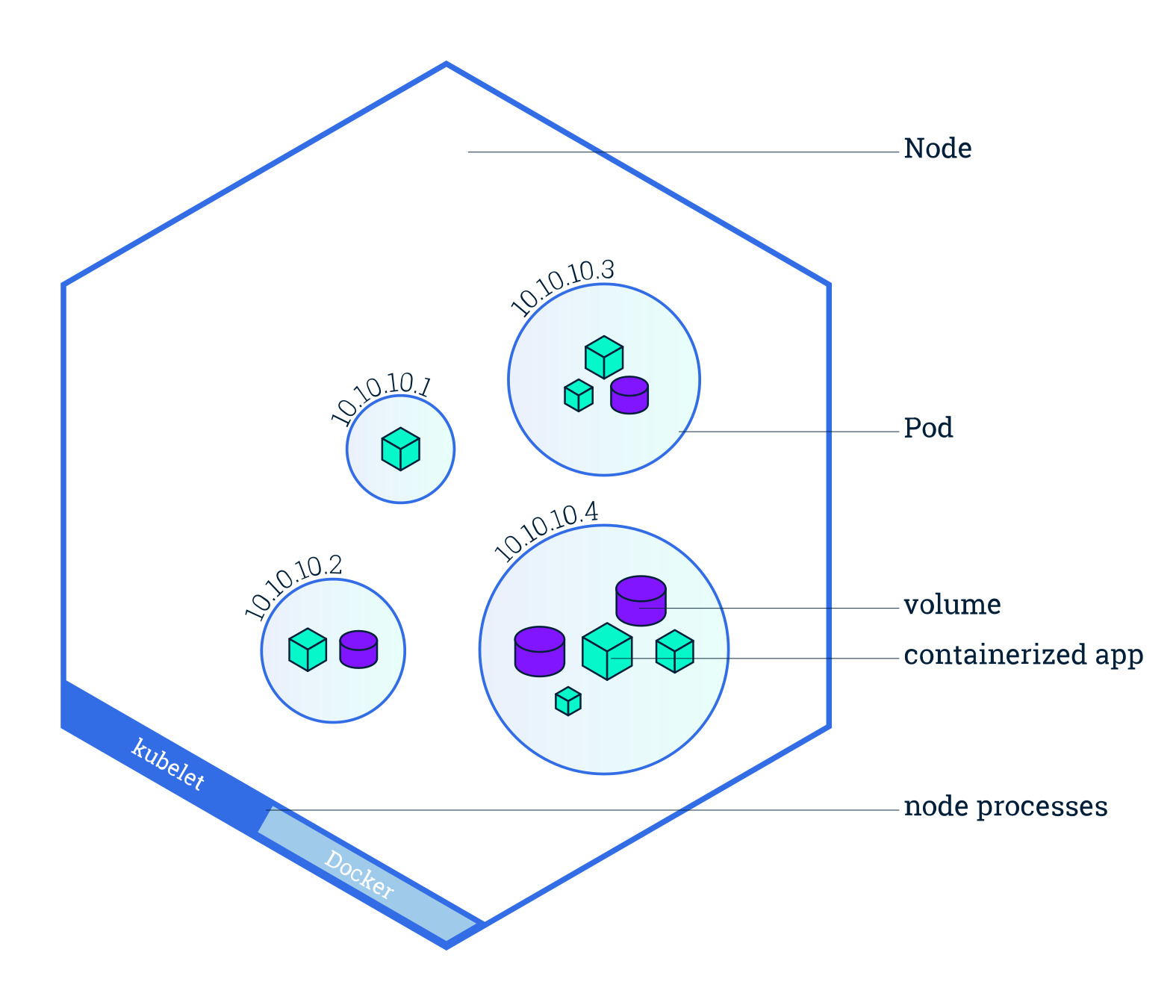
Service e Ingress
Service: Un Service es un recurso de Kubernetes que define una política de acceso para Pods, proporcionando una IP fija y un mecanismo de enrutamiento. Es útil cuando varios Pods comparten una función y necesitan ser accesibles de manera consistente, incluso si se recrean.- ▱
ClusterIP: Exposición interna dentro del clúster. - ▱
NodePort: Expone el servicio en un puerto específico en cada nodo, permitiendo el acceso externo. - ▱
LoadBalancer: Para despliegues en la nube, crea un balanceador de carga externo para el servicio. Ingress: En Kubernetes, un Ingress es un recurso que administra el acceso externo a los servicios del clúster, normalmente mediante HTTP y HTTPS, proporcionando reglas para enrutamiento de tráfico a diferentes Services en función de la ruta o el dominio solicitado. A diferencia de un Service de tipo LoadBalancer, que expone un único Service al exterior, un Ingress permite gestionar y enrutar el tráfico de forma centralizada a múltiples Services según reglas de dominio y ruta.
En Kubernetes, un Service permite definir una capa de abstracción para acceder a uno o más Pods, estableciendo una interfaz de red estable para conectarse a las aplicaciones, incluso si los Pods subyacentes se crean o eliminan. Al mantener una dirección IP y puerto constantes, un Service permite que otros componentes de la red o usuarios interactúen con el clúster sin importar los cambios en los Pods individuales.
Existen varios tipos de Service:
⌭ Ejemplo de configuración de un Service de tipo ClusterIP:
En este caso, el Service llamado my-service enruta el tráfico al puerto 8080 del Pod seleccionado.
El Ingress se conecta con uno o más Services, redirigiendo el tráfico entrante a los Pods asociados mediante estos Services. Utiliza reglas basadas en el nombre de dominio y en las rutas para determinar a qué Service y, por ende, a qué Pods dirigir el tráfico. Además, se configura con dominios en lugar de direcciones IP, lo que proporciona flexibilidad y escalabilidad en la comunicación entre aplicaciones. Dado que las IPs pueden cambiar debido al escalado o reprogramación de Pods, un dominio estático facilita la estabilidad en el enrutamiento y la disponibilidad del servicio, proporcionando un nombre de acceso constante y fácil de recordar. Por último, el Ingress ofrece balanceo de carga de capa 7 (basado en HTTP/HTTPS) y puede gestionar certificados SSL/TLS, permitiendo conexiones seguras al clúster, lo que otorga a los Ingress Controllers un mayor control y seguridad sobre el tráfico.
⌭ Ejemplo de configuración de un Ingress:
Este ejemplo define una regla de Ingress para enrutar el tráfico de example.com hacia el Service llamado my-service.
ConfigMaps y Secrets
ConfigMap: ConfigMap en Kubernetes permite almacenar configuraciones no confidenciales en forma de pares clave-valor que pueden ser utilizados por Pods y otros recursos. Esto permite separar la configuración de la aplicación del código, lo que facilita la actualización de configuraciones sin necesidad de modificar o reconstruir las imágenes de los contenedores. ConfigMap puede ser utilizado para proporcionar configuraciones de entorno, variables de configuración de aplicaciones, archivos de configuración de texto o incluso parámetros específicos que los Pods pueden leer durante su ejecución. Además, ConfigMap permite la reutilización de configuraciones a lo largo de diferentes entornos y aplicaciones, ofreciendo flexibilidad y consistencia en el manejo de configuraciones.Secret: En Kubernetes, un Secret es un recurso utilizado para almacenar información confidencial, como contraseñas, tokens o claves SSH. Los Secrets pueden configurarse como variables de entorno o montarse como archivos dentro de los contenedores. Estos permiten proteger los datos al reducir la exposición en texto plano dentro del clúster y pueden ser referenciados directamente por los Pods sin necesidad de incluir la información en las configuraciones estándar. Los datos de un Secret se almacenan en formato Base64, lo que permite que contraseñas y otros valores sean representados de manera legible para los sistemas, aunque no completamente encriptados.
⌭ Ejemplo de configuración de un ConfigMap:
En este caso, my-config almacena variables de configuración que pueden ser accedidas por los contenedores.
Para mayor seguridad, Kubernetes ofrece la opción de cifrar los Secrets en reposo utilizando cifrado AES o mediante proveedores de claves externas como AWS KMS o Google Cloud KMS. Esto garantiza que los datos estén encriptados a nivel de almacenamiento en etcd, evitando el acceso no autorizado y protegiendo la información sensible.
Además, el acceso a los Secrets se puede controlar de manera detallada. Se pueden configurar políticas de acceso para que solo ciertos Pods o servicios puedan acceder a ellos, limitando así el riesgo de exposición. El acceso se administra mediante políticas RBAC (Role-Based Access Control), lo que permite definir de forma precisa qué entidades tienen permiso para leer o modificar los Secrets.
⌭ Ejemplo de configuración de un Secret:
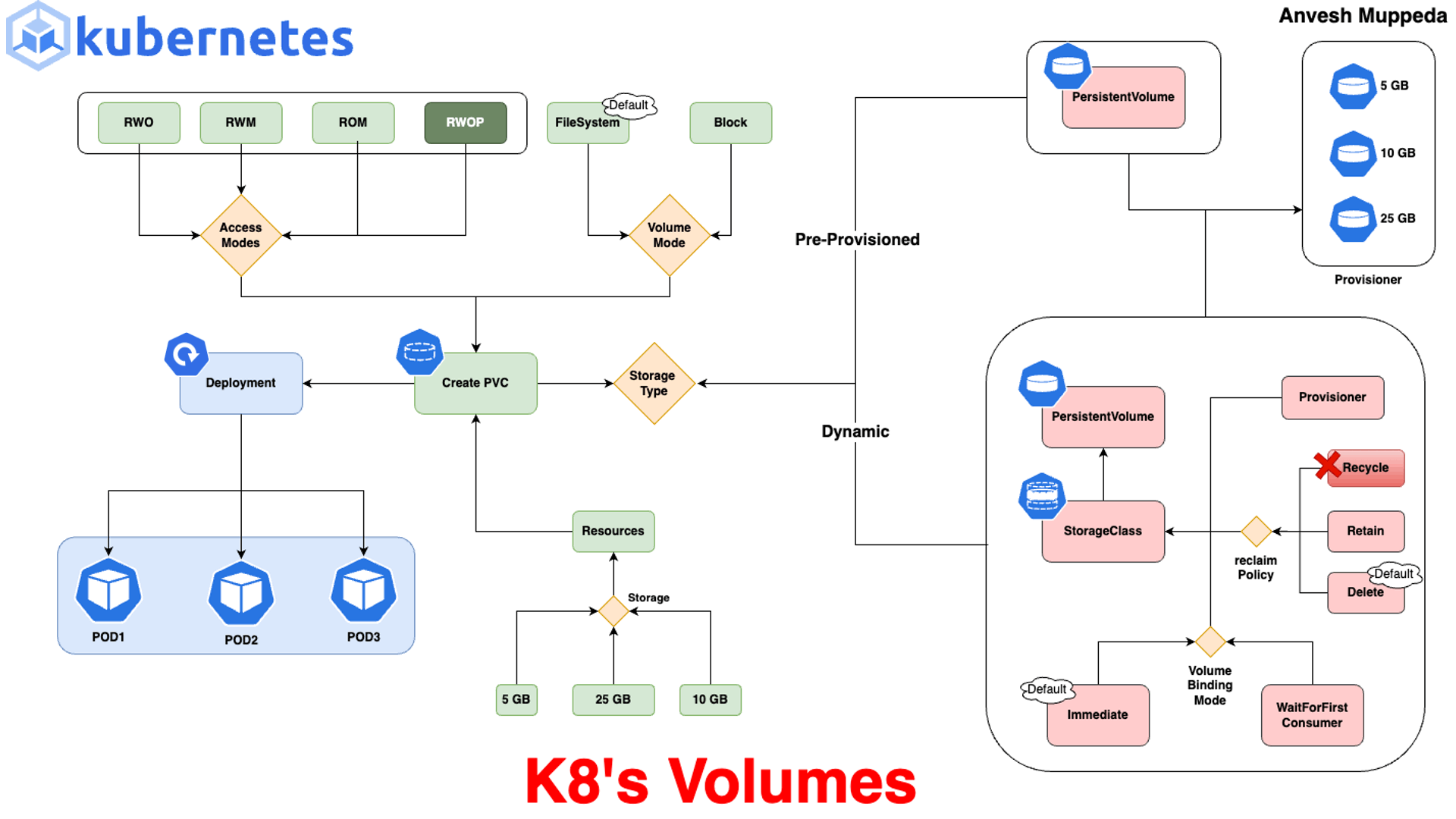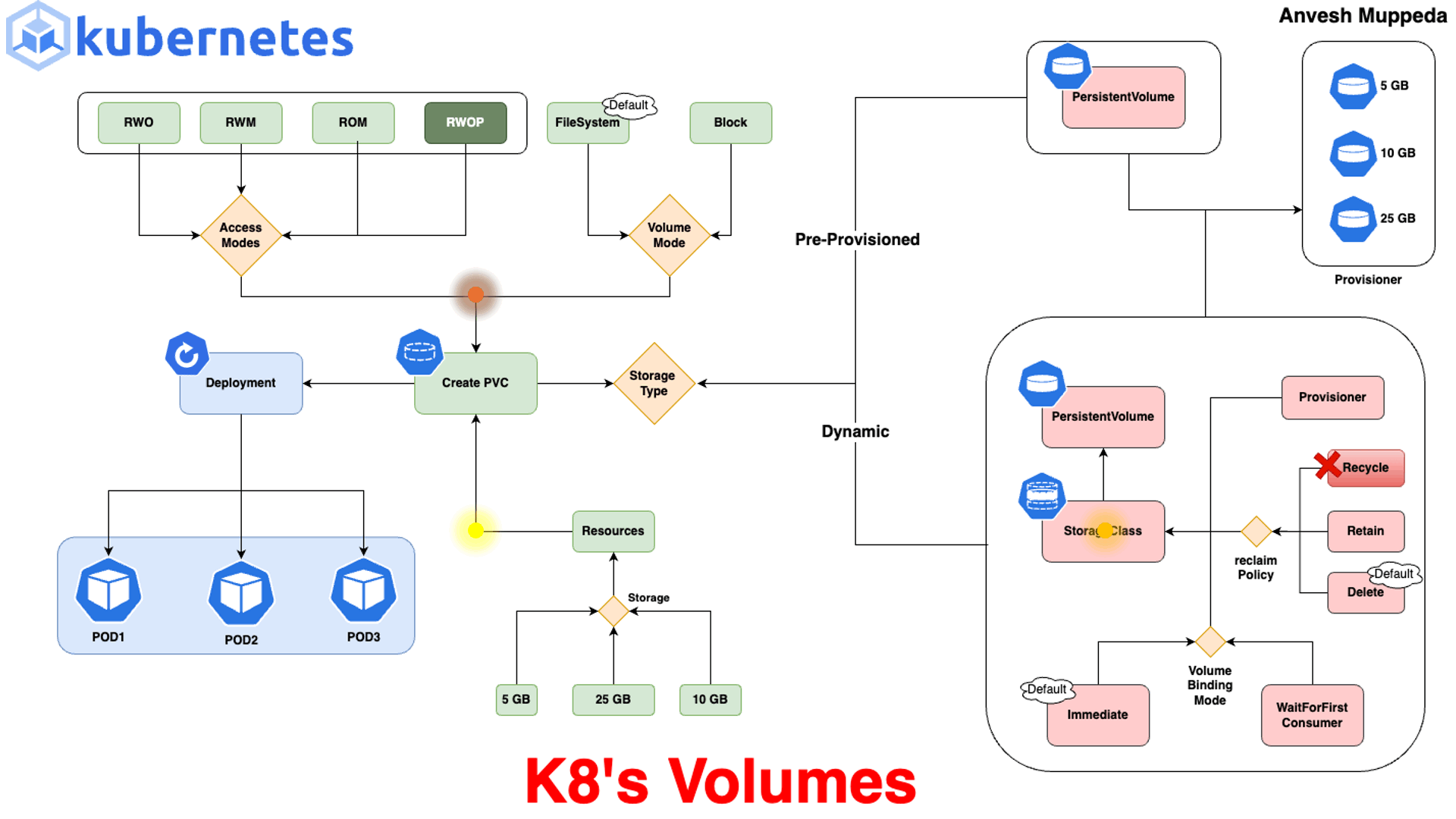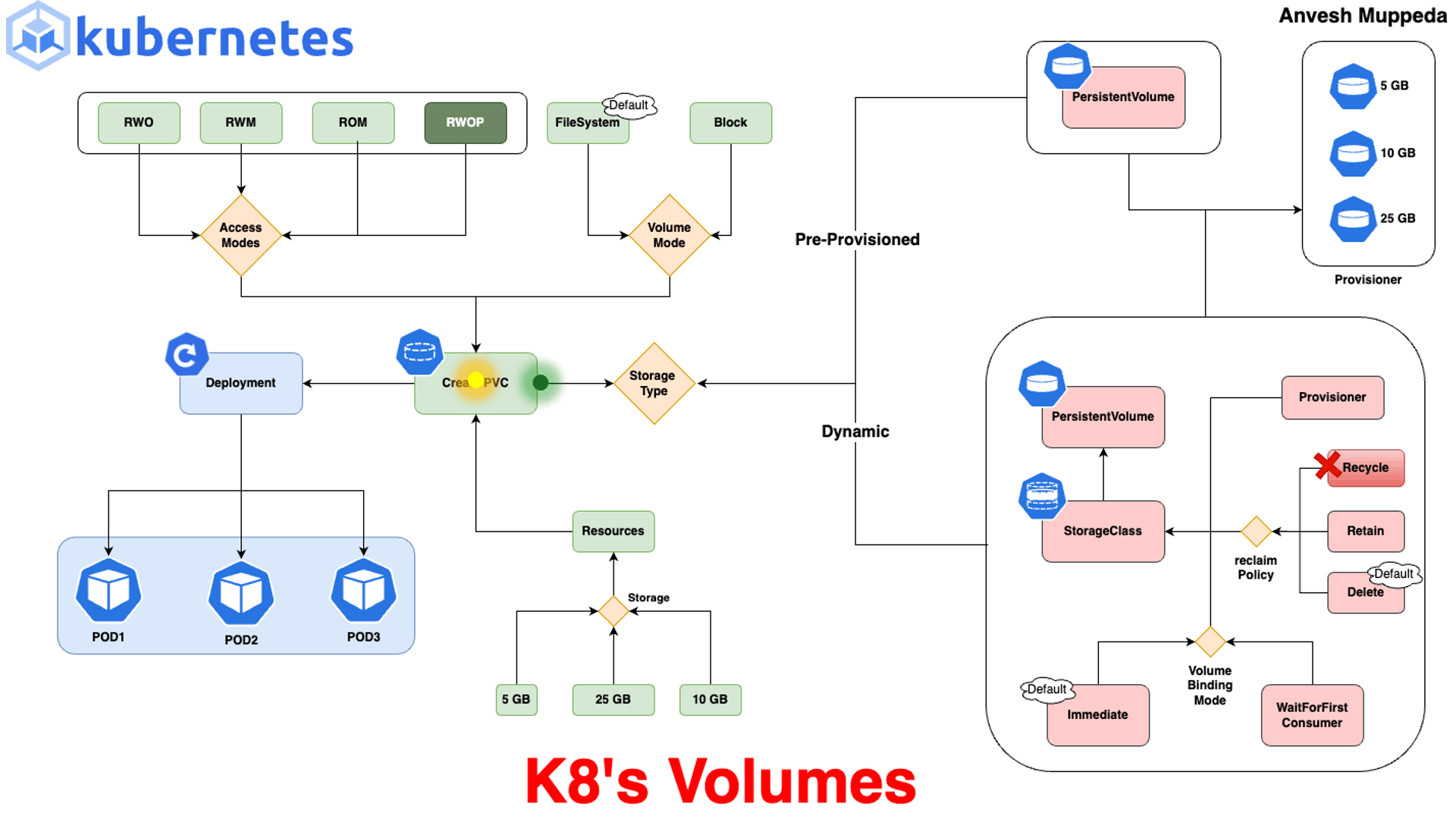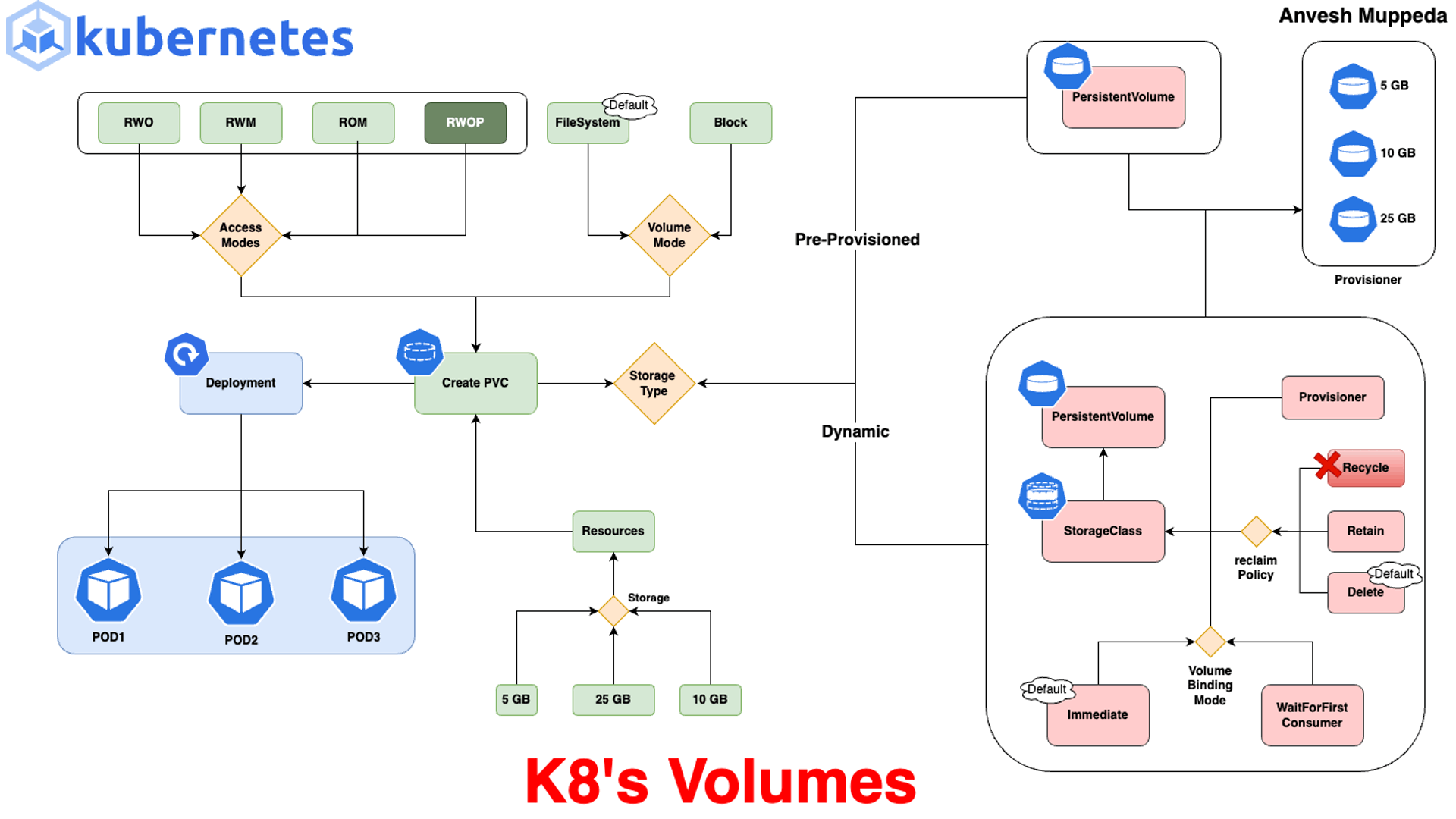
Volumes
Volumes: En Kubernetes, los Volumes permiten almacenar datos que persisten entre reinicios de contenedores, ya que los datos almacenados directamente en un contenedor se pierden si el contenedor se detiene o se reinicia.- ▱
emptyDir: Este volumen se crea cuando se inicia el Pod y se elimina al terminar el Pod. Se utiliza para almacenamiento temporal, donde los datos no son persistentes entre reinicios de Pods. - ▱
hostPath: hostPath permite que un Pod use un archivo o directorio en el sistema de archivos del nodo. Es útil para acceder a recursos locales del nodo, aunque presenta riesgos si no se controla, ya que el Pod puede acceder a partes sensibles del nodo. - ▱
PersistentVolume (PV) y PersistentVolumeClaim (PVC): PV es un volumen persistente que abstrae el almacenamiento físico, mientras que el PVC es una solicitud de almacenamiento realizada por un Pod. Los PV pueden ser de diferentes tipos, como almacenamiento en la nube (AWS EBS, GCP Persistent Disk, Azure Disk) o almacenamiento de red (NFS). - ▱
ConfigMap y Secret: Aunque no son estrictamente volúmenes de datos, estos objetos pueden montarse en los Pods como volúmenes. ConfigMap se usa para almacenar datos de configuración que no sean secretos, mientras que Secret almacena datos sensibles. Ambos permiten que las aplicaciones accedan a configuraciones sin necesidad de almacenarlas en el código. - ▱
nfs: nfs permite que el clúster acceda a sistemas de archivos remotos a través del protocolo NFS. Este tipo es adecuado para volúmenes compartidos entre varios Pods. - ▱
CSI (Container Storage Interface): Kubernetes admite la integración con diferentes proveedores de almacenamiento a través de CSI, lo cual permite la creación y administración de volúmenes de proveedores de almacenamiento de terceros, como Ceph o GlusterFS. - ▱
ephemeral volumes (volúmenes efímeros): Este tipo de volumen proporciona almacenamiento temporal que se elimina al destruir el Pod. Es útil para almacenamiento temporal y operaciones que requieren espacio de almacenamiento durante la ejecución del Pod.
Kubernetes ofrece varios tipos de volúmenes para adaptarse a diferentes requisitos de almacenamiento, desde almacenamiento temporal en el nodo hasta almacenamiento persistente que sobrevive al ciclo de vida de los Pods. Estos son algunos de los tipos principales:
Primero, se define el PV con el tipo de almacenamiento y la capacidad, y luego el PVC solicita ese recurso.
⌭ Ejemplo de configuración de un Pod con un Volume:
Deployment y StatefulSet
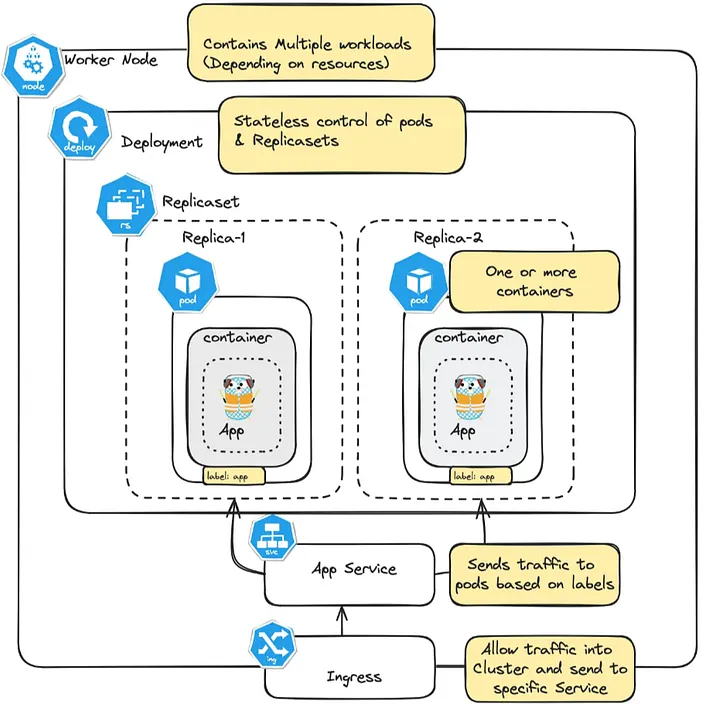
Deployment: Deployment se utiliza para aplicaciones sin estado (stateless) que no necesitan almacenamiento persistente o identificación específica en el clúster. Los Pods administrados por un Deployment son intercambiables y no conservan un identificador único entre ellos, lo que facilita el reemplazo de Pods sin necesidad de almacenar información específica en cada instancia.StatefulSet: StatefulSet es un controlador diseñado para aplicaciones con estado, que necesitan que sus Pods tengan una identidad estable y almacenamiento persistente. Es ideal para bases de datos y sistemas de mensajería que dependen de mantener datos y configuraciones específicas entre reinicios.
Un Deployment es ideal para aplicaciones sin estado como servidores web o aplicaciones frontend, donde la persistencia de datos no es necesaria entre los reinicios de los Pods. Si un Pod falla, Kubernetes puede reiniciar uno nuevo sin que afecte el comportamiento de la aplicación.
El Deployment asegura que un número especificado de Pods esté siempre activo, y si uno de ellos falla, se crea automáticamente otro para mantener la cantidad requerida. Además, permite realizar actualizaciones continuas de la aplicación sin detener todos los Pods a la vez. Si algo sale mal durante una actualización, es fácil retroceder a una versión anterior. También ofrece escalabilidad, permitiendo agregar o eliminar réplicas de Pods para ajustar la carga de trabajo según sea necesario, lo que garantiza que el sistema pueda manejar variaciones en el tráfico o la demanda.
⌭ Ejemplo de configuración de un Deployment:
Replicas especifica el número de Pods que se ejecutarán, mientras que selector define una etiqueta que Kubernetes usará para identificar los Pods administrados. Finalmente, template describe el contenedor que se ejecutará en cada Pod, proporcionando los detalles necesarios para la creación de los Pods según las especificaciones del contenedor.
Cada Pod gestionado por un StatefulSet tiene una identidad estable, con un nombre único (como my-app-0, my-app-1) que se mantiene incluso al reiniciar el Pod. Además, los Pods se crean y eliminan en orden secuencial, lo que es crucial para aplicaciones que requieren un inicio o apagado ordenado, como las bases de datos distribuidas. También se asegura la persistencia, ya que cada Pod puede estar asociado con un PersistentVolume que retiene los datos, incluso si el Pod se reinicia o se reemplaza.
⌭ Ejemplo de configuración de un StatefulSet:
serviceName es el servicio que permite a los Pods del StatefulSet comunicarse entre sí. Además, volumeClaimTemplates crea un PersistentVolumeClaim (PVC) para cada réplica, garantizando que cada Pod tenga su propio volumen persistente.
DaemonSet
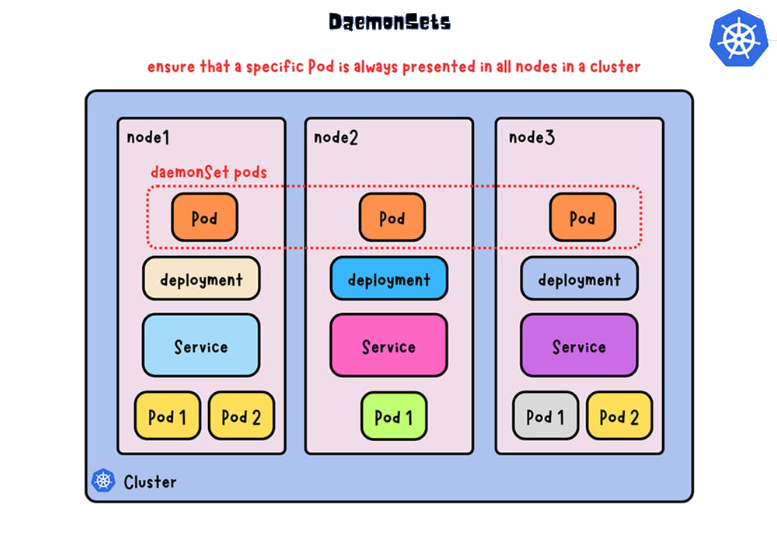
DaemonSet: Un DaemonSet es un recurso de Kubernetes diseñado para asegurar que un Pod específico se ejecute en cada Node del clúster, o en un subconjunto específico de Nodes. Los DaemonSets son esenciales para desplegar aplicaciones o servicios que deben estar presentes en todos los Nodes, como herramientas de monitoreo, recolección de logs o soluciones de red.- ▱
Distribución en todos los Nodes: DaemonSets aseguran que cada Node en el clúster, tanto los nuevos como los ya existentes, ejecuten automáticamente el Pod asociado. Esto garantiza que todos los Nodes tengan el mismo servicio en ejecución, brindando un control uniforme en el clúster. - ▱
Actualización: Permite actualizar todos los Pods de un DaemonSet sin necesidad de intervención manual. Kubernetes controla la propagación de la actualización, evitando interrupciones o duplicaciones de Pods.
⌭ Ejemplo de configuración de un DaemonSet:
⌭ Este ejemplo configura un DaemonSet para un recolector de logs en el clúster. Cada Node ejecutará un Pod de recolección de logs, asegurando que los logs se capturen en toda la infraestructura de Kubernetes.
Arquitectura
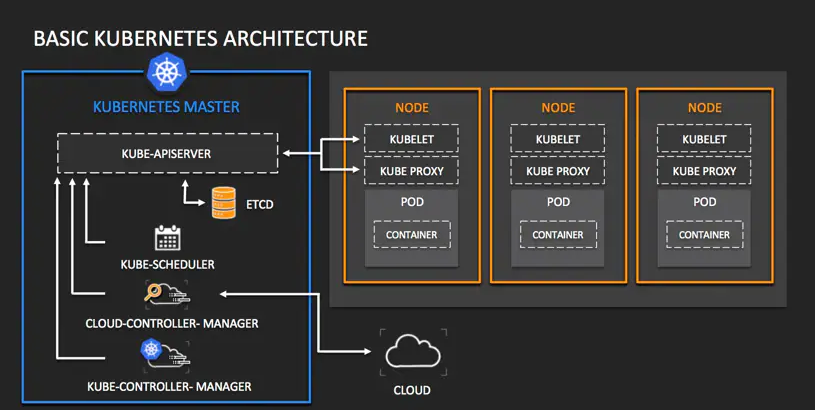
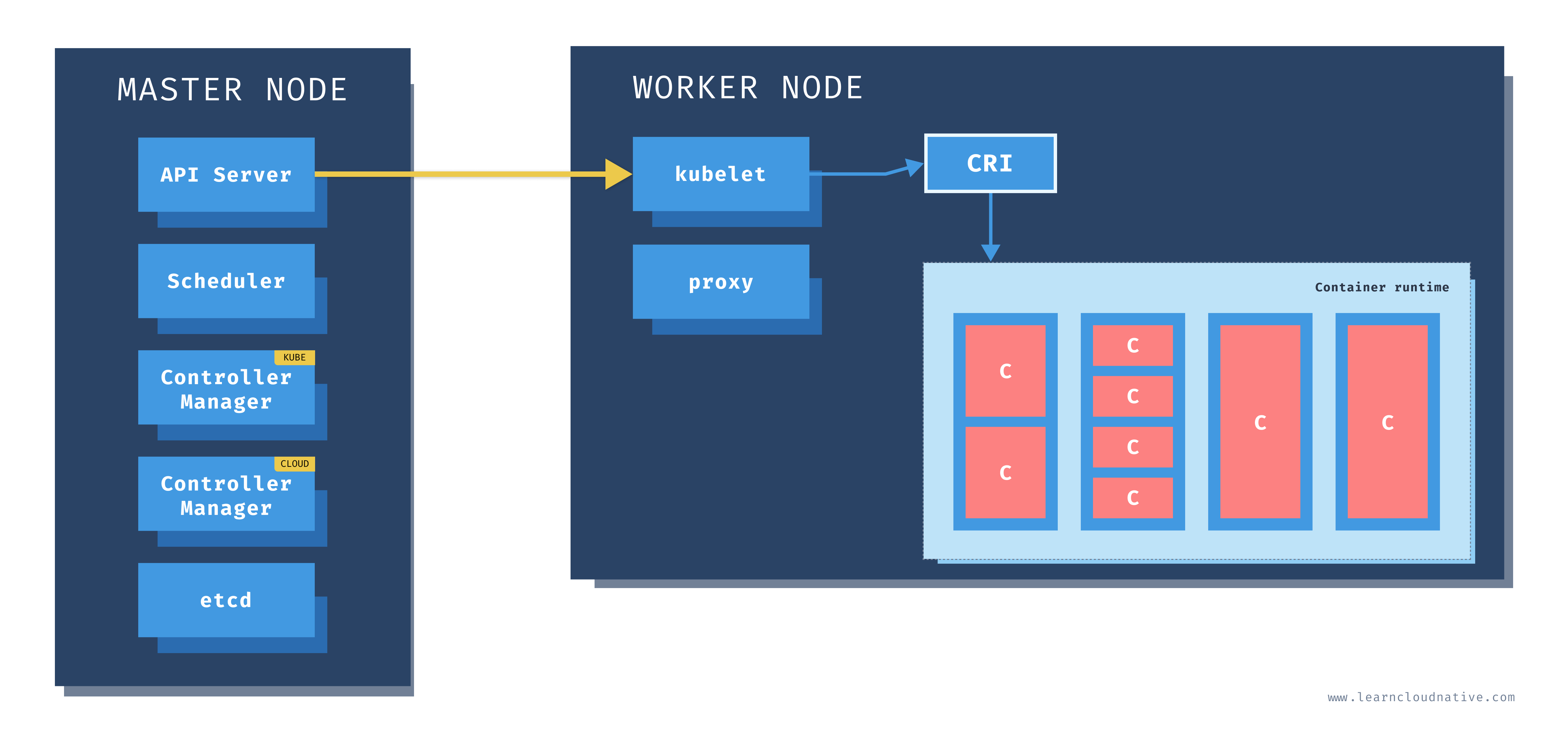
Kubernetes cuenta con una arquitectura distribuida, diseñada para administrar y coordinar contenedores en clústeres de máquinas, ya sea en entornos de nube, híbridos o locales. Su arquitectura incluye componentes que funcionan en el plano de control (control plane) y en los nodos de trabajo (worker nodes).
Plano de Control (Control Plane)
El plano de control contiene los componentes necesarios para gestionar el clúster, decidir dónde y cuándo ejecutar los Pods, monitorizar los eventos del sistema y manejar el estado global del clúster. Este plano de control incluye los siguientes componentes principales:
API Server: El API Server es el componente central que actúa como la interfaz entre el clúster y los usuarios. Este servidor recibe y valida las peticiones (como crear o eliminar Pods), y expone la API de Kubernetes para la comunicación con otros componentes.- ⚙️
Configuración: La configuración del API Server se encuentra en los archivos de configuración de Kubernetes (comokube-apiserver.yaml ) y permite definir parámetros clave como los puertos, el cifrado de comunicación y los mecanismos de autenticación y autorización. Etcd: Etcd es una base de datos distribuida de tipo key-value, que almacena toda la información crítica sobre el estado del clúster. Es fundamental para la resiliencia del sistema, ya que cualquier configuración, como los Pods activos, los servicios y las políticas de red, se guarda aquí.- ⚙️
Configuración: En un entorno de producción, se suele configurar etcd como un clúster distribuido, a menudo en servidores separados para mejorar la resiliencia. Configurarlo con certificados TLS es una práctica recomendada para proteger los datos. Controller Manager: El Controller Manager contiene varios controladores que ejecutan bucles de control para asegurar que el estado actual del clúster coincida con el estado deseado. Algunos controladores importantes incluyen:- ▱
Node Controller: Detecta nodos inactivos y realiza acciones para mantener la integridad del clúster. - ▱
Replication Controller: Asegura que un número especificado de réplicas de un Pod esté en ejecución. - ▱
Endpoint Controller: Gestiona las conexiones entre servicios y Pods. - ⚙️
Configuración: El archivo de configuración permite ajustar opciones como la sincronización de Pods y los intervalos de monitoreo, así como el número de hilos para cada tipo de controlador. Scheduler: El Scheduler asigna Pods a nodos basándose en los requisitos de los Pods y las capacidades de los nodos. Este componente usa políticas de afinidad y anti-afinidad para ubicar los Pods estratégicamente, optimizando el rendimiento y la disponibilidad.
⌭ Ejemplo básico de configuración del API Server:
En este caso, se define un servicio de API personalizado en el clúster.
⌭ Este ejemplo muestra un clúster de etcd con tres réplicas, asegurando alta disponibilidad.
⌭ Ejemplo de configuración básica de un Scheduler personalizado:
En este ejemplo, se crea un ConfigMap para un Scheduler personalizado, lo que permite definir preferencias de asignación de Pods.
Nodos de Trabajo (Worker Nodes)
Los nodos de trabajo ejecutan los contenedores mediante Pods y son administrados por el plano de control. Cada nodo contiene los siguientes componentes principales:
Kubelet: Kubelet es un agente que se ejecuta en cada nodo y asegura que los contenedores estén activos según las especificaciones del Pod. Kubelet interactúa constantemente con el API Server para recibir y ejecutar las instrucciones.- ⚙️
Configuración: El archivo de configuración de Kubelet (kubelet-config.yaml ) define detalles como la dirección IP del API Server, las opciones de red y los certificados. Kube-proxy: Kube-proxy gestiona las reglas de red en el nodo y habilita el reenvío de tráfico a los servicios correspondientes. Utiliza IP tables o modos basados en usuarios para garantizar que el tráfico entre los servicios y Pods fluya adecuadamente.- ⚙️
Configuración: La configuración puede incluir reglas de enrutamiento específicas, balanceo de carga interno y control de acceso. Container Runtime: El runtime de contenedores ejecuta y gestiona los contenedores en el nodo. Docker y containerd son opciones comunes, y Kubernetes interactúa con ellos mediante el Container Runtime Interface (CRI).
Componentes Adicionales
Además de los componentes centrales, existen otros recursos importantes en la arquitectura de Kubernetes que permiten gestionar aplicaciones complejas y datos persistentes:
Network Plugins (CNI): Kubernetes utiliza Container Network Interface (CNI) para configurar redes entre contenedores. Plugins como Calico o Flannel permiten establecer políticas de red, configuración de IPs y redes seguras.Storage (Persistent Volumes y Persistent Volume Claims): Kubernetes permite el almacenamiento persistente a través de Persistent Volumes (PV) y Persistent Volume Claims (PVC), útiles para aplicaciones que necesitan retener datos. Un PV es una pieza de almacenamiento en el clúster, mientras que un PVC es una solicitud de almacenamiento que puede utilizar un Pod.Addon de monitoreo y administración (Metric Server): El Metric Server recopila datos sobre el consumo de recursos de los Pods y los nodos, permitiendo la auto-escalabilidad de aplicaciones.
Este comando aplica una configuración de red de Calico para el clúster.
⌭ Ejemplo de configuración de un PV y PVC:
Minikube
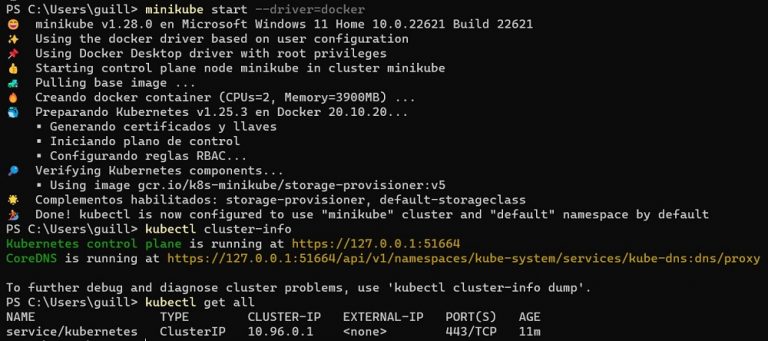
Minikube es una herramienta que permite ejecutar un clúster de Kubernetes en una sola máquina, ya sea un entorno local o virtualizado, lo que facilita el aprendizaje, desarrollo y pruebas de aplicaciones en Kubernetes sin necesidad de infraestructura en la nube. Minikube crea una máquina virtual o un entorno virtualizado en el cual se ejecuta un clúster de Kubernetes de un solo nodo.
Esta herramienta es ideal para quienes desean experimentar con Kubernetes en sus equipos y probar configuraciones antes de desplegarlas en un entorno de producción. Minikube incluye una serie de complementos y características para simular funcionalidades avanzadas de Kubernetes, como Ingress Controllers, Dashboards y controladores de almacenamiento.
Instalación y Ejecución de Minikube: Para comenzar con Minikube, se necesitan ciertas dependencias básicas como kubectl y una herramienta de virtualización, como VirtualBox o Docker.
Descarga e instala Minikube según el sistema operativo.
Este comando iniciará el clúster de Kubernetes en una VM o en Docker, y en unos momentos podrás acceder al clúster local.
Minikube también ofrece acceso al Dashboard de Kubernetes con el comando
kubectl
kubectl es la herramienta de línea de comandos que permite a los usuarios interactuar y administrar sus clústeres de Kubernetes. Proporciona comandos para realizar tareas comunes como crear, escalar y eliminar Pods, monitorear el estado de los recursos, y aplicar configuraciones.
Con kubectl, los desarrolladores pueden definir y aplicar configuraciones de recursos, como Deployments, Services, y Persistent Volumes, a través de archivos YAML o JSON. Esto permite gestionar el estado deseado de las aplicaciones y responder a eventos en el clúster.

Comandos Esenciales de kubectl:
kubectl también incluye comandos avanzados como
Proyecto en K8s
❏ Primero, es necesario instalar Minikube, y el primer paso es asegurarse de tener Docker instalado en tu sistema, ya que Minikube utiliza contenedores para simular un clúster de Kubernetes.
Con Docker ya en funcionamiento, descarga Minikube desde su sitio oficial o instala directamente ejecutando el siguiente comando en Linux:
❏ Edita el archivo de configuración de sudoers para permitir que se ejecute podman sin necesidad de ingresar una contraseña. Esto lo puedes hacer con los siguientes pasos:
Agrega la siguiente línea al final del archivo (reemplaza usuario con tu nombre de usuario):
Guarda y cierra el archivo. Ahora, Minikube debería poder ejecutar podman sin solicitar la contraseña de sudo.
❏ Luego intenta iniciar Minikube:
ryuzak1@ubuntu: ~
❏ Para configurar Kubernetes a través de la terminal, se debe contar con kubectl.
Si prefieres usar un gestor de paquetes, puedes instalar kubectl de la siguiente manera, dependiendo de la distribución de Linux que uses.
❏ Para verificar el estado del clúster de Minikube, puedes usar:
ryuzak1@ubuntu: ~
❏ Para verificar el estado de los nodos en Minikube, puedes usar:
ryuzak1@ubuntu: ~
Para configurar MongoDB en un entorno de Kubernetes, necesitas cuatro archivos de configuración en YAML para gestionar el despliegue y la comunicación del servicio en el clúster.
En el sitio web de Kubernetes está disponible la documentación que especifica el formato requerido para los archivos de configuración.
Estos archivos incluirán:
ConfigMap: Secret: Deployment y Service de mongo: Deployment y Service de la AppWeb:
Almacena la URL de conexión (mongo-url) para MongoDB, que los pods pueden utilizar para conectarse al servicio de MongoDB en el clúster.
Guarda el nombre de usuario (mongo-user) y la contraseña (mongo-password) de MongoDB en forma segura usando codificación base64, para proteger las credenciales.
El deployment define el despliegue de MongoDB en un contenedor con una réplica, configurado para usar las credenciales almacenadas en el secreto mongo-secret.
Luego service expone MongoDB dentro del clúster en el puerto 27017, permitiendo el acceso a otros pods usando el nombre de mongo-service.
La imagen oficial de MongoDB está disponible en Docker Hub, un repositorio de contenedores de uso común. Puedes obtenerla directamente desde Docker Hub usando la etiqueta de versión que desees, por ejemplo, mongo:5.0, mongo:6.0, o simplemente mongo para la última versión.
Si tu aplicación MongoDB es no replicada y simplemente necesitas un contenedor con almacenamiento temporal (por ejemplo, para entornos de prueba o desarrollo), un Deployment podría ser suficiente. Sin embargo, para entornos de producción, o si necesitas replicación y persistencia, es mejor usar un StatefulSet.
Este archivo especifica el despliegue de un contenedor con la imagen de una webapp implementada en Nodejs y su configuración.
Cuando la aplicación web se inicie, requerirá las credenciales de la base de datos para establecer la conexión. Esta información se gestionará como variables de entorno.
En la configuración del servicio se definirá el puerto a través del cual se expondrá la aplicación web. La variable nodePort se utilizará para este propósito. Este número debe estar dentro del rango 30000-32767.
Ahora solo falta crear los recursos descritos en los archivos .yaml en el clúster de Kubernetes.
❏ ConfigMap
ryuzak1@ubuntu: ~
❏ Secret
ryuzak1@ubuntu: ~
❏ MongoDB
ryuzak1@ubuntu: ~
❏ WebApp
ryuzak1@ubuntu: ~
❏ Para obtener una lista de todos los recursos principales en el clúster de Kubernetes.
ryuzak1@ubuntu: ~
❏ Para obtener una lista de todos los pods en un clúster de Kubernetes.
ryuzak1@ubuntu: ~
❏ Para obtener información detallada sobre un servicio específico en el clúster de Kubernetes.
ryuzak1@ubuntu: ~
❏ Para obtener información detallada sobre un pod específico en un clúster de Kubernetes.
ryuzak1@ubuntu: ~
❏ Para ver los logs de un pod específico en un clúster de Kubernetes.
ryuzak1@ubuntu: ~
❏ Para listar todos los servicios en el clúster de Kubernetes dentro del namespace predeterminado.
ryuzak1@ubuntu: ~
❏ Para obtener la dirección IP de la máquina virtual (VM) que ejecuta el clúster de Minikube.
ryuzak1@ubuntu: ~
❏ Para obtener una vista más completa de los nodos y ver detalles como las direcciones IP y las versiones del sistema operativo y de Kubernetes que están utilizando.
ryuzak1@ubuntu: ~
❏ Puedes acceder a tu aplicación web desplegada en Minikube utilizando la IP proporcionada por el comando
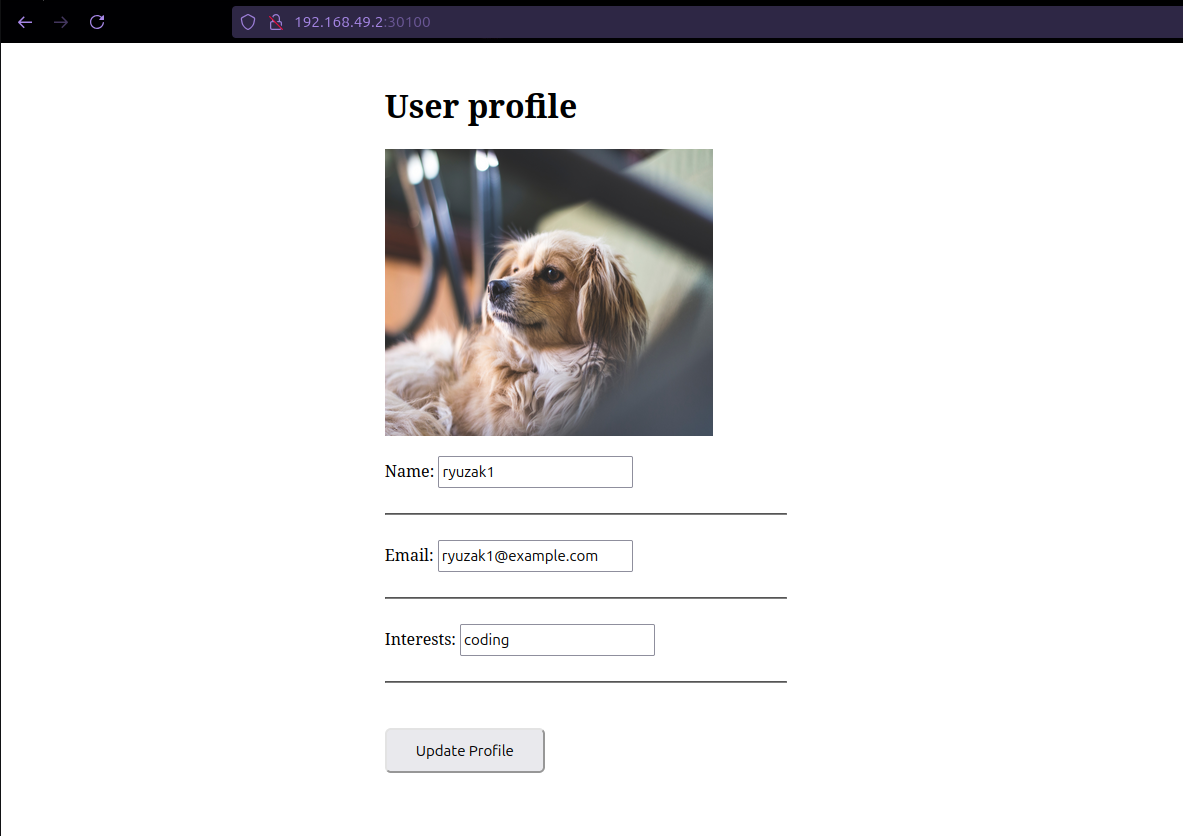
Proyecto Básico
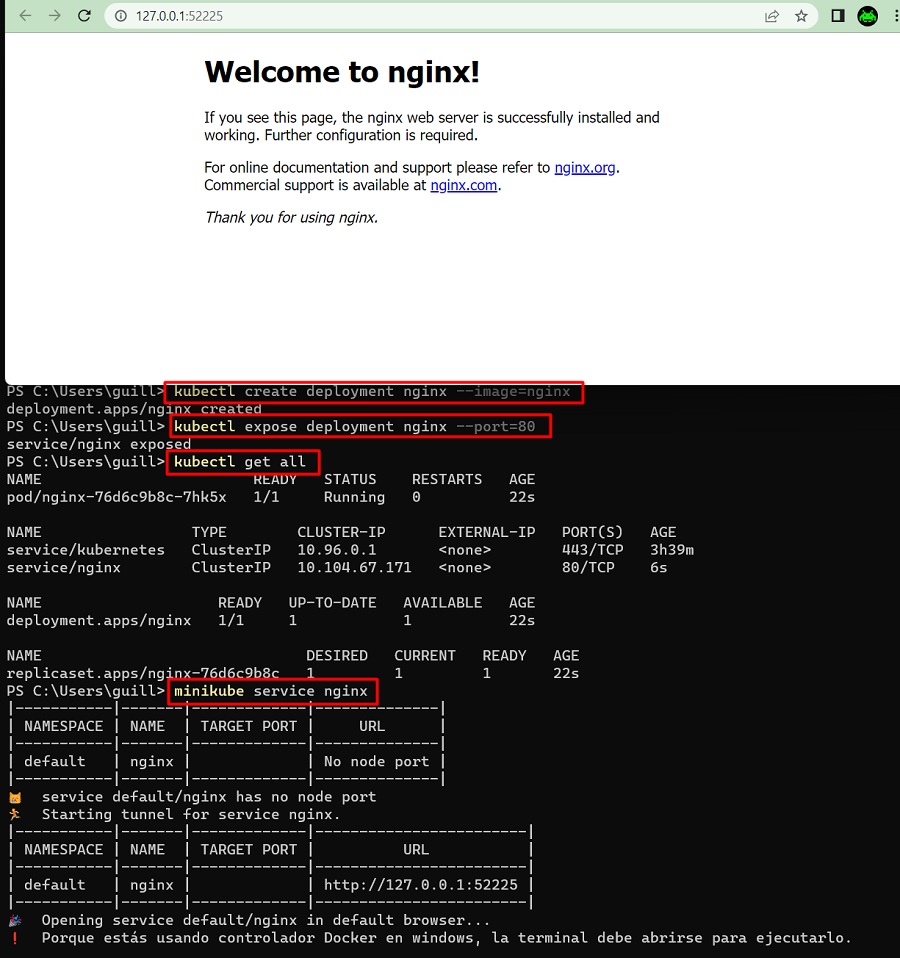
Iniciar Minikube: Ejecuta el comandominikube start para levantar el clúster en tu máquina local.Crear un Archivo YAML para un Deployment: Definimos un archivodeployment.yaml que describe un Deployment con una imagen de Nginx:Aplicar el YAML con kubectl: Ejecutakubectl apply -f deployment.yaml para crear el Deployment en el clúster de Minikube. Esto iniciará dos réplicas de Nginx según lo especificado en el archivo.Verificar el Estado del Deployment: Usakubectl get deployments ykubectl get pods para ver el estado del Deployment y sus Pods. También puedes observar los detalles de cada Pod y su asignación de IP dentro del clúster.Exponer el Servicio: Para acceder a la aplicación Nginx desde el navegador, crea un Service para exponer el Deployment.Escalar el Deployment: Supongamos que necesitas aumentar la capacidad. Ejecuta el comandokubectl scale deployment nginx-deployment --replicas=4 para escalar a cuatro réplicas. Esto reflejará la capacidad de Kubernetes para escalar aplicaciones de manera eficiente.Detener Minikube: Cuando termines, ejecutaminikube stop para detener el clúster y liberar los recursos de tu máquina.
Luego, usa
Minikube permite levantar un clúster de Kubernetes completo en una sola máquina, y kubectl ofrece el control y administración necesarios para desplegar, escalar y gestionar aplicaciones dentro del clúster. Al combinar Minikube y kubectl, los desarrolladores pueden simular con precisión configuraciones de producción y experimentar con los componentes de Kubernetes sin costos adicionales en infraestructura de nube.
