



Redis
Redis es un sistema de almacenamiento en memoria de estructura de datos clave-valor, que se utiliza principalmente como base de datos, caché y sistema de mensajes. Lanzado en 2009, Redis se destaca por su velocidad y versatilidad al gestionar datos en memoria, lo que lo convierte en una opción popular para aplicaciones que requieren un acceso extremadamente rápido a los datos. A diferencia de otras bases de datos, Redis maneja varios tipos de estructuras de datos como cadenas, listas, conjuntos y mapas hash.
Redis es altamente eficiente y se puede usar para una variedad de tareas, desde almacenar datos temporales en caché hasta gestionar colas de mensajes, sesiones de usuario y más. Su capacidad para operar con datos en memoria permite que las operaciones sean mucho más rápidas en comparación con los sistemas de bases de datos tradicionales.
Mientras que en bases de datos como MySQL o PostgreSQL es necesario definir un esquema con tablas, columnas y tipos de datos antes de almacenar información, Redis adopta un enfoque más flexible debido a su naturaleza como una base de datos NoSQL basada en memoria.
En Redis, los datos se almacenan en estructuras como cadenas, listas, conjuntos, hashes y más, donde cada elemento se identifica por una clave única. Esto significa que puedes comenzar a trabajar con Redis directamente, sin necesidad de planificar o definir previamente un esquema fijo.

Estructura
Redis organiza los datos utilizando una estructura clave-valor. Cada clave es un identificador único que se asocia con un valor, el cual puede ser de diferentes tipos de datos:
Tipos de datos
Redis utiliza una arquitectura interna que asigna las claves a diferentes tipos de datos, donde cada clave puede tener asociado un tipo único. Esto significa que Redis funciona como un espacio de nombres unificado donde puedes almacenar y consultar datos de diferentes modelos:
Tipos de datos básicos soportados nativamente Cadenas String: Las cadenas en Redis son el tipo de dato más básico. Pueden contener cualquier tipo de información, como texto, números y más.Listas List: Una lista es una secuencia de elementos ordenados. Redis permite agregar elementos a las listas de manera eficiente desde ambos extremos.Conjuntos Set: Un conjunto es una colección de elementos únicos no ordenados. Ideal para operaciones como la verificación de membresía y la eliminación de duplicados.Conjuntos ordenados Sorted Set: Es similar a un conjunto, pero cada elemento tiene un score que permite ordenarlo automáticamente según ese valor.Mapas Hash Hash: Un mapa hash es una colección de campos y valores asociados, útil para almacenar objetos y datos complejos.Flujos Streams: Son flujos de datos que permiten el procesamiento de mensajes en tiempo real.Estructuras avanzadas Bitmaps y HyperLogLogs: Son estructuras optimizadas para tareas como el conteo aproximado de elementos o la manipulación eficiente de bits.Tipos avanzados mediante módulos RedisJSON RedisJSON: Permite almacenar y consultar documentos JSON directamente en Redis.RedisGraph RedisGraph: Un motor de grafos basado en Cypher, adecuado para realizar consultas complejas sobre grafos.RedisTimeSeries RedisTimeSeries: Optimizado para almacenar y consultar datos temporales, con soporte para agregaciones y compresión.RedisBloom RedisBloom: Permite utilizar estructuras de datos probabilísticas como filtros Bloom para mejorar la eficiencia de las consultas.RedisAI RedisAI: Permite ejecutar modelos de inteligencia artificial directamente en Redis.

Características principales de Redis
∘
∘
∘
∘
AOL
Redis en AOL (Append-Only Log) utiliza un sistema de registro que guarda cada comando de escritura en un archivo, lo que permite garantizar la persistencia de los datos incluso en caso de fallos o reinicios. Este mecanismo opera como un diario donde cada operación que modifica el estado de la base de datos se escribe secuencialmente.
El archivo de log, conocido como appendonly.aof, asegura que todas las operaciones sean registradas en el mismo orden en que fueron ejecutadas. Esto facilita reconstruir el estado exacto de la base de datos en caso de recuperación, reproduciendo los comandos uno por uno.
Redis permite configurar la frecuencia con la que los datos se sincronizan con el disco para equilibrar rendimiento y durabilidad. Esto se gestiona mediante la opción appendfsync, que puede configurarse en tres modos principales: sincronización en cada comando (mayor durabilidad pero más lento), sincronización cada cierto intervalo de tiempo o confiar en el sistema operativo para la escritura.
Una característica destacable de AOL es la compactación periódica, conocida como AOF rewrite. Este proceso genera una nueva versión optimizada del archivo, que contiene solo el estado actual de los datos y elimina operaciones redundantes, reduciendo el tamaño del archivo y mejorando la eficiencia en la restauración.
Enfoque multi-model de Redis
Un enfoque multi-model significa que Redis puede manejar diferentes tipos de datos y estructuras, como cadenas, listas, conjuntos, mapas y otros, bajo una misma instancia. Esto permite que múltiples aplicaciones con diferentes necesidades interactúen con la misma base de datos, reduciendo la complejidad de mantenimiento y aumentando la flexibilidad.
Redis combina esta capacidad nativa con módulos extensibles para manejar formatos especializados como gráficos, documentos y datos de series temporales, haciendo que sea más que una simple base de datos clave-valor.
Redis es capaz de almacenar estos diferentes tipos de datos y manejarlos gracias a su eficiente arquitectura interna:
⌭
⌭
⌭
⌭
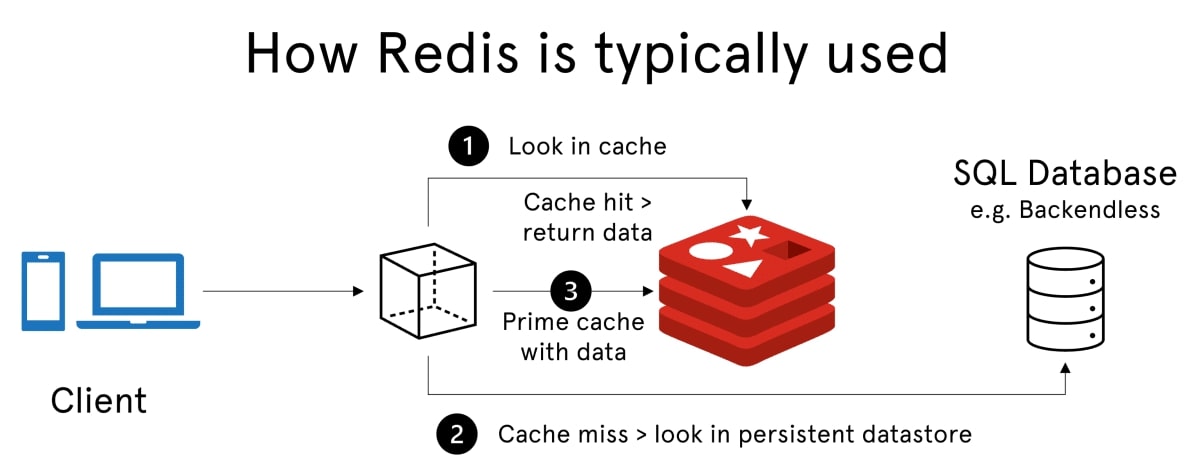
Módulos extendidos
∘ JSON.SET para almacenar documentos, JSON.GET para recuperarlos y JSON.ARRAPPEND para modificar arreglos dentro de ellos.
∘ GRAPH.QUERY para ejecutar consultas y GRAPH.DELETE para eliminar grafos, este módulo expande las capacidades analíticas de Redis en el ámbito de las relaciones.
∘ TS.ADD para agregar puntos de datos, TS.RANGE para consultar rangos históricos y TS.CREATE para inicializar series temporales.
∘ BF.ADD para añadir elementos y BF.EXISTS para verificar membresías lo hacen excelente para escenarios donde el uso eficiente de memoria es crítico.
∘ AI.MODELSET para cargar modelos y AI.TENSORSET para trabajar con tensores en almacenamiento.
∘ FT.CREATE para crear índices, FT.SEARCH para realizar búsquedas y FT.AGGREGATE para consultas con agregaciones complejas.
∘ RG.PYEXECUTE para ejecutar scripts en Python y RG.TRIGGER para activar flujos definidos.
∘ ML.MODELSET para definir modelos y ML.MODELRUN para realizar predicciones, es ideal para aplicaciones ligeras de IA en tiempo real.
∘
∘
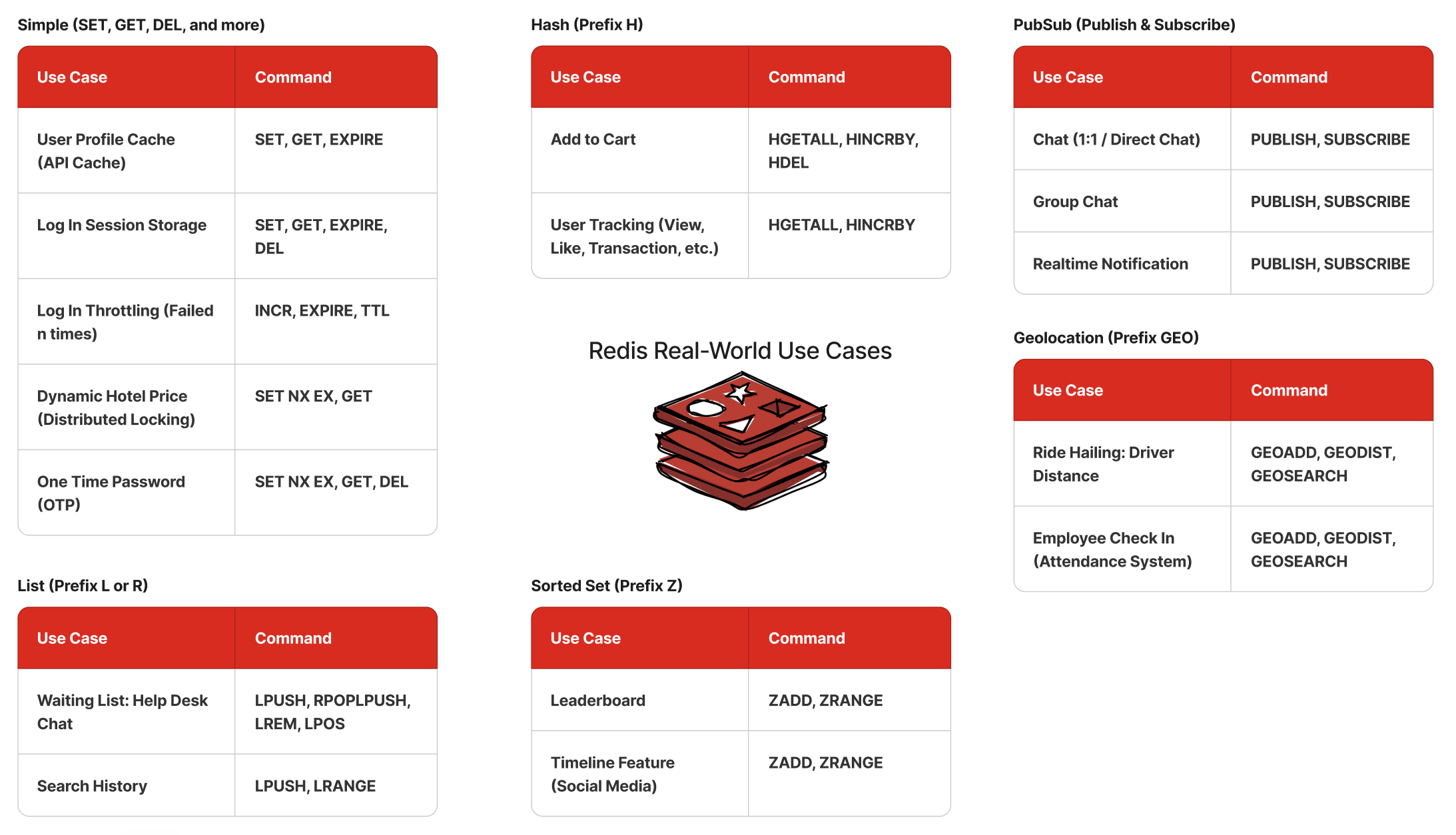
Operaciones comunes
CRUD (Create, Read, Update, Delete)
En Redis, las operaciones CRUD se realizan principalmente a través de comandos que manipulan las claves y sus valores en la base de datos de Redis.
SET GET DEL
Este comando agrega o actualiza la clave 'empleado:1001' con un conjunto de atributos (nombre, salario, departamento). En Redis, los valores pueden ser cadenas de texto, números u otros tipos.
Este comando devuelve el valor asociado con la clave 'empleado:1001', como los detalles del empleado con ese ID, si existe.
Este comando elimina la clave 'empleado:1001' de la base de datos de Redis. Todos los datos asociados con esa clave serán eliminados.
Manipulación de datos complejos
Redis permite trabajar con tipos de datos más complejos, como listas, conjuntos, y hashes.
HSET HGETALL
Este comando actualiza o agrega los campos 'nombre', 'salario' y 'departamento' al hash 'empleado:1001', permitiendo almacenar múltiples atributos para una clave en un solo objeto.
Este comando devuelve todos los campos y valores del hash 'empleado:1001'. Es útil para obtener todos los detalles asociados con una clave que contiene un hash.
Administración de la base de datos
Redis permite administrar las bases de datos mediante comandos específicos.
FLUSHALL DBSIZE
Este comando elimina todas las claves de todas las bases de datos en Redis. Es útil cuando necesitas borrar completamente todos los datos almacenados.
Este comando devuelve el número total de claves presentes en la base de datos activa de Redis.
Control de acceso
Redis permite configurar el acceso a la base de datos mediante autenticación y permisos.
AUTH CONFIG SET
Este comando permite autenticar a un cliente con la contraseña 'mi_contraseña_secreta' antes de permitirle ejecutar operaciones en la base de datos de Redis.
Este comando establece una nueva contraseña de acceso para la base de datos Redis, reemplazando la contraseña anterior.
Escalamiento en Redis
Redis es una base de datos extremadamente rápida que puede escalar horizontalmente para manejar grandes volúmenes de datos y tráfico. El escalamiento en Redis se logra principalmente a través de la fragmentación (sharding) y la replicación, aprovechando configuraciones como el modelo
Master-Slave
El modelo Master-Slave en Redis permite distribuir las operaciones de lectura y escritura de manera eficiente. En esta configuración, una instancia principal (Master) se encarga de las escrituras y actualizaciones de datos, mientras que múltiples réplicas (Slaves) manejan las operaciones de lectura.
Master: Es la instancia principal que almacena los datos y se encarga de replicarlos a los Slaves.Slave: Son réplicas del Master que reciben los datos a través de replicación asíncrona y responden a las solicitudes de lectura.Alta disponibilidad: Si el Master falla, puede configurarse una nueva promoción automática de un Slave a Master utilizando sistemas como Redis Sentinel.
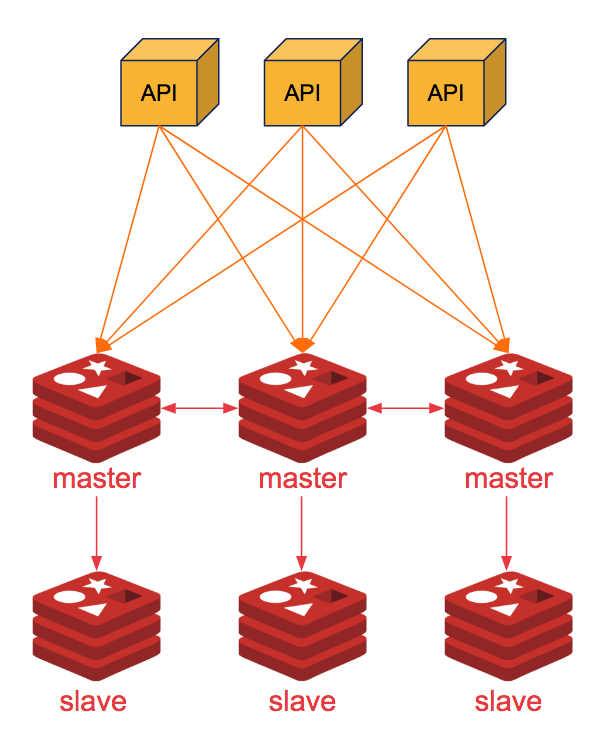
SOSS (Scale Out State Server)
El sistema SOSS permite el escalamiento horizontal de Redis mediante la fragmentación de los datos en varios nodos. Cada nodo almacena una parte de los datos, y los clientes acceden a ellos utilizando un mecanismo de mapeo que garantiza que las claves se dirijan al nodo correcto.
Fragmentación: Los datos se dividen en fragmentos (shards), y cada shard se almacena en un nodo diferente.Distribución consistente: Redis Cluster utiliza un algoritmo de hash para garantizar que las claves se distribuyan de manera uniforme entre los nodos.Failover: En caso de fallo de un nodo, Redis Cluster puede redistribuir las claves afectadas a los nodos restantes.
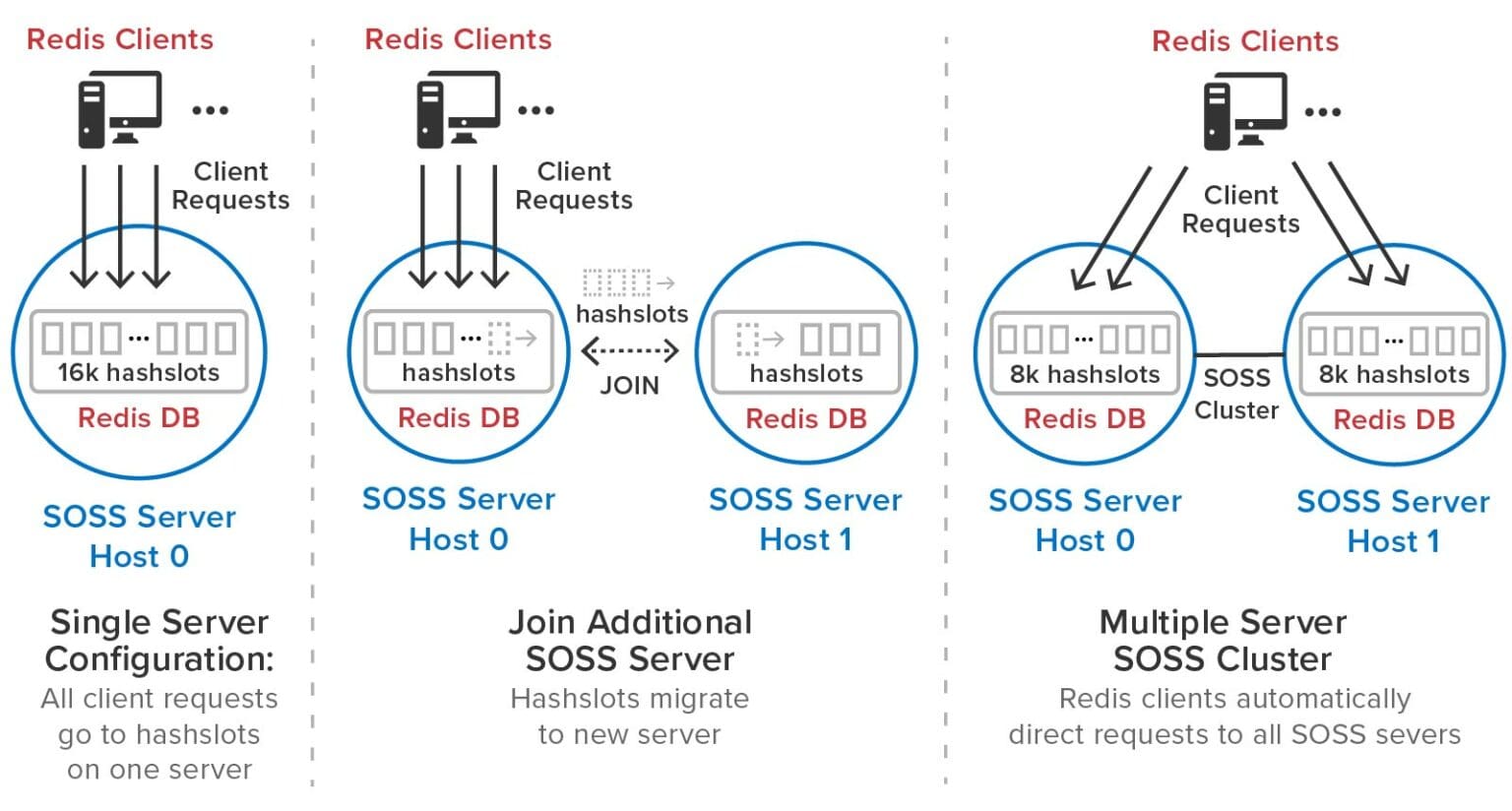
Ambas estrategias combinan rendimiento y escalabilidad, lo que permite a Redis manejar cargas de trabajo intensivas y volúmenes de datos en crecimiento de manera eficiente. El modelo Master-Slave es ideal para mejorar el rendimiento de lectura, mientras que el sistema SOSS permite escalar Redis horizontalmente para manejar grandes conjuntos de datos.
Operadores
En Redis, las funciones y operadores permiten realizar manipulaciones de datos, como la transformación, filtrado, y modificación de valores de las claves de manera eficiente. Redis, a diferencia de bases de datos como MongoDB o SQL, se basa en un modelo de datos en memoria y no tiene una sintaxis tan rica para agregación, pero permite realizar operaciones rápidas y eficientes sobre conjuntos de datos.
Operadores Básicos
Redis proporciona un conjunto de operadores básicos para manipular los datos en sus estructuras de datos. Estos operadores pueden usarse en comandos como SET, GET, DEL, y otros.
SET: Asigna un valor a una clave.GET: Recupera el valor de una clave.DEL: Elimina una o más claves.EXPIRE: Establece un tiempo de expiración para una clave.
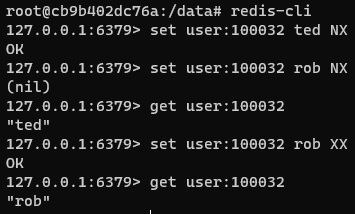
Estos comandos son útiles para manipular directamente los datos en Redis y administrar claves con caducidad.
Operadores en Listas
Redis también permite trabajar con listas, donde se pueden agregar, obtener o eliminar elementos de las listas. Los comandos más comunes para listas incluyen:
LPUSH: Inserta un valor al principio de una lista.RPUSH: Inserta un valor al final de una lista.LPOP: Elimina y devuelve el primer elemento de una lista.RPOP: Elimina y devuelve el último elemento de una lista.LRANGE: Recupera un rango de elementos de una lista.LLEN: Devuelve la longitud de una lista.LREM: Elimina elementos de una lista que coincidan con un valor dado.LINSERT: Inserta un valor antes o después de un elemento específico en una lista.LSET: Establece el valor de un elemento en una lista en una posición específica.LPOP: Elimina y devuelve el primer elemento de una lista.RPOP: Elimina y devuelve el último elemento de una lista.BLPOP: Bloquea una lista para obtener el primer elemento.BRPOP: Bloquea una lista para obtener el último elemento.LRANGEBYLEX: Devuelve un rango de elementos en una lista basado en orden lexicográfico.
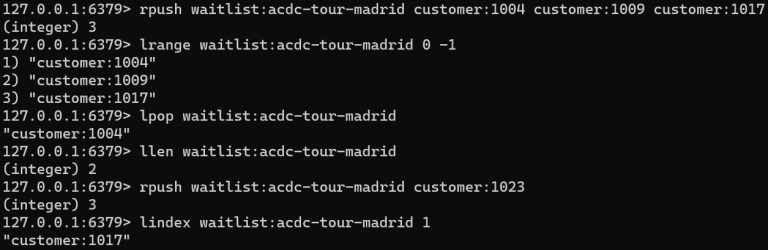
Operadores en Conjuntos
Los conjuntos en Redis son colecciones de elementos únicos. Los comandos para trabajar con conjuntos incluyen:
SADD: Agrega uno o más miembros a un conjunto.SREM: Elimina uno o más miembros de un conjunto.SMEMBERS: Devuelve todos los miembros de un conjunto.SISMEMBER: Verifica si un miembro está presente en un conjunto.SCARD: Devuelve el número de miembros en un conjunto.SPOP: Elimina y devuelve un miembro aleatorio de un conjunto.SRANDMEMBER: Devuelve un miembro aleatorio de un conjunto sin eliminarlo.SINTER: Devuelve la intersección de varios conjuntos.SINTERSTORE: Almacena la intersección de varios conjuntos en un nuevo conjunto.SUNION: Devuelve la unión de varios conjuntos.SUNIONSTORE: Almacena la unión de varios conjuntos en un nuevo conjunto.SDIFF: Devuelve la diferencia entre varios conjuntos.SDIFFSTORE: Almacena la diferencia entre varios conjuntos en un nuevo conjunto.SSCAN: Itera sobre los miembros de un conjunto.
Operadores en Hashes
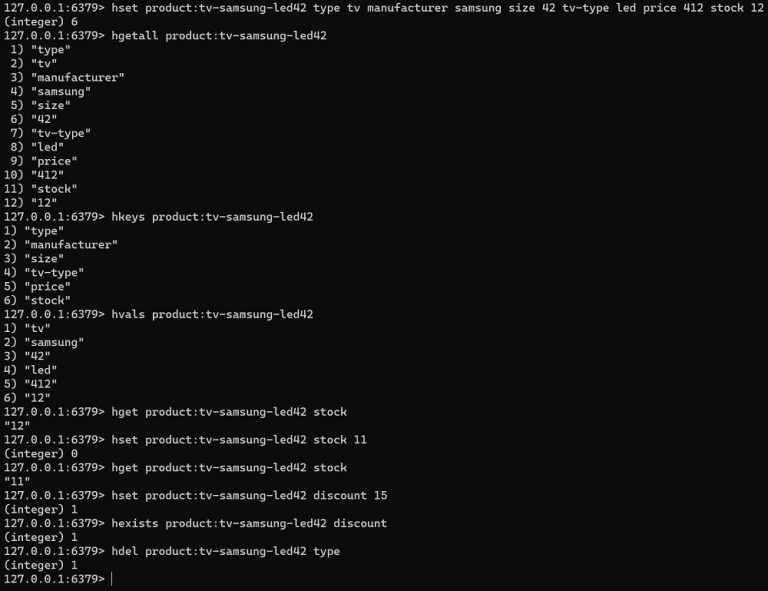
Los hashes en Redis son estructuras que almacenan pares de campo-valor. Algunos de los comandos más utilizados para manipular hashes incluyen:
HSET: Establece el valor de un campo en un hash.HGET: Obtiene el valor de un campo en un hash.HDEL: Elimina uno o más campos de un hash.HGETALL: Devuelve todos los campos y valores de un hash.HEXISTS: Verifica si un campo existe en un hash.HINCRBY: Incrementa el valor de un campo numérico en un hash.HINCRBYFLOAT: Incrementa el valor de un campo flotante en un hash.HMGET: Obtiene los valores de varios campos en un hash.HMSET: Establece múltiples campos en un hash (obsoleto, se recomienda usar HSET).HKEYS: Devuelve todos los campos de un hash.HVALS: Devuelve todos los valores de un hash.HSCAN: Itera sobre los campos y valores de un hash.HSTRLEN: Devuelve la longitud de un valor de campo en un hash.HSETNX: Establece el valor de un campo en un hash solo si el campo no existe.
Operadores en Sorted Sets
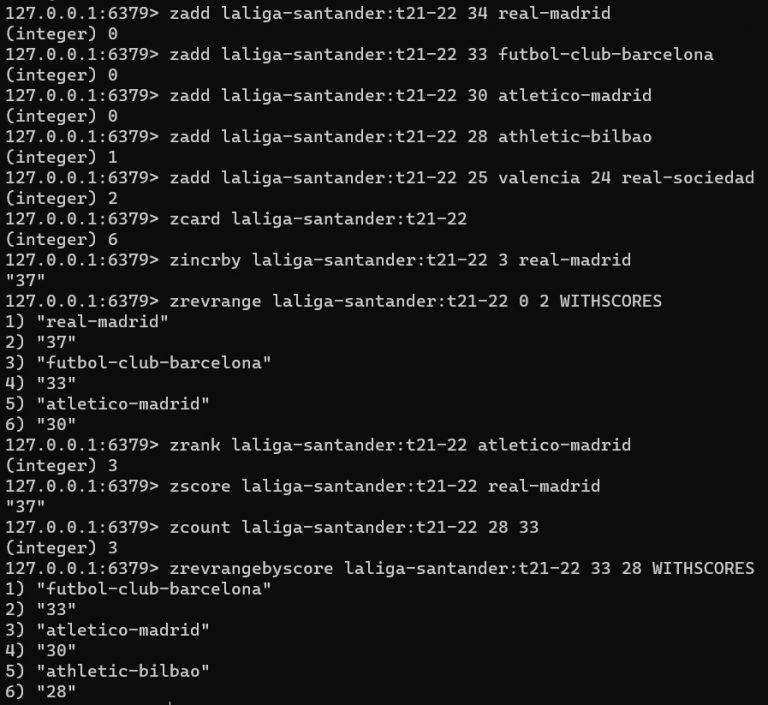
Los conjuntos ordenados en Redis permiten mantener un conjunto de elementos que son ordenados según una puntuación. Algunos de los comandos más comunes son:
ZADD: Agrega un miembro con una puntuación a un conjunto ordenado.ZRANGE: Devuelve un rango de miembros en un conjunto ordenado, ordenados por su puntuación.ZREM: Elimina uno o más miembros de un conjunto ordenado.ZINCRBY: Incrementa la puntuación de un miembro en un conjunto ordenado.ZREVRANGE: Devuelve un rango de miembros en un conjunto ordenado, ordenados en orden descendente de puntuación.ZCARD: Devuelve el número de miembros de un conjunto ordenado.ZLEXCOUNT: Cuenta los miembros en un conjunto ordenado dentro de un rango lexicográfico.ZREMRANGEBYRANK: Elimina los miembros de un conjunto ordenado dentro de un rango específico de índices.ZREMRANGEBYSCORE: Elimina los miembros de un conjunto ordenado dentro de un rango de puntuaciones específicas.ZMSCORE: Devuelve las puntuaciones de uno o más miembros en un conjunto ordenado.ZINTERSTORE: Realiza una intersección de múltiples conjuntos ordenados y almacena el resultado en un nuevo conjunto.ZUNIONSTORE: Realiza una unión de múltiples conjuntos ordenados y almacena el resultado en un nuevo conjunto.ZSCAN: Itera sobre los miembros de un conjunto ordenado para buscar por patrones.ZPOPMIN: Elimina y devuelve el miembro con la puntuación más baja de un conjunto ordenado.ZPOPMAX: Elimina y devuelve el miembro con la puntuación más alta de un conjunto ordenado.ZRANGEBYSCORE: Devuelve los miembros de un conjunto ordenado dentro de un rango de puntuaciones específicas.
Consultas Avanzadas en Redis
SCAN MGET PUBLISH HSCAN ZSCAN
SCAN se utiliza para iterar sobre las claves de Redis de manera eficiente sin bloquear el servidor. Por ejemplo:
Este comando devuelve todas las claves que comienzan con "user:". El comando se utiliza en una forma iterativa para evitar la sobrecarga del servidor.
MGET se utiliza para obtener los valores de múltiples claves a la vez. Por ejemplo:
Este comando devuelve los valores de las claves "user:1", "user:2" y "user:3" en una sola operación.
PUBLISH se utiliza para enviar un mensaje a un canal en Redis, permitiendo la comunicación entre suscriptores. Por ejemplo:
Este comando publica el mensaje "New article posted!" en el canal "news".
HSCAN se utiliza para iterar sobre los campos de un hash en Redis. Por ejemplo:
Este comando busca todos los campos en el hash "user:100" que contienen "email" en su nombre.
ZSCAN permite iterar sobre los elementos de un conjunto ordenado en Redis. Por ejemplo:
Este comando busca todos los miembros en el conjunto ordenado "ranking" que contienen "player" en su nombre.
Redis on Flash (RoF)
Redis on Flash extiende la capacidad de almacenamiento de Redis al permitir guardar datos menos utilizados (o "datos fríos") en dispositivos de almacenamiento SSD, mientras los datos más utilizados (o "datos calientes") permanecen en RAM. Este modelo combina la velocidad de Redis con el costo más bajo del almacenamiento en disco.
El sistema funciona dividiendo los datos:
Hot Data (Datos calientes): Residen en RAM para accesos frecuentes y rápidos.Cold Data (Datos fríos): Se almacenan en SSD para minimizar el uso de memoria cara, pero siguen siendo accesibles cuando se necesitan.
Redis on Flash utiliza algoritmos para gestionar automáticamente el intercambio de datos entre RAM y SSD, asegurando que las operaciones más críticas se mantengan rápidas.
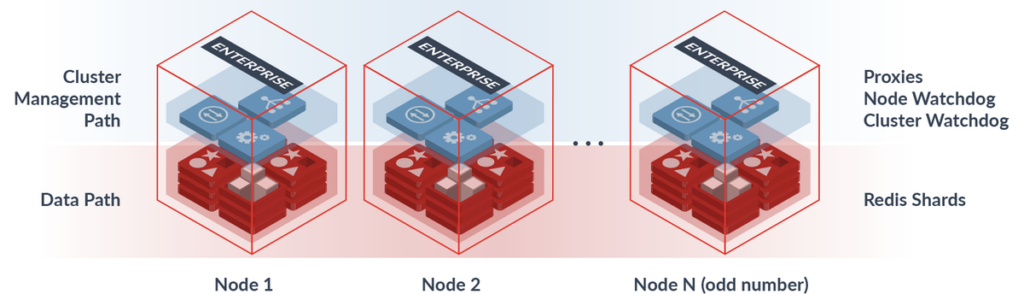
Redis Enterprise
Redis Enterprise proporciona una serie de características avanzadas que mejoran la capacidad de Redis para funcionar en entornos empresariales. Estas incluyen:
Escalabilidad horizontal: Permite escalar de manera eficiente mediante la adición de nodos adicionales sin afectar el rendimiento.Alta disponibilidad: Ofrece mecanismos de replicación, failover automático y recuperación ante desastres.Soporte multi-modelo: Redis Enterprise admite múltiples modelos de datos, incluidos Strings, Hashes, Listas, Sets, Sorted Sets, Streams, y más.Seguridad avanzada: Incluye cifrado en tránsito y en reposo, control de acceso granular y autenticación basada en roles.Desempeño optimizado: Redis Enterprise está diseñado para ofrecer un rendimiento de baja latencia con altos volúmenes de operaciones por segundo.Persistencia mejorada: Ofrece persistencia avanzada con características como Redis on Flash y persistencia sin pérdidas de datos.Multi-cloud y despliegue híbrido: Redis Enterprise soporta la implementación en múltiples nubes y entornos híbridos.
Redis Enterprise está diseñado para integrarse con las principales plataformas en la nube, como AWS, Azure y Google Cloud, y proporciona una solución ideal para aplicaciones que requieren una alta disponibilidad, rendimiento y escalabilidad.
Ejemplo práctico de uso
Para empezar a trabajar con Redis, primero necesitamos instalarlo en nuestro sistema. Redis puede instalarse en diversas plataformas, incluyendo Linux, macOS y Windows. Además, Redis ofrece un cliente que puede interactuar con él utilizando comandos en la línea de comandos o a través de librerías para lenguajes de programación como Python, Java, Node.js, entre otros.
La instalación de Redis varía según el sistema operativo. Aquí te dejamos una guía básica para instalarlo en algunos de los sistemas más comunes:
Instalación en Linux





Instalación en Windows
En Windows, puedes usar el Subsistema de Windows para Linux (WSL) para ejecutar Redis o utilizar una versión precompilada desde el sitio web de Redis.
A continuación se presenta un ejemplo de cómo usar Redis en una aplicación Python utilizando la librería redis-py:
Luego, puedes crear un cliente Redis en Python de la siguiente manera:
Este código conecta a Redis, establece un valor asociado a la clave "foo" y luego recupera ese valor.