



Algoritmos de Machine Learning
La inteligencia artificial (IA) ha experimentado un crecimiento exponencial en los últimos años, y dos de sus pilares fundamentales son el Machine Learning y el Deep Learning. Estos enfoques se utilizan para enseñar a las máquinas cómo aprender patrones y tomar decisiones de manera autónoma. Veamos en qué consisten y cómo se diferencian.
El Machine Learning, o aprendizaje automático, es una rama de la IA que permite a las computadoras aprender de datos y experiencias pasadas para tomar decisiones sin ser programadas explícitamente. Los algoritmos de Machine Learning pueden clasificarse en dos categorías principales: supervisados y no supervisados.
Algoritmos Supervisados: Aprendizaje con guía
Los algoritmos de Machine Learning supervisados se basan en datos de entrenamiento etiquetados, es decir, datos con respuestas conocidas. Uno de los algoritmos más simples y comunes en esta categoría es la Regresión Lineal. Este algoritmo busca establecer una relación lineal entre las variables para predecir valores numéricos.
Otro algoritmo supervisado popular es la Regresión Logística, que se utiliza para clasificar datos en dos categorías (por ejemplo, sí o no). Su uso es común en problemas de clasificación binaria.
Árboles de Decisión y Random Forest son otros algoritmos supervisados que permiten tomar decisiones basadas en una serie de condiciones y características.
Algoritmos No Supervisados: Descubrimiento de patrones
Los algoritmos de Machine Learning no supervisados trabajan con datos no etiquetados, y su objetivo principal es encontrar patrones y estructuras en los datos. K-Nearest Neighbors (KNN) es un algoritmo no supervisado que clasifica datos nuevos basándose en la similitud con los vecinos más cercanos.
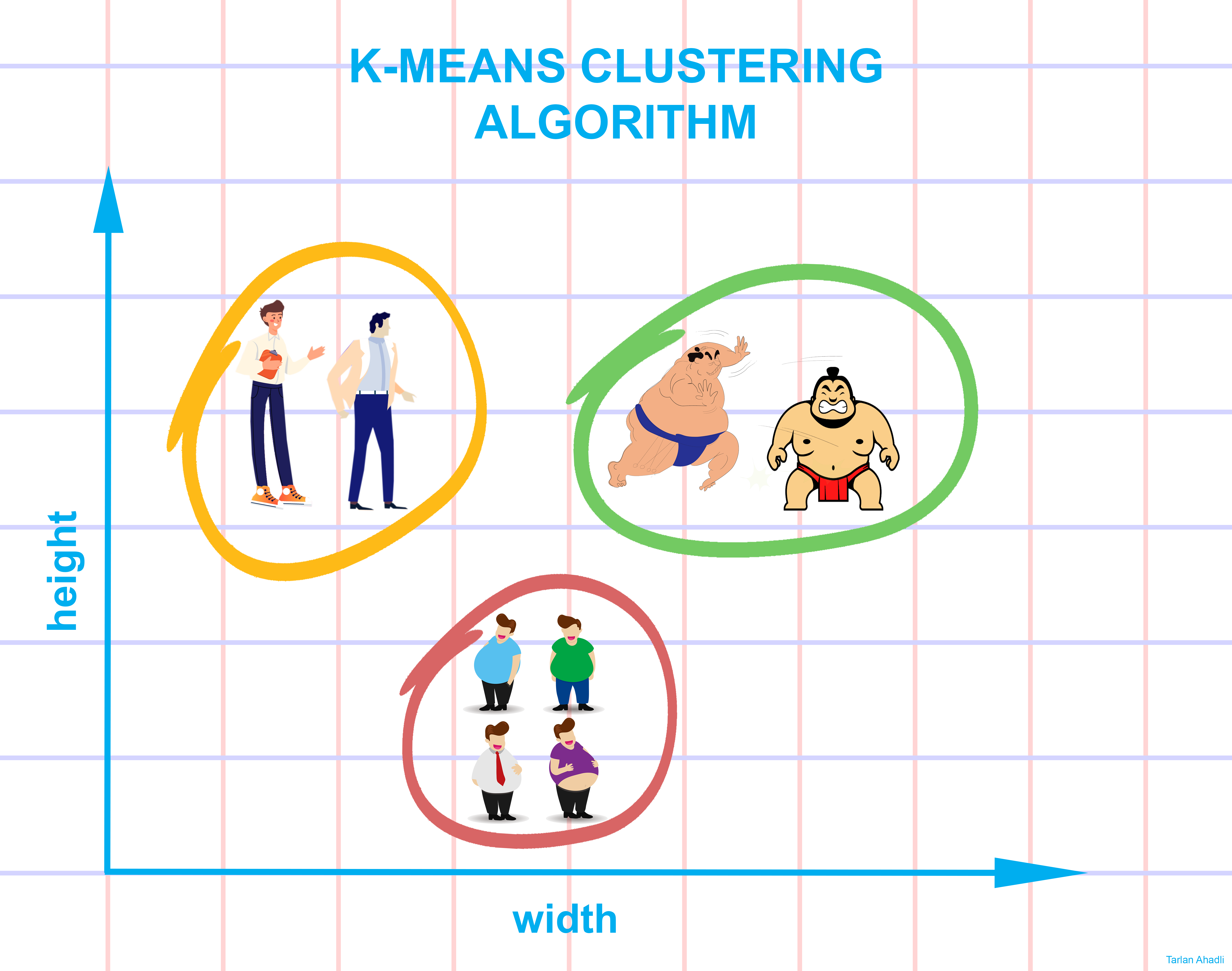
K-Means es un algoritmo de agrupamiento que divide los datos en grupos o clústeres basados en su similitud, mientras que DBSCAN identifica clústeres en datos de alta densidad.
Naive Bayes es otro algoritmo no supervisado que se utiliza comúnmente en clasificación de textos y filtrado de spam.
Deep Learning: Aprendizaje automático
El Deep Learning, o aprendizaje profundo, es una rama del Machine Learning que se basa en redes neuronales artificiales (ANN). Estas redes son inspiradas por la estructura y funcionamiento del cerebro humano y permiten aprender representaciones de alto nivel a partir de los datos.
Redes Neuronales Artificiales (ANN): Estas redes están compuestas por capas de neuronas interconectadas, y cada neurona procesa información y pasa el resultado a la siguiente capa. Las capas iniciales aprenden características simples, mientras que las capas más profundas aprenden características más complejas.Redes Neuronales Convolucionales (CNN): Especializadas en el procesamiento de imágenes, las CNN utilizan filtros y convoluciones para identificar patrones visuales y objetos.Redes Neuronales Recurrentes (RNN): Diseñadas para trabajar con secuencias de datos, como texto o audio. Las RNN tienen conexiones que forman bucles para mantener una memoria temporal, lo que las hace adecuadas para tareas de procesamiento del lenguaje natural y traducción automática.
Aprendizaje por Refuerzo (Reinforcement Learning): En este enfoque, los algoritmos aprenden a través de la interacción con un entorno. Reciben recompensas o penalizaciones según sus acciones y buscan maximizar la recompensa a lo largo del tiempo.
Funcionamiento
Los algoritmos de Machine Learning son como cerebros electrónicos que aprenden de datos para tomar decisiones sin ser programados explícitamente. Analizan patrones y tendencias en la información para ofrecer predicciones y soluciones precisas, impulsando la inteligencia artificial hacia nuevas fronteras. Ahora, desentrañaremos su fascinante funcionamiento y descubriremos cómo transforman datos en conocimiento poderoso.
Algoritmos Supervisados Algoritmos No Supervisados Regresión Lineal Regresión Logística Árboles de Decisión Random Forest K-Nearest Neighbors (KNN) Support Vector Machines (SVM) Naive Bayes Seleccionar las características relevantes: Primero, necesitas identificar las características que utilizarás para clasificar los elementos. Por ejemplo, en el caso de clasificar correos electrónicos como spam o no spam, podrías considerar características como la frecuencia de ciertas palabras.Calcular las probabilidades: Naive Bayes calcula la probabilidad de que un elemento pertenezca a una categoría en función de las características que tiene. Para hacer esto, utiliza la probabilidad de que una característica aparezca en elementos de una categoría específica y la probabilidad de que una característica aparezca en elementos de todas las categorías.Aplicar el Teorema de Bayes: Utilizando las probabilidades calculadas, Naive Bayes aplica el Teorema de Bayes para obtener la probabilidad final de que el elemento pertenezca a cada categoría. Luego, clasifica el elemento en la categoría con la probabilidad más alta.Redes Neuronales Artificiales (ANN) Redes Neuronales Convolucionales (CNN) Convolución: La convolución es el proceso principal de una CNN. Consiste en aplicar un conjunto de filtros pequeños (también llamados kernels) a la imagen de entrada. Estos filtros son matrices que se deslizan por la imagen y realizan una operación matemática llamada convolución en cada posición. Esto ayuda a resaltar características específicas de la imagen, como bordes, esquinas o texturas.Función de activación: Después de la convolución, se aplica una función de activación, como la función ReLU (Rectified Linear Unit), que introduce no linealidad en la red. Esto es importante porque muchas relaciones en los datos de imágenes son no lineales, y la función ReLU permite capturar mejor estas características.Pooling (Agrupación): El proceso de agrupación ayuda a reducir la dimensionalidad de los datos y a hacer que la red sea más eficiente. Se toman regiones de la imagen y se reduce su tamaño, conservando solo la información más relevante. Esto ayuda a reducir la cantidad de parámetros en la red y evita el sobreajuste (overfitting).Capas completamente conectadas: Después de varias capas de convolución y agrupación, los datos se alimentan a través de capas completamente conectadas, también conocidas como capas densas. Estas capas aprenden relaciones más complejas entre las características extraídas y las etiquetas de clasificación.Clasificación: Finalmente, la última capa de la CNN realiza la clasificación de la imagen en diferentes categorías. Dependiendo del problema, puede haber diferentes funciones de activación en esta capa. Por ejemplo, para problemas de clasificación binaria, se puede usar una función sigmoide, y para problemas de clasificación multiclase, se puede usar una función Softmax.Redes Neuronales Recurrentes (RNN) Secuencia de entrada: Para cada paso de tiempo (por ejemplo, cada palabra en una oración o cada punto en una serie temporal), la RNN recibe una entrada.Cálculo del estado oculto: En cada paso de tiempo, la RNN calcula un nuevo estado oculto basado en la entrada actual y el estado oculto anterior. Este estado oculto actúa como una representación compacta de la información relevante en la secuencia hasta ese punto.Función de activación: Después de calcular el estado oculto, se aplica una función de activación (como la función ReLU) para introducir no linealidad y capturar relaciones complejas en los datos.Salida y retroalimentación: El estado oculto calculado en el paso actual se pasa al siguiente paso de tiempo para procesar la siguiente entrada en la secuencia. Este proceso de cálculo y retroalimentación se repite a lo largo de toda la secuencia.K-Means Inicialización: Primero, se seleccionan "K" puntos como centroides iniciales. Estos "K" centroides son los puntos iniciales que representan los centros de los "K" clusters que queremos formar. Pueden seleccionarse aleatoriamente o usando algún otro enfoque.Asignación de puntos a clusters: A continuación, cada punto de datos se asigna al cluster cuyo centroide está más cerca de él. Para medir la cercanía, se utiliza una métrica de distancia, generalmente la distancia euclidiana.Actualización de centroides: Después de asignar los puntos a los clusters, se calcula un nuevo centroide para cada cluster tomando la media de todos los puntos asignados a ese cluster. Estos nuevos centroides representan el centro actualizado de cada cluster.Repetición: Los pasos 2 y 3 se repiten iterativamente hasta que los centroides convergen y no hay cambios significativos en la asignación de puntos a los clusters.DBSCAN Clasificación por Agrupamiento (Clustering) Algoritmos Genéticos Población inicial: Comenzamos con una población de soluciones candidatas, cada una representada por un conjunto de parámetros (genes). Estas soluciones se generan aleatoriamente o a partir de conocimiento previo.Evaluación de la aptitud (fitness): Cada solución candidata en la población se evalúa utilizando una función de aptitud (fitness). Esta función mide qué tan buena es cada solución en términos de qué tan cerca está de ser una solución óptima para el problema.Selección: Se seleccionan las soluciones más aptas (con mayor valor de fitness) para formar una población de padres que participarán en el proceso de reproducción.Reproducción (cruce): Mediante el cruzamiento (reproducción), se combinan los genes de los padres seleccionados para crear nuevos individuos, llamados descendientes. Este proceso imita la reproducción biológica y permite explorar nuevas combinaciones de parámetros.Mutación: Ocasionalmente, se aplican mutaciones a los genes de los descendientes. La mutación introduce pequeñas modificaciones aleatorias en los genes para agregar diversidad y evitar quedarse atascado en soluciones subóptimas.Reemplazo: Los descendientes y, posiblemente, algunos de los padres seleccionados se combinan para formar la nueva población. Esta nueva población reemplaza la población anterior.Repetición: Los pasos 2 a 6 se repiten durante un número específico de generaciones o hasta que se cumpla algún criterio de convergencia.Aprendizaje por Refuerzo (Reinforcement Learning)
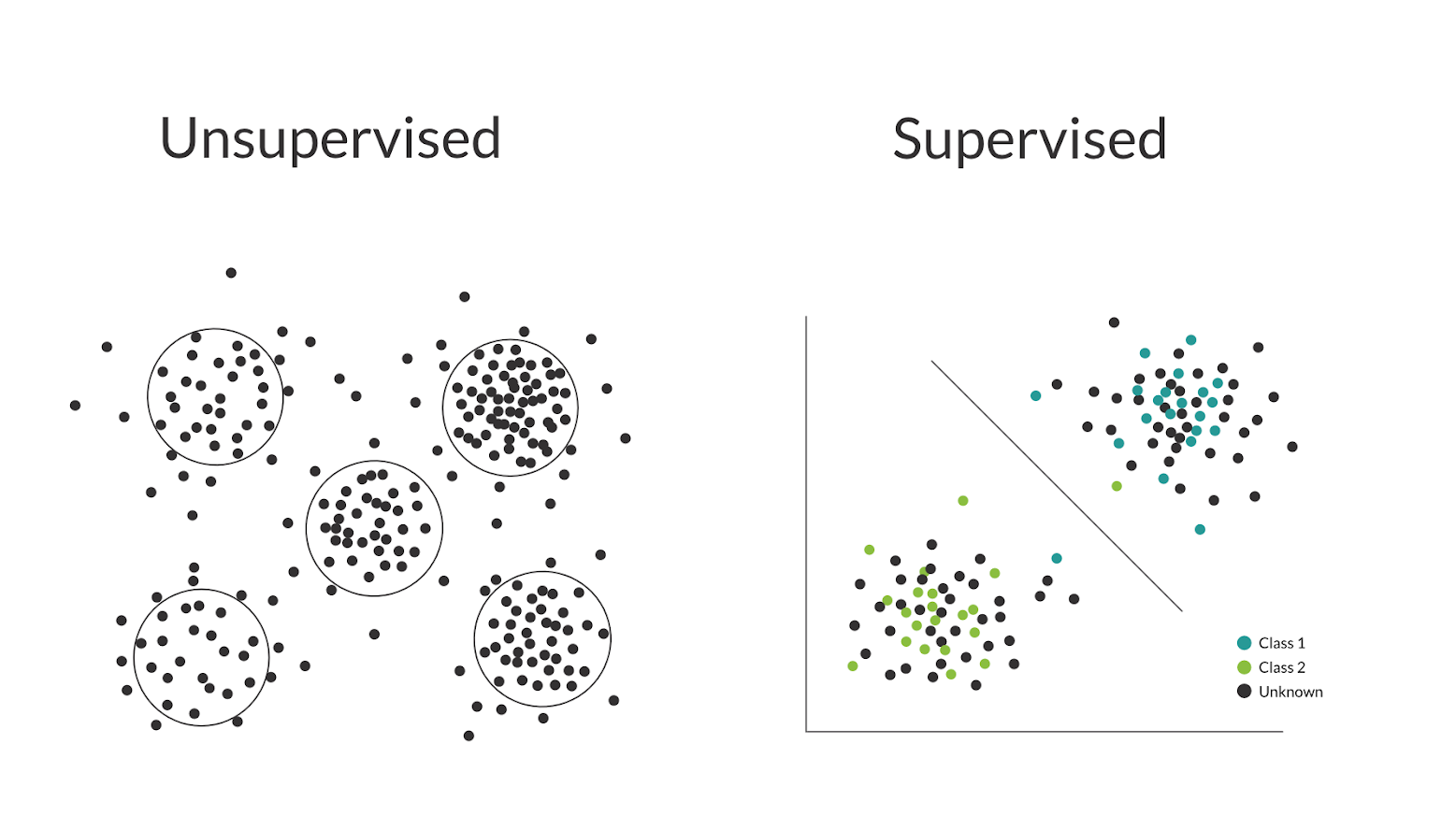
En los algoritmos supervisados, la máquina aprende de ejemplos con datos etiquetados, lo que significa que los datos de entrenamiento contienen respuestas conocidas. El objetivo es que el algoritmo pueda hacer predicciones precisas sobre nuevos datos basándose en lo que ha aprendido durante el entrenamiento.
🖍️

Los algoritmos no supervisados se utilizan para encontrar patrones y estructuras en datos no etiquetados. Estos algoritmos son útiles cuando no conocemos las respuestas con anticipación y queremos explorar la estructura oculta de los datos.
🖍️
La regresión lineal es un algoritmo de Machine Learning supervisado que se utiliza para predecir valores numéricos basados en una relación lineal entre variables. Por ejemplo, si queremos predecir el precio de una casa en función de su área, podemos usar la regresión lineal para encontrar una línea que mejor se ajuste a los datos.
🖍️
| Área (X) | Precio (Y) |
|---|---|
| 100 m2 | $200,000 |
| 150 m2 | $250,000 |
| 200 m2 | $300,000 |
Utilizando la regresión lineal, podemos encontrar la línea que mejor se ajusta a estos puntos, y luego utilizarla para predecir el precio de una casa con un área desconocida.
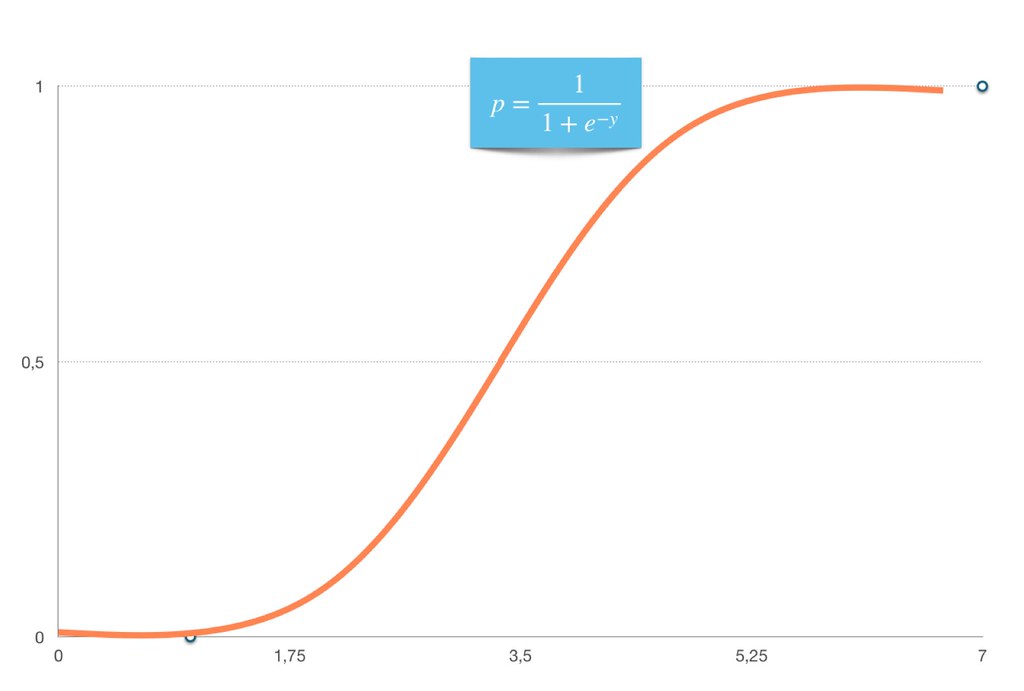
La regresión logística es un algoritmo de Machine Learning supervisado que se utiliza para la clasificación binaria. Se emplea para predecir la probabilidad de que un ejemplo pertenezca a una de las dos categorías posibles. Por ejemplo, podemos usar la regresión logística para predecir si un correo electrónico es spam o no spam.
🖍️
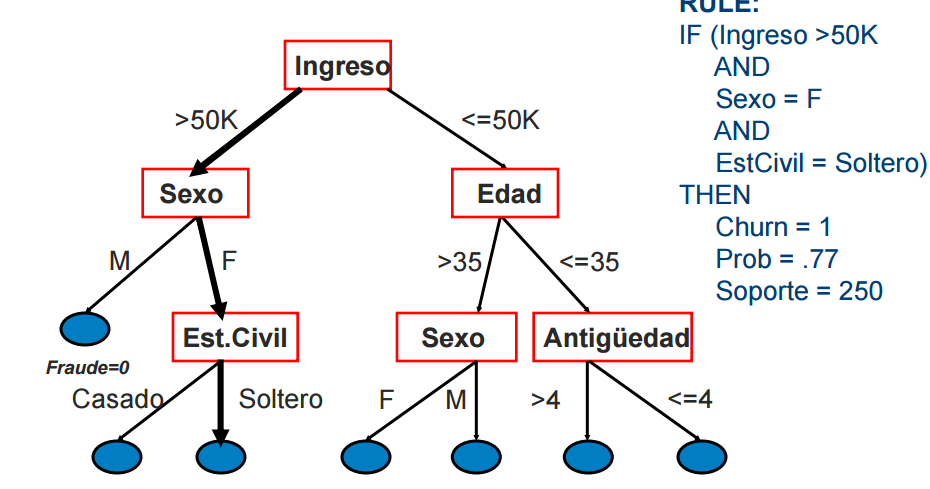
Los árboles de decisión son algoritmos de Machine Learning que se utilizan para tomar decisiones basadas en una serie de condiciones y características. El árbol se construye dividiendo los datos en diferentes nodos y ramas, y cada hoja representa una decisión.
🖍️
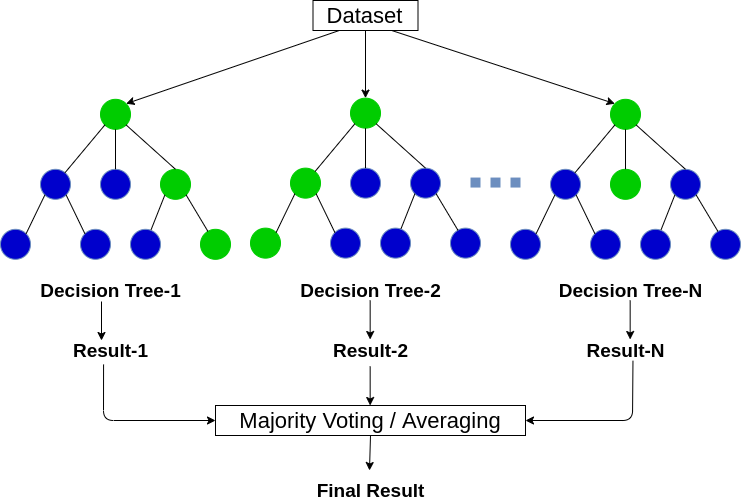
Random Forest es un algoritmo de Machine Learning que se basa en la combinación de múltiples árboles de decisión para realizar predicciones más precisas y evitar el sobreajuste.
🖍️
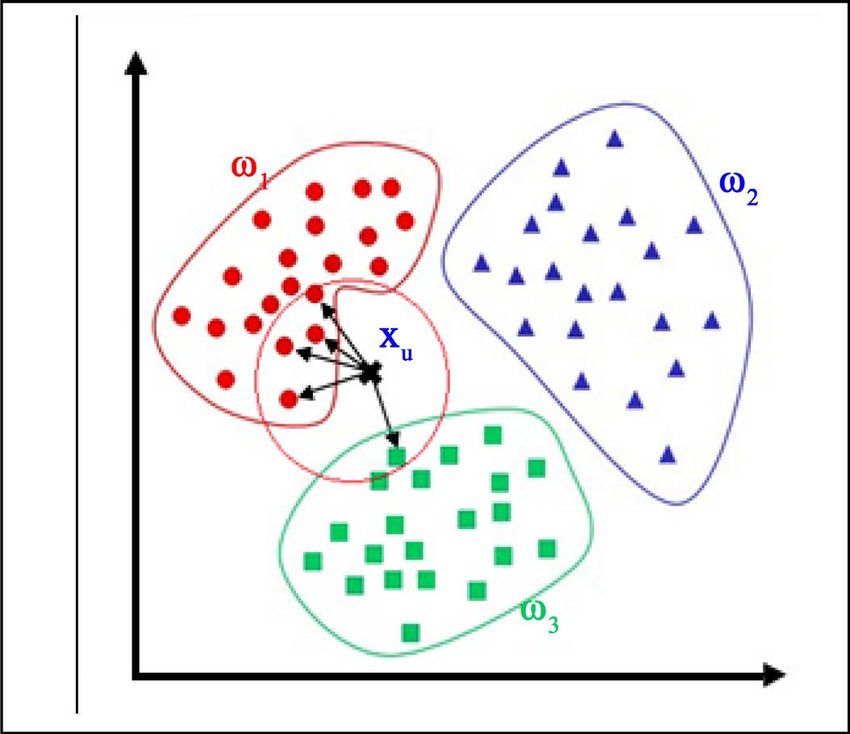
KNN es un algoritmo de Machine Learning no supervisado utilizado para la clasificación y la regresión. Funciona encontrando los K ejemplos más cercanos a un nuevo ejemplo y tomando una decisión basada en la mayoría de las etiquetas de los vecinos cercanos.
Imagina que tienes un conjunto de puntos en un gráfico, algunos de color rojo y otros de color azul, y tienes un nuevo punto (sin color) que necesitas clasificar en una de estas dos categorías.
El algoritmo K-Nearest Neighbors (K-NN) funciona de la siguiente manera: para clasificar el nuevo punto, mira los "K" puntos más cercanos a él de los puntos ya conocidos en el gráfico (es decir, los puntos rojos y azules). "K" es un número que debes elegir previamente.
Una vez que tienes los "K" puntos más cercanos, miras qué categoría es más común entre esos puntos cercanos. Luego, clasificas el nuevo punto como perteneciente a esa categoría mayoritaria.
En este caso, si K = 3 y de los 3 puntos más cercanos a nuestro nuevo punto, 2 son rojos y 1 es azul, entonces clasificaríamos el nuevo punto como rojo, ya que la categoría roja es la más común entre los puntos cercanos.
K-NN utiliza la idea de que puntos cercanos en el espacio tienen tendencia a ser similares entre sí. Por lo tanto, si la mayoría de los "K" puntos cercanos a uno desconocido son de una cierta categoría, es probable que ese nuevo punto también pertenezca a esa categoría.
🖍️
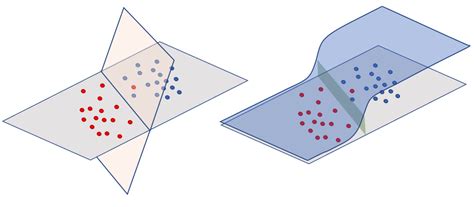
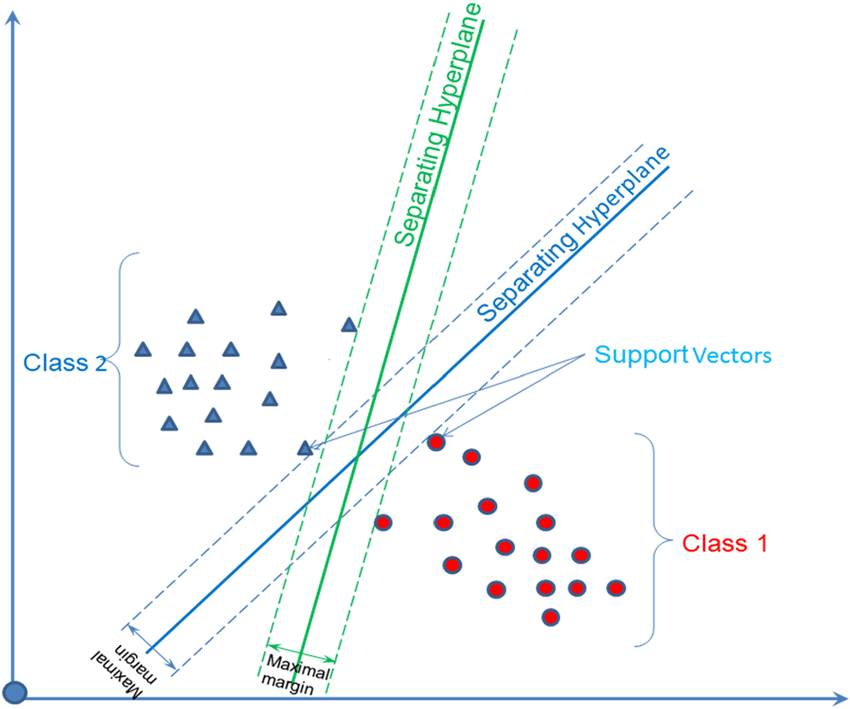
SVM es un algoritmo de Machine Learning supervisado utilizado para la clasificación y la regresión. Su objetivo es encontrar un hiperplano que mejor separe los datos en diferentes clases.
SVM nos ayuda a encontrar esa "mejor línea" o "hiperplano" en espacios de dimensiones más altas (no solo 2D) para separar los datos en categorías diferentes.
El término "Vector" en Support Vector Machine proviene de los puntos de datos que se representan como vectores en el espacio de características (dimensiones) que definimos. "Support" hace referencia a los puntos más cercanos a la línea de separación, que son fundamentales para encontrar la línea óptima.
Para encontrar esta línea óptima, SVM busca esos puntos de soporte y ajusta la posición de la línea para que estén lo más lejos posible de la línea, lo que se llama "margen". Esto significa que el SVM busca una línea que no solo separe los puntos, sino que también tenga el espacio más grande entre las clases.
Una vez que SVM encuentra esa línea óptima, puede clasificar nuevos puntos en función de qué lado de la línea caen. De esta manera, SVM se convierte en un clasificador muy poderoso para problemas de clasificación.
Además, SVM también tiene una característica interesante llamada "kernel trick", que permite transformar los datos a un espacio de dimensiones más altas para encontrar líneas de separación más complejas. Esto es útil cuando los datos no son linealmente separables y se necesitan transformaciones no lineales para encontrar una línea de separación adecuada.
🖍️
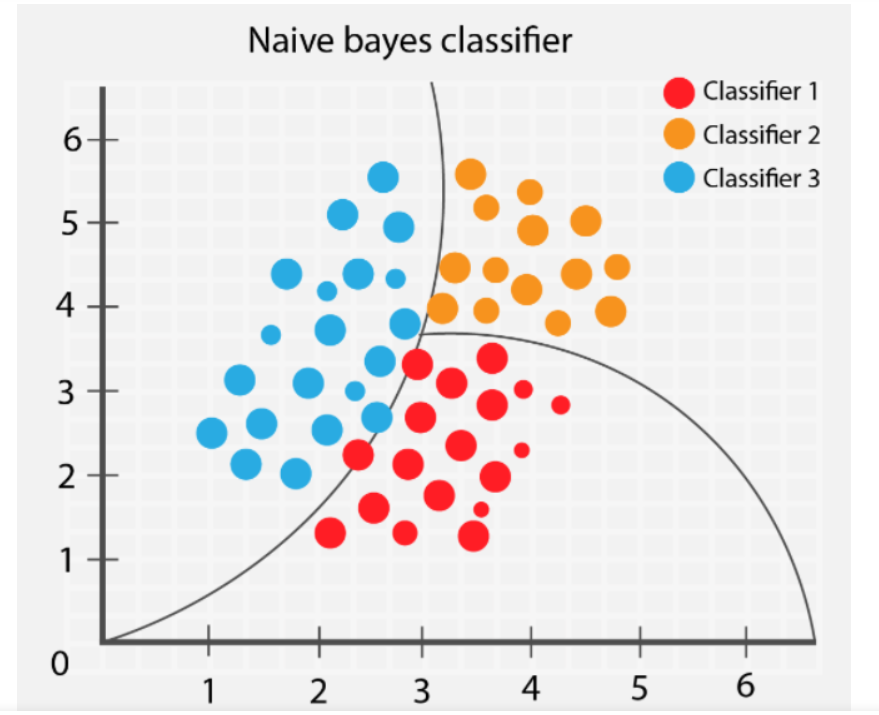
Naive Bayes es un algoritmo de Machine Learning supervisado utilizado para la clasificación, especialmente en problemas de clasificación de texto y análisis de sentimientos. Se basa en el teorema de Bayes y asume que todas las características son independientes entre sí, lo que puede no ser cierto en la práctica, pero sigue siendo efectivo en muchos casos.
Imagina que tienes un conjunto de datos con características sobre diferentes elementos, y cada elemento pertenece a una categoría específica. Por ejemplo, puedes tener correos electrónicos con diferentes palabras y etiquetarlos como "spam" o "no spam" según su contenido.
El algoritmo Naive Bayes se basa en el Teorema de Bayes, que es una fórmula matemática que nos permite calcular la probabilidad de que un elemento pertenezca a una categoría dada, dado que conocemos las características de ese elemento.
El término "Naive" (ingenuo en español) proviene de una suposición simple pero poderosa que hace el algoritmo: asume que todas las características son independientes entre sí. En otras palabras, considera que cada característica del elemento no está relacionada con las demás características, lo cual es una simplificación útil para muchos casos.
El proceso de clasificación con Naive Bayes funciona de la siguiente manera:
El algoritmo es rápido y eficiente, y puede ser muy útil para problemas de clasificación, especialmente cuando tienes muchas características para analizar. Aunque la suposición de independencia puede no ser siempre cierta en la realidad, Naive Bayes sigue siendo ampliamente utilizado debido a su simplicidad y buen rendimiento en muchas aplicaciones.
🖍️
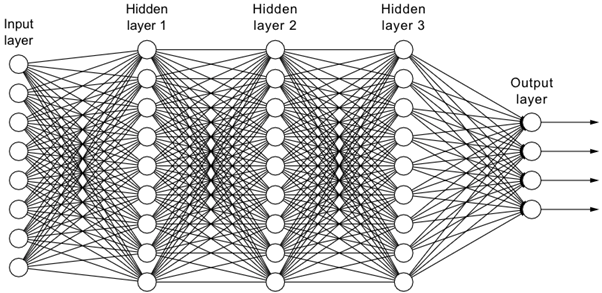
Las redes neuronales artificiales son modelos inspirados en el cerebro humano, con múltiples capas de neuronas interconectadas. Se utilizan en una amplia variedad de tareas, como clasificación, regresión, procesamiento de imágenes y procesamiento del lenguaje natural.
🖍️
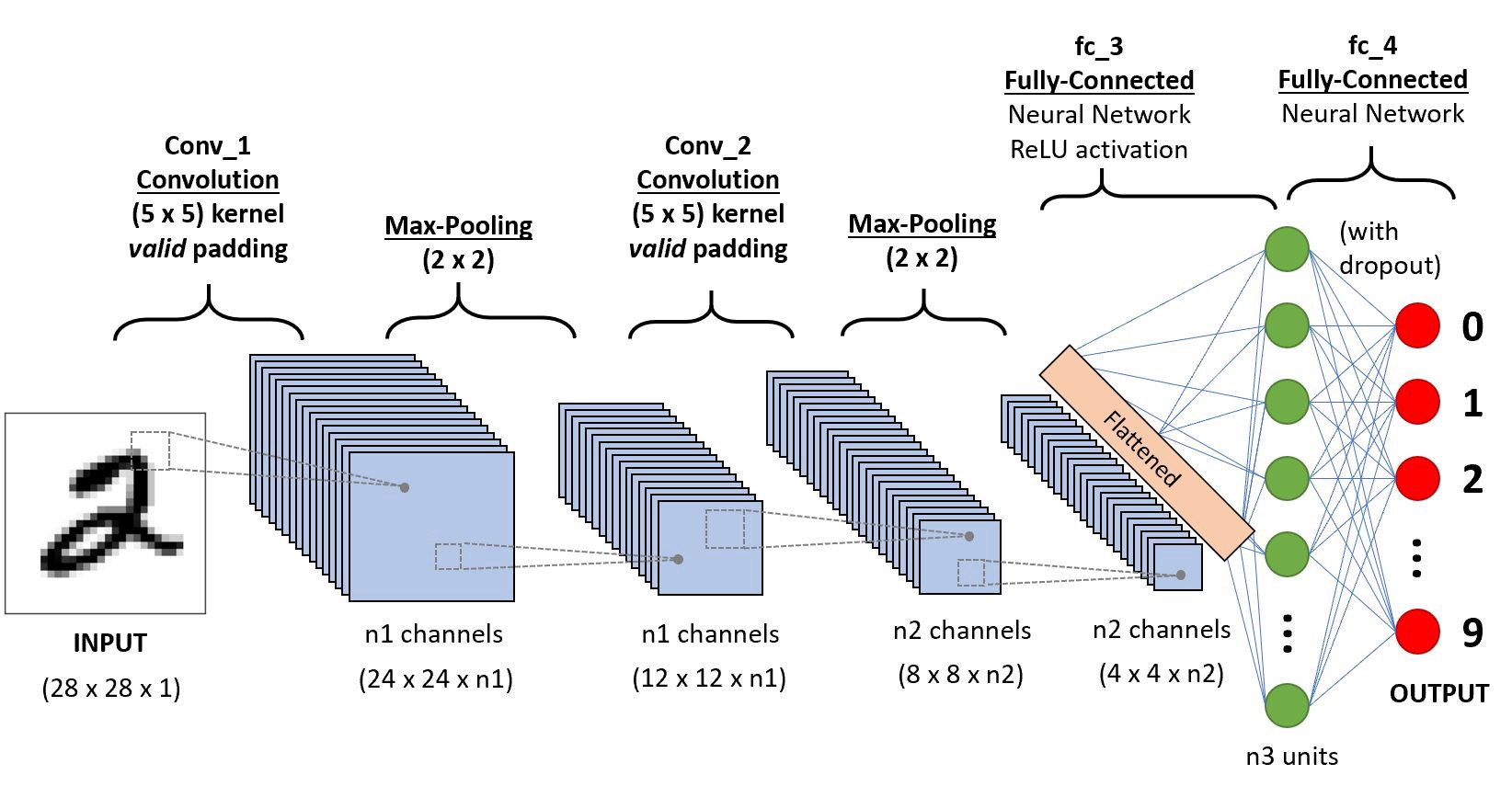
Las redes neuronales convolucionales son una variante de las redes neuronales artificiales, diseñadas específicamente para el procesamiento de imágenes y datos con estructura espacial. Utilizan operaciones de convolución para aprender patrones y características visuales en las imágenes.
Imagina que tienes una imagen y quieres saber qué objetos o características contiene. Para lograr esto, puedes usar una Red Neuronal Convolucional (CNN), que es un tipo especial de red neuronal diseñada específicamente para procesar datos de imágenes.
Una CNN funciona de la siguiente manera:
La magia de las CNN radica en su capacidad para aprender automáticamente características relevantes de las imágenes. A través de múltiples capas de convolución y agrupación, la red puede reconocer patrones cada vez más complejos y realizar tareas sofisticadas de clasificación, detección de objetos y más.
Una Convolutional Neural Network (CNN) es un tipo de red neuronal especializada en el procesamiento de imágenes. Utiliza capas de convolución, funciones de activación, agrupación y capas completamente conectadas para extraer y aprender automáticamente características relevantes de las imágenes y realizar tareas como clasificación y detección de objetos. Es una de las arquitecturas más poderosas para el procesamiento de datos de imágenes y ha impulsado avances significativos en la visión por computadora.
🖍️
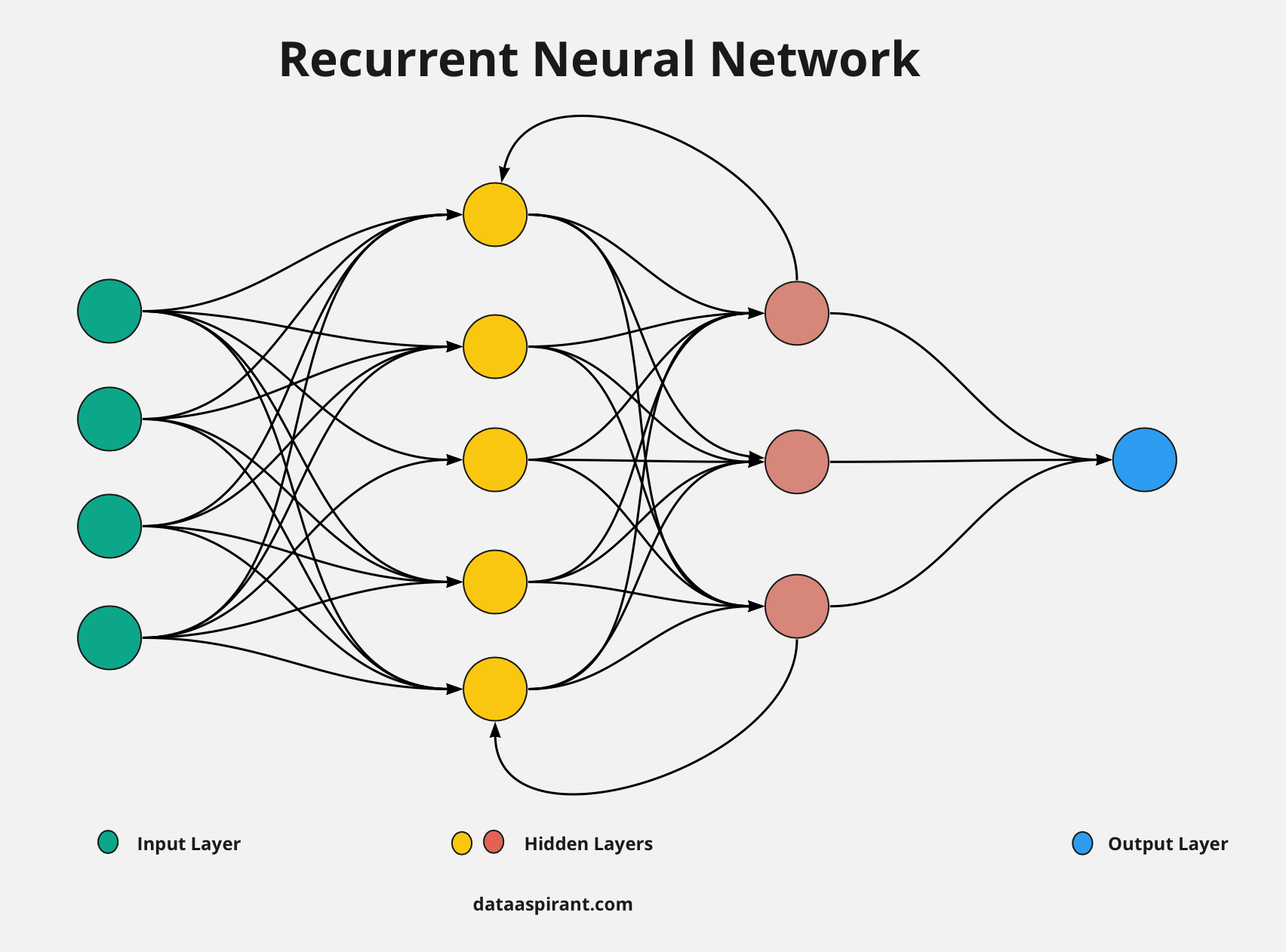
Las redes neuronales recurrentes son adecuadas para trabajar con secuencias de datos, ya que tienen conexiones que forman bucles para mantener una memoria temporal. Son muy útiles en tareas de procesamiento del lenguaje natural, traducción automática y generación de texto.
Imagina que tienes una secuencia de datos, como una serie temporal o una oración, donde el orden de los elementos es importante. Por ejemplo, puedes tener una serie de valores de temperatura registrados a lo largo del tiempo, o una oración en la que el significado cambia según el orden de las palabras.
Las Redes Neuronales Recurrentes (RNN) son un tipo de red neuronal especializada para manejar secuencias de datos. A diferencia de las redes neuronales convencionales que procesan datos de manera independiente, las RNN tienen conexiones que forman bucles y les permiten mantener una especie de "memoria" o estado oculto, que es actualizado en cada paso de tiempo y se utiliza para procesar la siguiente entrada en la secuencia.
El funcionamiento de una RNN es el siguiente:
Las RNN son especialmente útiles para tareas que involucran datos secuenciales, como el procesamiento del lenguaje natural (NLP), la generación de texto, el reconocimiento de voz, el análisis de series temporales y más.
A pesar de su utilidad, las RNN también tienen algunas limitaciones, como el problema de desvanecimiento y explosión del gradiente, que puede dificultar el entrenamiento de secuencias muy largas. Como resultado, han surgido variantes más avanzadas de RNN, como las Long Short-Term Memory (LSTM) y las Gated Recurrent Unit (GRU), que abordan estos problemas y son ampliamente utilizadas en aplicaciones prácticas.
Las Redes Neuronales Recurrentes (RNN) son un tipo de red neuronal diseñado para procesar secuencias de datos, manteniendo una "memoria" a través de conexiones recurrentes. Son útiles para tareas que implican datos secuenciales, como el procesamiento del lenguaje natural y el análisis de series temporales. Sin embargo, variantes como LSTM y GRU se han vuelto más populares debido a sus capacidades mejoradas para manejar secuencias largas y problemas de desvanecimiento y explosión del gradiente.
🖍️
K-Means es un algoritmo de agrupamiento no supervisado que divide los datos en K clústeres diferentes. Funciona asignando cada ejemplo al clúster más cercano en función de la distancia.
Imagina que tienes un conjunto de puntos de datos (por ejemplo, ubicaciones en un mapa) y quieres agruparlos en diferentes categorías o "clusters". Quieres que los puntos dentro de cada cluster sean similares entre sí y que los puntos en diferentes clusters sean lo más diferentes posible.
K-Means es un algoritmo de agrupamiento que resuelve este problema de manera simple y efectiva. Funciona de la siguiente manera:
Al finalizar, obtendremos "K" clusters, cada uno con su centroide y una colección de puntos de datos asignados a ellos.
K-Means es un algoritmo muy popular y ampliamente utilizado en el campo del aprendizaje no supervisado y la minería de datos. Se utiliza en aplicaciones como segmentación de clientes, compresión de imágenes, agrupamiento de datos y más.
Es importante destacar que la elección del número "K" de clusters es un parámetro crítico en K-Means. No hay una regla fija para determinar el valor óptimo de "K", pero se pueden utilizar técnicas como la validación cruzada o la evaluación visual de los resultados para encontrar un valor adecuado de "K".
K-Means es un algoritmo de agrupamiento que divide un conjunto de puntos de datos en "K" clusters, donde cada cluster tiene un centroide que representa el centro del cluster. El algoritmo asigna iterativamente los puntos a los clusters y actualiza los centroides hasta que convergen. Es una herramienta poderosa para agrupar datos y encontrar estructuras ocultas en conjuntos de datos no etiquetados.
🖍️
DBSCAN es otro algoritmo de agrupamiento no supervisado, pero a diferencia de K-Means, no requiere especificar el número de clústeres de antemano. En lugar de eso, identifica automáticamente los clústeres basados en la densidad de los datos.
🖍️

La clasificación por agrupamiento es un término general para los algoritmos que dividen los datos en grupos o clústeres similares. Incluye algoritmos como K-Means y DBSCAN.
🖍️
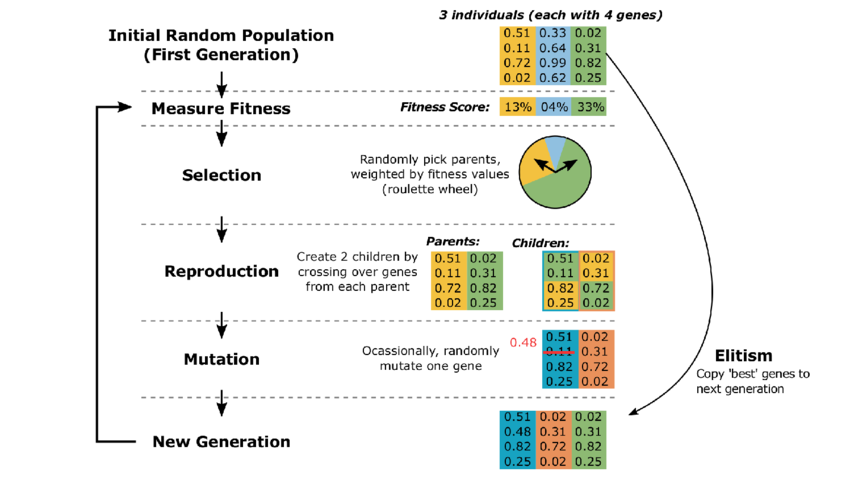
Los algoritmos genéticos son una técnica de optimización inspirada en la teoría de la evolución. Utilizan conceptos como selección natural, mutación y cruzamiento para encontrar soluciones óptimas a problemas complejos.
El funcionamiento de los Algoritmos Genéticos es el siguiente:
Con cada generación, los individuos de la población tienden a ser más aptos, ya que las mejores soluciones tienen más probabilidades de ser seleccionadas y reproducidas. Con el tiempo, los Algoritmos Genéticos convergen hacia una solución que se acerca a la óptima para el problema dado.
Los Algoritmos Genéticos son muy versátiles y se utilizan para resolver una amplia gama de problemas de optimización, como encontrar la mejor ruta en un problema de viajante de comercio, diseñar estructuras, optimizar parámetros de modelos matemáticos y mucho más.
Los Algoritmos Genéticos son una técnica de búsqueda y optimización basada en la teoría de la evolución. Generan soluciones candidatas a partir de una población inicial, seleccionan y reproducen las mejores soluciones, y aplican mutaciones para explorar y mejorar progresivamente las soluciones. Son útiles para encontrar soluciones cercanas a la óptima en problemas complejos y difíciles de resolver con métodos tradicionales.
🖍️
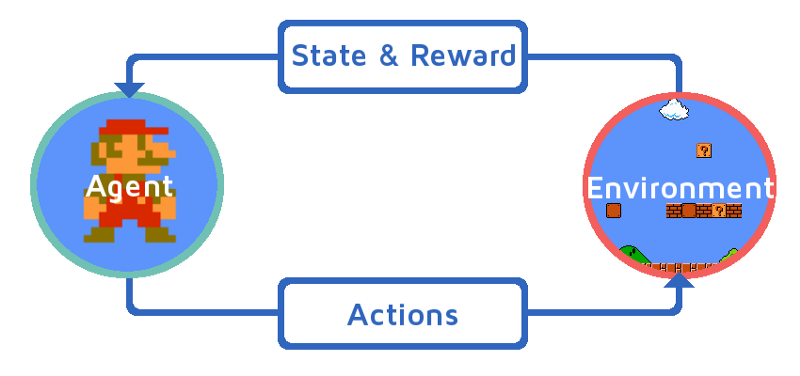
El aprendizaje por refuerzo es un enfoque en el que un agente aprende a través de la interacción con un entorno. El agente toma acciones y recibe recompensas o penalizaciones según sus acciones, con el objetivo de maximizar las recompensas a lo largo del tiempo.
🖍️
Estos ejemplos ilustran cómo se aplican los diferentes algoritmos de Machine Learning y Deep Learning en diversas situaciones para resolver problemas y tomar decisiones. Cada algoritmo tiene sus ventajas y desafíos, y la elección del algoritmo adecuado dependerá del tipo de problema y los datos disponibles.