SQL
SQL, que significa Structured Query Language (Lenguaje de Consulta Estructurada), es un lenguaje de programación diseñado específicamente para gestionar y manipular bases de datos relacionales. A través de SQL, los usuarios pueden realizar consultas, recuperar datos, insertar registros, actualizar información y eliminar datos almacenados en una base de datos. SQL ha sido el estándar de facto desde los años 70 y sigue siendo una parte fundamental de cualquier sistema que maneje grandes volúmenes de información.
SQL no es un lenguaje de programación completo como Python o Java. En lugar de eso, es un lenguaje declarativo, lo que significa que describes lo que quieres obtener, pero no cómo lograrlo. La base de datos se encarga de optimizar la ejecución de la consulta para devolver el resultado solicitado.

Tipos de bases de datos
Las bases de datos se pueden clasificar de varias formas, pero una distinción importante es entre bases de datos relacionales y no relacionales.
Bases de datos relacionales
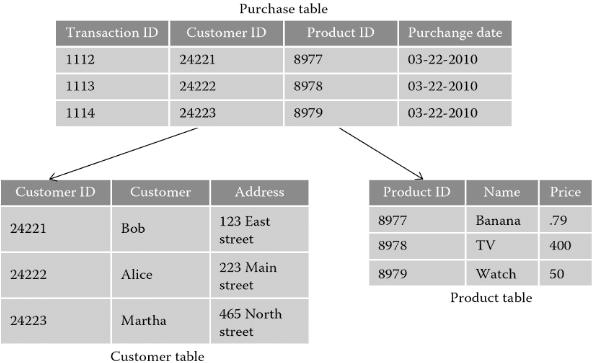
Las bases de datos relacionales son aquellas que organizan la información en tablas, donde los datos están relacionados entre sí mediante claves primarias y externas. Cada fila de una tabla representa un registro, y cada columna representa un atributo o campo de ese registro. Las bases de datos relacionales permiten realizar operaciones avanzadas que relacionan diferentes tablas entre sí. SQL es el lenguaje de consulta principal para este tipo de bases de datos. Ejemplos incluyen:
- MySQL
- PostgreSQL
- SQL Server
- Oracle
Bases de datos no relacionales
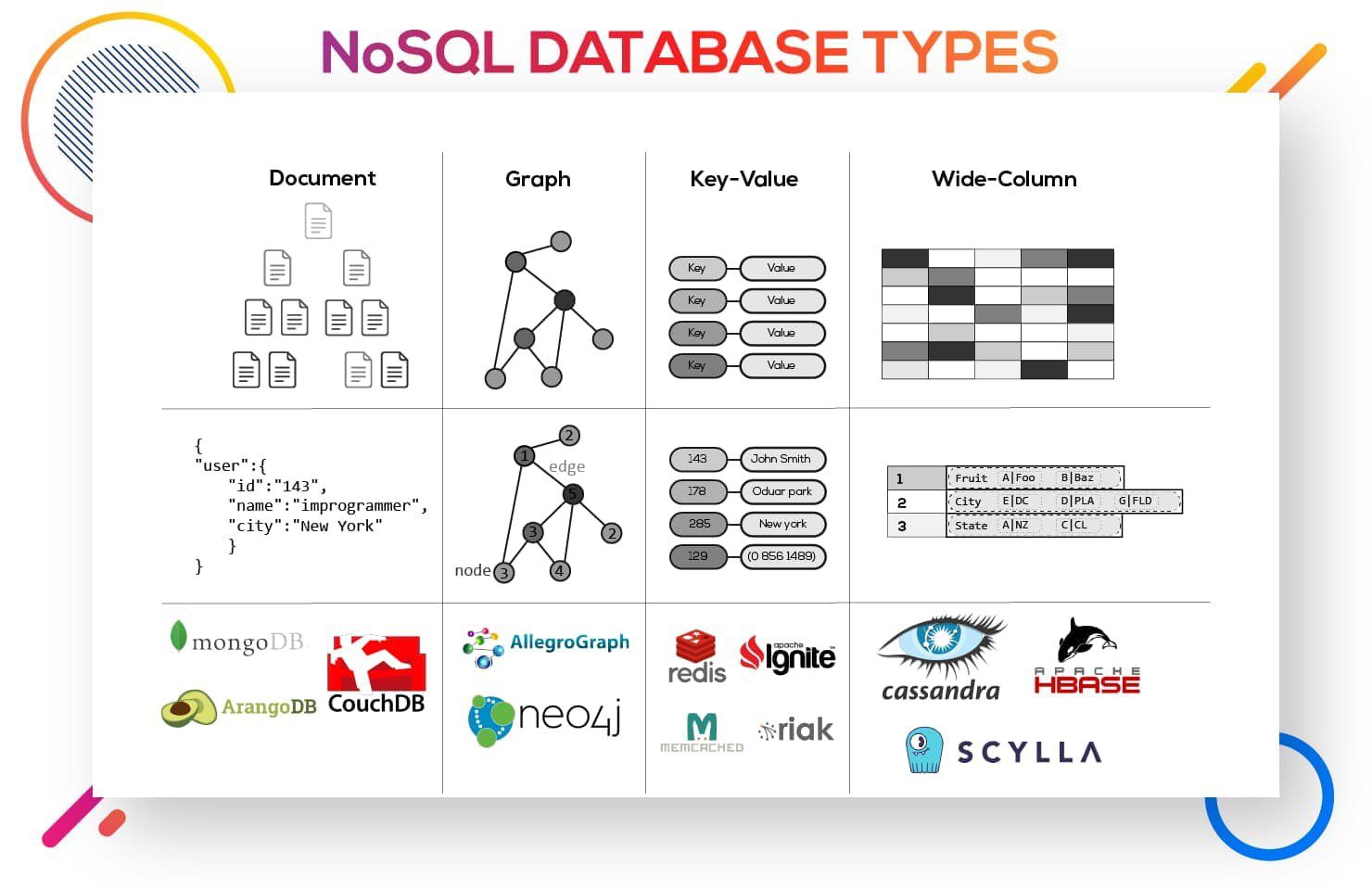
Por otro lado, las bases de datos no relacionales, también conocidas como NoSQL, no organizan los datos en tablas estructuradas. En su lugar, utilizan otros modelos como documentos, grafos o estructuras clave-valor. Este tipo de bases de datos es más flexible para manejar grandes cantidades de datos no estructurados y es común en aplicaciones modernas que requieren alta escalabilidad y flexibilidad. Ejemplos incluyen:
- MongoDB (documentos)
- Redis (clave-valor)
- Neo4j (grafos)
El funcionamiento de las tablas
Las tablas son el componente principal de una base de datos relacional. Cada tabla está organizada en filas y columnas, donde las filas representan un registro individual y las columnas definen los atributos de ese registro. Por ejemplo, en una tabla de empleados, las columnas podrían ser el "nombre", "apellido", "departamento", y "fecha de contratación". Cada fila contendría la información de un empleado en particular.
Las tablas en una base de datos relacional están interconectadas a través de relaciones, lo que permite vincular datos de diferentes tablas utilizando claves. Existen principalmente tres tipos de relaciones:
Uno a uno: Un registro en una tabla está relacionado con un único registro en otra tabla.Uno a muchos: Un registro en una tabla puede estar relacionado con varios registros en otra tabla.Muchos a muchos: Varios registros en una tabla pueden estar relacionados con varios registros en otra tabla.
Tipos de datos
SQL permite almacenar diferentes tipos de datos en sus tablas. Al definir las columnas de una tabla, cada una debe ser asignada a un tipo de dato específico, que determina qué tipo de información puede contener y cómo se puede manejar. Los principales tipos de datos que SQL admite incluyen:
Númericos INT: Almacena números enteros, como 1, 100 o -500.DECIMAL (o NUMERIC): Almacena números decimales con una precisión fija. Es útil para manejar cantidades de dinero, ya que evita errores de redondeo.FLOAT: Almacena números de punto flotante, lo que permite trabajar con números más grandes o más pequeños, pero con menor precisión.Cadenas de texto VARCHAR: Almacena cadenas de texto de longitud variable. Es adecuado para nombres, descripciones o cualquier campo donde la longitud pueda variar.CHAR: Similar a VARCHAR, pero con longitud fija. Si se definen 10 caracteres, cualquier cadena menor se rellenará con espacios.TEXT: Permite almacenar grandes cantidades de texto, como comentarios o descripciones extensas.Fechas y tiempos DATE: Almacena solo la fecha en formato AAAA-MM-DD.TIME: Almacena solo la hora en formato HH:MM:SS.DATETIME: Almacena tanto la fecha como la hora.TIMESTAMP: Similar a DATETIME, pero también registra la zona horaria y cambios automáticos cuando se actualizan los datos.Booleanos BOOLEAN: Almacena valores TRUE o FALSE. Algunos motores de bases de datos lo implementan como enteros, donde 0 representa FALSE y 1 representa TRUE.Otros BLOB: Almacena grandes cantidades de datos binarios, como imágenes, videos o archivos ejecutables.ENUM: Permite definir una lista de valores posibles. Por ejemplo, una columna "estado" podría aceptar solo "activo", "inactivo" o "pendiente".
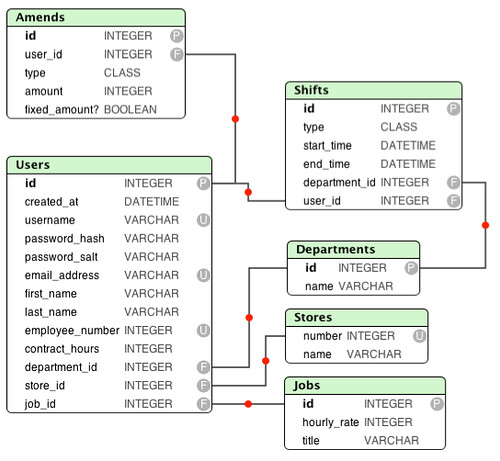
Claves y restricciones
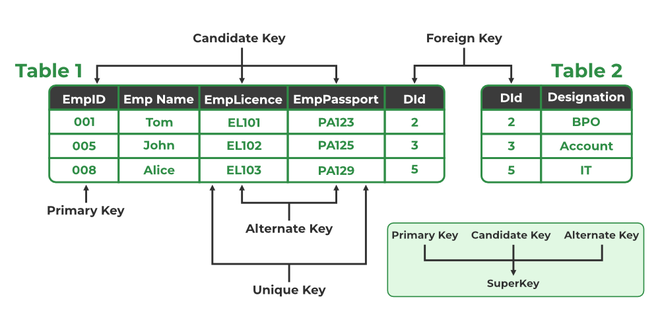
Clave primaria (Primary Key)
Cada tabla en una base de datos relacional debe tener una columna o conjunto de columnas que actúe como clave primaria. Esta clave debe ser única para cada registro y no puede contener valores nulos. Las claves primarias son esenciales para identificar de manera única cada fila en una tabla.
Clave externa (Foreign Key)
Las claves externas son columnas que crean una relación entre dos tablas. Una clave externa en una tabla hace referencia a la clave primaria de otra, lo que permite vincular registros de diferentes tablas y mantener la integridad referencial.
Restricciones
SQL también permite definir restricciones que aseguran que los datos almacenados sigan ciertas reglas. Algunas restricciones comunes incluyen:
NOT NULL: Evita que una columna contenga valores nulos.UNIQUE: Garantiza que todos los valores en una columna sean únicos.DEFAULT: Establece un valor predeterminado si no se especifica uno al insertar un nuevo registro.
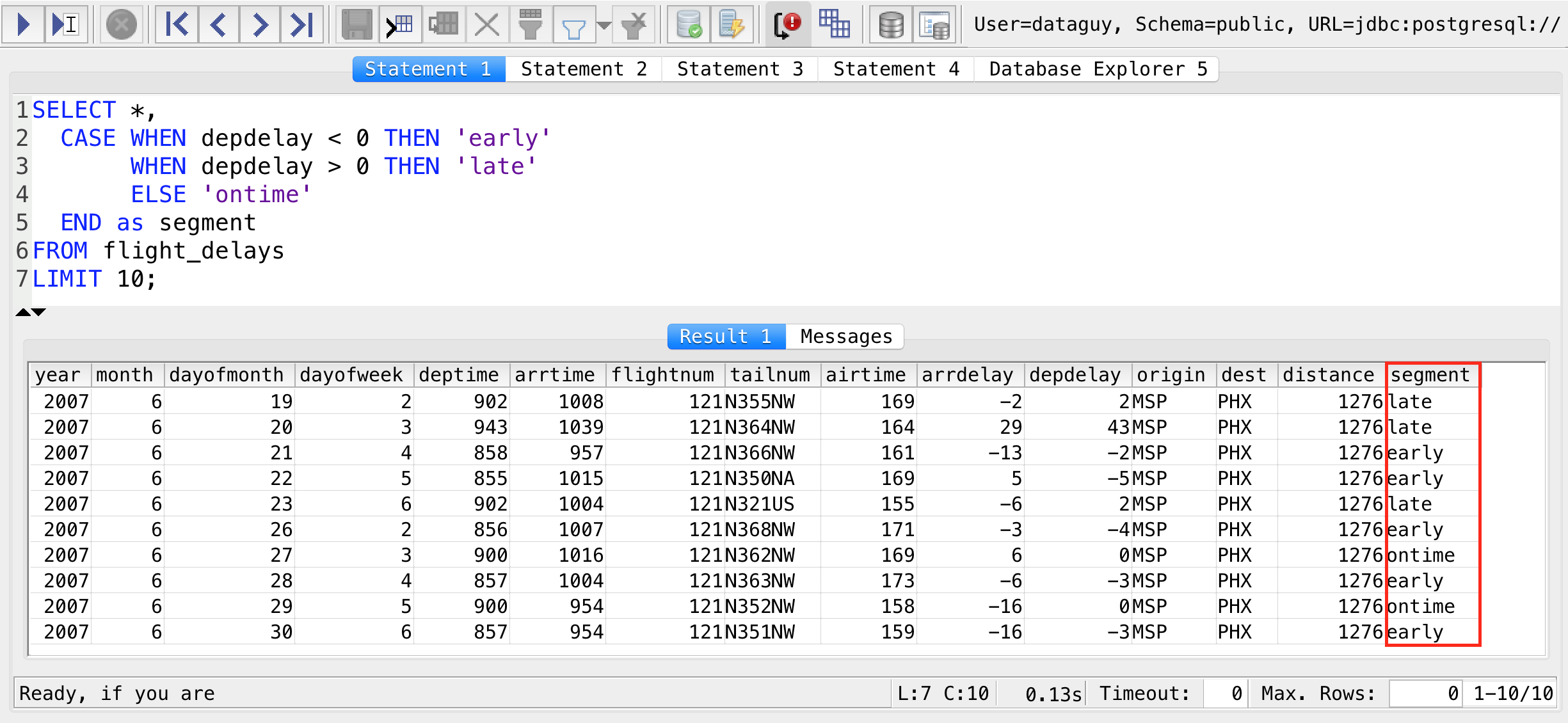
Operaciones comunes en SQL
Operaciones DML (Data Manipulation Language)
Estas operaciones están relacionadas con la manipulación de los datos dentro de las tablas. Los comandos DML permiten recuperar, insertar, actualizar y eliminar datos.
SELECT INSERT UPDATE DELETE MERGE
Esta consulta extrae todos los campos (representados por *) de la tabla empleados donde el valor de la columna salario es mayor a 5000. La tabla empleados forma parte de una base de datos más grande que contiene la información de los empleados de una empresa. En términos generales, esta consulta obtiene todos los datos (nombre, apellido, salario, departamento, etc.) de aquellos empleados cuyo salario supera los 5000.
Inserta un nuevo registro en la tabla empleados, que está en la base de datos de la empresa. Este registro agrega a un nuevo empleado con el nombre "Carlos", apellido "Lopez" y departamento "Finanzas". En términos prácticos, esta operación añade un nuevo empleado a la lista de empleados almacenada en la tabla.
Actualiza los datos de la tabla empleados para incrementar el salario en un 10% para todos los empleados que trabajan en el departamento de Ventas. En la base de datos, esta tabla contiene los detalles de los empleados, y esta consulta modifica solo los salarios de aquellos que pertenecen al departamento especificado.
Elimina el registro de la tabla empleados donde el valor de la columna nombre es igual a "Carlos". La tabla empleados es parte de la base de datos, y esta operación elimina por completo la información de un empleado llamado "Carlos". En términos generales, esta consulta borra a un empleado específico de la base de datos.
Combina operaciones de INSERT y UPDATE en una sola sentencia. Dependiendo de si los datos ya existen o no, actualiza o inserta nuevos registros.
 C:\Windows\system32\cmd.exe
C:\Windows\system32\cmd.exe
MERGE INTO empleados AS destino
USING nuevos_empleados AS fuente
ON destino.id = fuente.id
WHEN MATCHED THEN
UPDATE SET destino.salario = fuente.salario
WHEN NOT MATCHED THEN
INSERT (id, nombre, salario) VALUES (fuente.id, fuente.nombre, fuente.salario);Combina las tablas empleados (tabla destino en la base de datos actual) y nuevos_empleados (tabla fuente). Si un empleado en la tabla empleados tiene el mismo id que en la tabla nuevos_empleados, la consulta actualiza el salario. Si no hay coincidencia, agrega un nuevo empleado. Esta consulta asegura que la tabla de empleados esté actualizada con la información de nuevos empleados o con cambios en los salarios.
Operaciones DDL (Data Definition Language)
Estas operaciones se usan para definir la estructura de las tablas, índices y otros objetos dentro de la base de datos. Los comandos DDL permiten crear, modificar y eliminar la estructura de la base de datos.
CREATE ALTER DROP TRUNCATE RENAME
Crea una nueva tabla, vista, índice, o cualquier otro objeto de base de datos.
C:\Windows\system32\cmd.exe
CREATE TABLE empleados (
id INT PRIMARY KEY,
nombre VARCHAR(50),
apellido VARCHAR(50),
salario DECIMAL(10, 2)
);Crea una nueva tabla llamada empleados en la base de datos. La tabla tendrá las columnas id, nombre, apellido y salario, con la columna id actuando como la clave primaria. La base de datos puede estar gestionando la información de una empresa, y esta tabla está diseñada para almacenar los datos de los empleados. Esta operación establece la estructura que define cómo se almacenará la información sobre los empleados.
Modifica la estructura de la tabla empleados para añadir una nueva columna llamada fecha_contratacion de tipo DATE. Esta tabla, que forma parte de una base de datos de empleados, ahora incluirá también la fecha en que cada empleado fue contratado. En términos generales, la consulta ajusta la tabla para adaptarse a nueva información que será almacenada.
Elimina completamente la tabla empleados de la base de datos. Esto borra tanto la estructura como todos los datos almacenados en esa tabla. En términos prácticos, todos los registros de empleados en la base de datos desaparecerán junto con la tabla.
Elimina todos los registros de la tabla empleados pero mantiene su estructura. La tabla seguirá existiendo en la base de datos, lista para recibir nuevos datos, pero todos los registros actuales de empleados se eliminarán. Esta operación es más rápida que un DELETE masivo.
Cambia el nombre de la tabla empleados a personal dentro de la base de datos. Esto es útil si el nombre de la tabla necesita ser más representativo de su contenido, como cambiar el nombre de una tabla que almacena datos de empleados.
Operaciones DCL (Data Control Language)
Estas operaciones están relacionadas con el control de permisos de acceso a los datos. Los comandos DCL permiten otorgar o revocar privilegios a los usuarios.
GRANT REVOKE
Otorga permisos al usuario usuario1 para que pueda realizar consultas y agregar registros a la tabla empleados en la base de datos. Esto asegura que ciertos usuarios tengan los privilegios adecuados para interactuar con la información de empleados.
Revoca el permiso de usuario1 para insertar nuevos registros en la tabla empleados. En la base de datos, esto garantiza que el usuario en cuestión ya no pueda modificar los datos de empleados agregando nuevos registros.
Operaciones TCL (Transaction Control Language)
Estas operaciones están relacionadas con el manejo de transacciones dentro de una base de datos. Las transacciones agrupan una o más operaciones DML en una única unidad de trabajo.
COMMIT ROLLBACK SAVEPOINT RELEASE SAVEPOINT SET TRANSACTION
Confirma los cambios realizados en una transacción. En la base de datos de empleados, esta operación asegura que cualquier inserción, actualización o eliminación que se haya hecho desde que comenzó la transacción sea permanente. Si se ejecuta después de una serie de modificaciones, estas se consolidarán en la base de datos.
Deshace todos los cambios realizados desde el inicio de la transacción. Si se hacen modificaciones en la tabla empleados pero algo sale mal, esta operación restaura la base de datos a su estado anterior a la transacción.
Crea un punto de restauración dentro de una transacción en la base de datos. Esto es útil si, al trabajar con la tabla empleados, se necesita deshacer solo parte de una transacción sin revertir todo el proceso.
Elimina el punto de restauración llamado punto1 creado previamente. En términos generales, una vez que se ha determinado que ya no se necesita ese punto de restauración, se libera para optimizar el uso de la base de datos.
Establece el nivel de aislamiento para la transacción actual, asegurando que no haya interferencias de otras transacciones concurrentes en la base de datos. Esto es útil cuando se trabaja con tablas críticas, como la tabla empleados, donde los datos deben estar bien protegidos frente a modificaciones simultáneas.
Otras Operaciones Útiles en SQL
EXPLAIN ANALYZE
Muestra el plan de ejecución de la consulta, lo que permite saber cómo la base de datos accederá a la tabla empleados para extraer los datos. Esto es útil para optimizar la velocidad de consulta en una base de datos grande.
Recopila estadísticas sobre la tabla empleados para ayudar al optimizador de consultas a generar planes más eficientes. Mejora el rendimiento de futuras consultas sobre los datos de empleados.
Funciones y operadores
Las funciones en SQL son herramientas que permiten realizar cálculos o manipular datos de manera más eficiente dentro de una consulta. Estas funciones se agrupan en dos categorías principales: funciones de agregación y funciones escalares. Las funciones son extremadamente útiles para hacer análisis, transformaciones de datos y obtener resultados específicos a partir de los datos almacenados en las tablas de la base de datos.
Funciones de Agregación
Las funciones de agregación toman múltiples valores de una columna y los procesan para devolver un solo valor de resumen. Son ideales cuando necesitas analizar un conjunto de datos o agrupar información.
SUM: Suma los valores de una columna numérica.AVG: Calcula el promedio de los valores de una columna.COUNT: Cuenta el número de filas o registros que coinciden con una condición específica.MIN y MAX: Encuentran el valor mínimo o máximo dentro de una columna.
Estas funciones se usan frecuentemente junto con la cláusula GROUP BY, que permite agrupar los datos por una o más columnas antes de aplicar la función de agregación. Son útiles para responder preguntas como: "¿Cuál es el salario promedio en el departamento de ventas?" o "¿Cuántos empleados hay en cada departamento?".
Funciones Escalares
A diferencia de las funciones de agregación, las funciones escalares trabajan sobre una sola fila y devuelven un valor único basado en los datos de esa fila. Estas son muy útiles cuando necesitas manipular o transformar datos dentro de una consulta.
LCASE y UCASE: Convierte cadenas de texto a minúsculas o mayúsculas.CONCAT: Une dos o más cadenas en una sola.SUBSTRING: Extrae una parte de una cadena de texto.ROUND: Redondea un número a un número específico de decimales.NOW: Devuelve la fecha y hora actual del sistema.
Estas funciones son útiles para tareas como limpiar o formatear datos, realizar cálculos numéricos, o trabajar con fechas y horas.
Operadores
SQL tiene varios operadores para realizar cálculos y comparaciones. Algunos comunes son:
- =: Igual a
- !=: Distinto a
- >: Mayor que
- <: Menor que
- >=: Mayor o igual que
- <=: Menor o igual que
- +, -, *, /: Operadores aritméticos para sumar, restar, multiplicar y dividir.
Queries Avanzadas
DISTINCT UNION GROUP BY WHERE LIKE BETWEEN HAVING AND, OR, NOT IN ANY, ALL EXISTS JOIN INNER JOIN LEFT JOIN RIGHT JOIN FULL JOIN
Esta consulta recupera todos los departamentos únicos de la tabla empleados. Si dos o más empleados pertenecen al mismo departamento, este solo se mostrará una vez.
Esta consulta devuelve una lista de nombres de ambas tablas, eliminando duplicados. Si deseas mantener duplicados, usa UNION ALL.
Agrupa a los empleados por departamento y cuenta cuántos empleados hay en cada uno.
Devuelve todos los empleados cuya edad es mayor a 30.
Esta consulta obtiene los empleados cuyos nombres comienzan con la letra "A". El símbolo % es un comodín que representa cero o más caracteres.
Esta consulta obtiene los empleados cuyo salario está entre 3000 y 6000.
Esto muestra los departamentos con un salario promedio superior a 6000.
Devuelve los empleados cuyo salario es mayor a 5000 y pertenecen al departamento de Ventas. OR devuelve registros si al menos una condición es verdadera, mientras que NOT invierte el resultado de la condición.
Esta consulta obtiene los empleados que trabajan en los departamentos de Ventas o Marketing.
Aquí se obtienen los nombres de empleados que tienen un salario mayor que el de cualquier empleado del departamento de IT. ALL requiere que se cumpla la condición para todos los resultados de la subconsulta.
En esta consulta, la tabla principal es empleados, y estamos seleccionando la columna nombre de esta tabla. La cláusula WHERE EXISTS contiene una subconsulta que actúa como un filtro para los resultados que queremos obtener. La subconsulta busca en la tabla proyectos y verifica si hay al menos una fila donde el empleados.id coincide con proyectos.empleado_id. El uso de SELECT 1 en la subconsulta es solo una convención; no necesitamos seleccionar datos específicos, solo estamos interesados en saber si existen filas que cumplen la condición.
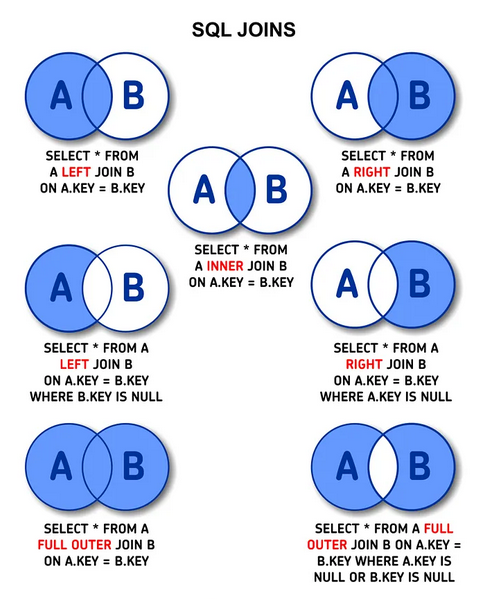
Los joins en SQL son fundamentales para combinar filas de dos o más tablas en función de una relación entre ellas. Este proceso es esencial en bases de datos relacionales, donde los datos están estructurados en múltiples tablas que se pueden relacionar entre sí.
C:\Windows\system32\cmd.exe
SELECT empleados.nombre, departamentos.nombre
FROM empleados
JOIN departamentos ON empleados.depto_id = departamentos.id;La tabla empleados contiene datos sobre los trabajadores, donde la columna empleados.nombre hace referencia a los nombres de cada empleado. Por otro lado, la tabla departamentos incluye la columna departamentos.nombre, que muestra el nombre de cada departamento. La cláusula ON empleados.depto_id = departamentos.id establece la relación entre ambas tablas, indicando que deseamos combinar filas donde el depto_id de la tabla empleados coincide con el id de la tabla departamentos. Esto implica que, para cada empleado, se buscará el departamento correspondiente en la tabla departamentos en función del depto_id. Si se encuentra una coincidencia, el resultado incluirá tanto el nombre del empleado como el nombre del departamento asociado.
INNER JOIN es un tipo de unión que combina filas de dos o más tablas basándose en una condición común. Solo devuelve las filas que tienen coincidencias en ambas tablas.
C:\Windows\system32\cmd.exe
SELECT empleados.nombre, departamentos.nombre
FROM empleados
INNER JOIN departamentos ON empleados.depto_id = departamentos.id;En esta consulta, comenzamos con la tabla empleados, que contiene información sobre los empleados de una empresa. Usamos INNER JOIN para unir esta tabla con la tabla departamentos, que tiene datos sobre cada departamento. La cláusula ON es donde establecemos la relación entre las dos tablas. Aquí, estamos diciendo que queremos unir las filas donde el depto_id de la tabla empleados coincide con el id de la tabla departamentos.
LEFT JOIN es un tipo de unión que devuelve todas las filas de la tabla de la izquierda y las filas coincidentes de la tabla de la derecha. Si no hay coincidencias, se rellenan las columnas de la tabla de la derecha con NULL.
C:\Windows\system32\cmd.exe
SELECT empleados.nombre, departamentos.nombre
FROM empleados
LEFT JOIN departamentos ON empleados.depto_id = departamentos.id;RIGHT JOIN es un tipo de unión que devuelve todas las filas de la tabla de la derecha y las filas coincidentes de la tabla de la izquierda. Si no hay coincidencias, se rellenan las columnas de la tabla de la izquierda con NULL.
C:\Windows\system32\cmd.exe
SELECT empleados.nombre, departamentos.nombre
FROM empleados
RIGHT JOIN departamentos ON empleados.depto_id = departamentos.id;FULL JOIN es un tipo de unión que combina el comportamiento de LEFT JOIN y RIGHT JOIN, devolviendo todas las filas de ambas tablas. Si no hay coincidencias, las columnas no coincidentes se rellenan con NULL.
C:\Windows\system32\cmd.exe
SELECT empleados.nombre, departamentos.nombre
FROM empleados
FULL JOIN departamentos ON empleados.depto_id = departamentos.id;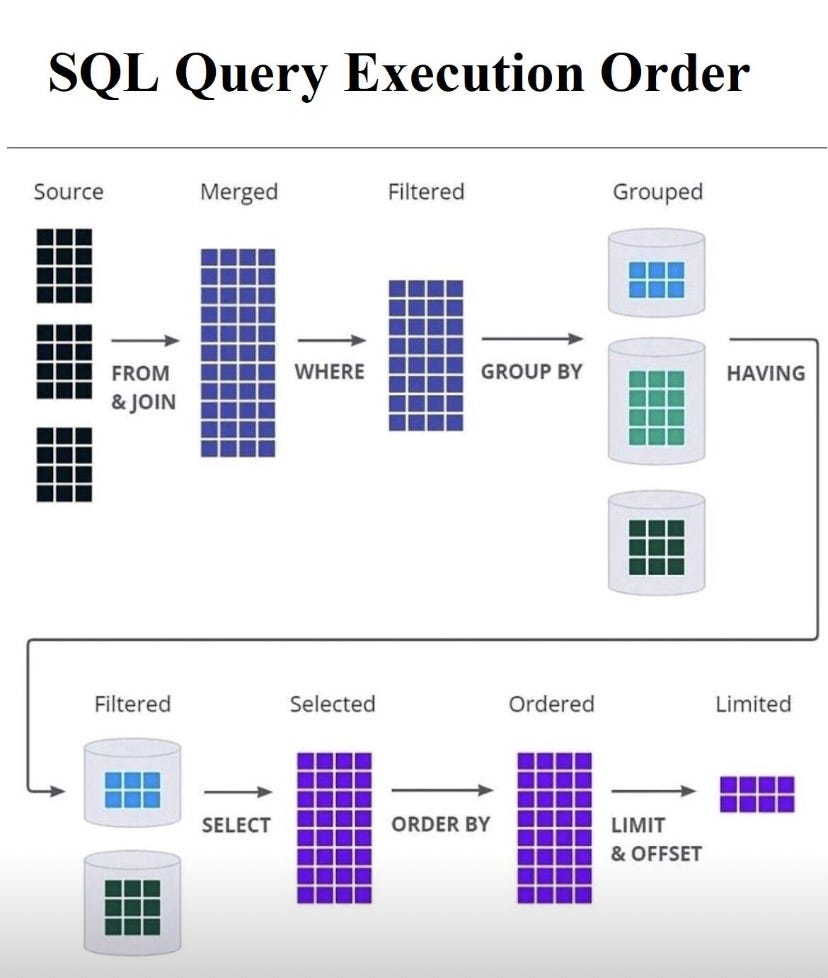
Formateo
El formateo de consultas SQL es esencial para mejorar la legibilidad, especialmente en queries muy largas o complejas. Utilizar sangrías y saltos de línea ayuda a estructurar mejor la consulta, facilitando la identificación de sus diferentes partes, como las cláusulas SELECT, FROM, WHERE, y los JOIN. Al hacerlo, los desarrolladores pueden comprender más fácilmente la lógica de la consulta y realizar modificaciones sin confusiones. Una práctica común es alinear las cláusulas principales y anidar condiciones en subconsultas o expresiones de forma ordenada. Por ejemplo, una consulta compleja se puede formatear así:
C:\Windows\system32\cmd.exe
SELECT
empleados.nombre,
departamentos.nombre
FROM
empleados
LEFT JOIN
departamentos ON empleados.depto_id = departamentos.id
WHERE
empleados.salario > 5000
ORDER BY
empleados.nombre;Para formatear código SQL, puedes utilizar herramientas en línea como SQL Formatter. Este tipo de herramientas permite pegar tu código SQL y obtener una versión bien estructurada automáticamente, mejorando la presentación y claridad del código.
w3schools
W3Schools es una excelente plataforma educativa en línea que ofrece tutoriales y recursos para aprender SQL. A través de W3Schools puedes aprender desde conceptos básicos, como crear tablas y realizar consultas sencillas, hasta conceptos más avanzados, como trabajar con funciones, vistas, y transacciones. Una de las ventajas de W3Schools es que proporciona un editor en línea donde puedes practicar las consultas SQL directamente desde tu navegador sin necesidad de configurar una base de datos en tu equipo.
Al usar W3Schools, puedes explorar las funciones de SQL en su sección de "SQL Functions". Cada función está explicada con ejemplos claros y fáciles de seguir, lo que permite ver cómo funciona en la práctica. Esto es especialmente útil si estás comenzando a aprender SQL y quieres ver cómo diferentes funciones pueden aplicarse a tus propios datos o a proyectos más grandes. Además, W3Schools ofrece pequeñas pruebas interactivas para consolidar lo aprendido.
Puedes consultar las funciones de SQL, así como aprender sobre el lenguaje en W3Schools.