LLM (Large Language Model)
Los Modelos de Lenguaje de Gran Escala (LLM, por sus siglas en inglés) son redes neuronales entrenadas en grandes cantidades de datos textuales para comprender y generar lenguaje humano. Estos modelos utilizan arquitecturas como Transformers, popularizadas por el modelo GPT (Generative Pre-trained Transformer). Su funcionamiento se basa en el uso de millones o incluso miles de millones de parámetros que ajustan las probabilidades de las palabras en una secuencia, permitiendo respuestas coherentes y contextualmente relevantes.
Modelos de Código Abierto
A diferencia de los modelos propietarios como ChatGPT de OpenAI o Gemini de Google, existen modelos de código abierto que ofrecen flexibilidad y control para empresas y desarrolladores. Algunos de los más populares incluyen:
LLaMA (Meta): Un modelo eficiente que puede ejecutarse en hardware de consumo.DeepSeek: Un modelo de código abierto optimizado para generación de lenguaje y tareas avanzadas de IA, con enfoque en eficiencia y escalabilidad.Mistral: Un modelo ligero y eficiente con alto rendimiento en tareas de lenguaje.Falcon (Technology Innovation Institute): Optimizado para implementaciones locales.Bloom (BigScience): Un modelo multilingüe entrenado en diversas fuentes de datos.GPT-NeoX y GPT-J (EleutherAI): Alternativas abiertas a GPT-3 con buen rendimiento y optimización para tareas de lenguaje y programación.
Estos modelos pueden ejecutarse localmente, brindando independencia de servicios en la nube y mayor privacidad en el procesamiento de datos sensibles.

Implementación Local de LLMs
Ejecutar un LLM de manera local requiere hardware potente, idealmente con GPUs o TPUs optimizadas para cálculo de redes neuronales. Herramientas como Ollama, LMStudio o llama.cpp permiten ejecutar modelos en equipos personales, utilizando técnicas de cuantización para reducir la carga computacional.
Para la inferencia local, se pueden utilizar frameworks como:
Transformers (Hugging Face): Facilita la carga y uso de modelos preentrenados.TensorRT y ONNX Runtime: Optimizan el rendimiento en GPUs de NVIDIA.GGML/GGUF: Permiten ejecutar modelos optimizados en CPUs.
Los usuarios pueden emplear LLMs para acceder a bases de datos personales y generar respuestas basadas en información propia. Para lograr esto, se emplean técnicas como Retrieval-Augmented Generation (RAG), que combina generación de texto con recuperación de documentos relevantes desde una fuente de datos.
Métodos de Conexión y APIs
Existen varias formas de conectar un LLM con bases de datos y sistemas empresariales:
- 𖦹
APIs REST y WebSockets: Se exponen endpoints para consultas en lenguaje natural. Ejemplo: Integración con Elasticsearch o bases de datos SQL/NoSQL. - 𖦹
Conectores Directos a Bases de Datos: Se usa un middleware para ejecutar consultas SQL. Integración con herramientas como LangChain o LlamaIndex. - 𖦹
Vector Databases (Bases de Datos Vectoriales): Permiten almacenar embeddings semánticos generados por los LLMs. Ejemplo: Pinecone, Weaviate, ChromaDB, FAISS. - 𖦹
Plugins y Extensiones: Empresas crean plugins para interactuar con CRMs, ERPs y otros sistemas corporativos.
Hugging Face
Hugging Face es una plataforma que centraliza modelos de IA, incluyendo LLMs, y proporciona herramientas para su implementación. En su repositorio, se encuentran modelos de código abierto para NLP, visión por computadora y más.
Tipos de Modelos en Hugging Face:
Modelos de Lenguaje: GPT, LLaMA, Mistral, DeepSeek, entre otros.Modelos de Código: StarCoder, CodeLlama, SantaCoder.Modelos Multimodales: CLIP, Flamingo, Whisper.
Descarga e Implementación
- Instalar los paquetes:
- Crear un token de autenticación en Hugging Face: Para hacerlo, accede a tu cuenta de Hugging Face, dirígete a la sección de configuración, luego a la pestaña "Access Tokens" y selecciona "New token". Elige un nombre y nivel de acceso adecuado, luego genera y copia el token para usarlo en futuras autenticaciones.
- Iniciar sesión con Hugging Face CLI:
- Para descargar modelos desde Hugging Face, se usa la librería transformers de Python:
Esto permite cargar modelos listos para inferencia o fine-tuning en aplicaciones personalizadas.
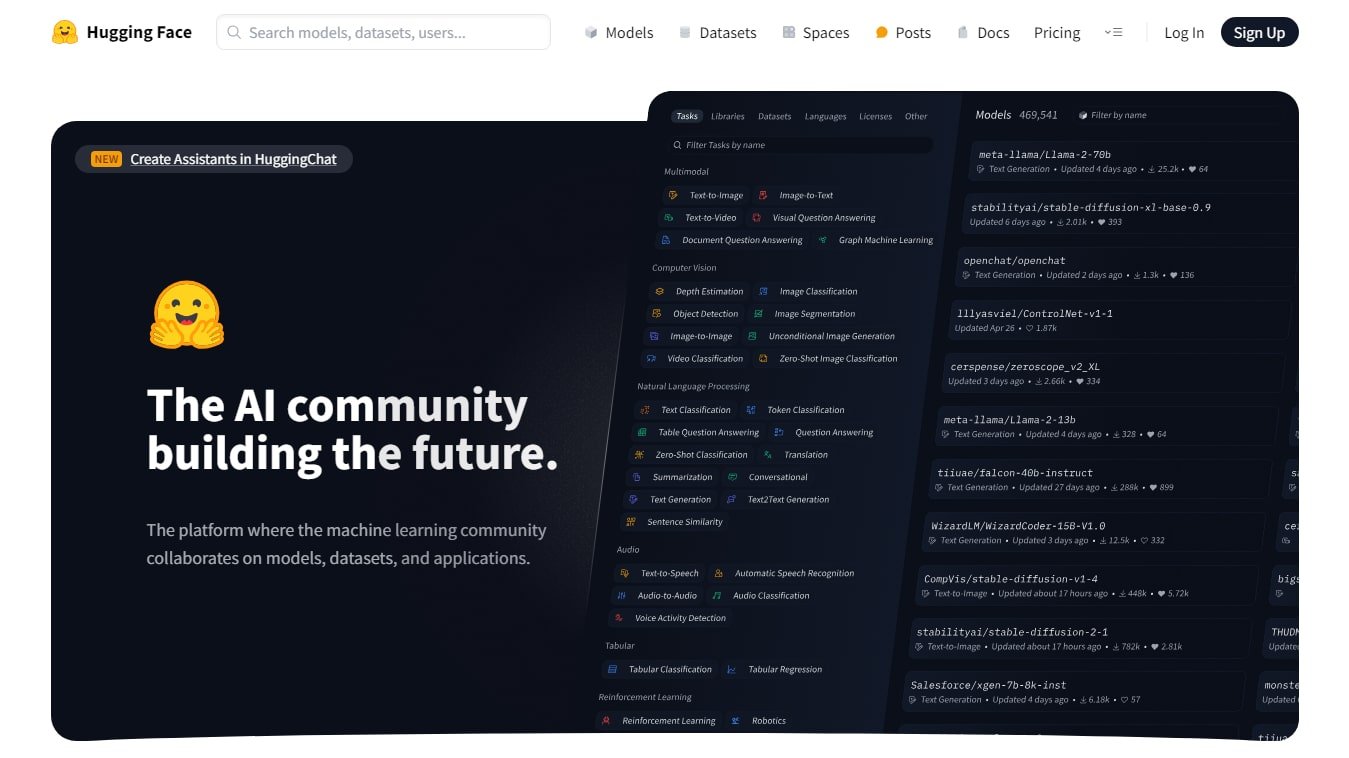
Puedes buscar modelos de forma manual en Hugging Face a través de su sitio web, luego hacer clic en la pestaña Models y si necesitas filtrarlo por tipo de modelo o framework, ir a la sección Libraries.
En la sección Tasks de Hugging Face, puedes buscar modelos según la tarea específica que necesitas resolver. Al hacer clic en Tasks, verás categorías como:
Text Generation: Para generación de texto (ej. GPT, LLaMA).Text Classification: Para clasificar texto (ej. sentimiento, spam).Summarization: Para resumir textos (ej. BART, T5).Translation: Para traducción automática.Image Generation: Para generar imágenes (ej. Stable Diffusion).Object Detection: Para detección de objetos en imágenes.Speech Recognition: Para convertir audio en texto (ej. Whisper).
Al seleccionar una tarea, Hugging Face te mostrará los modelos más populares y recomendados para esa función. Así puedes filtrar y elegir el mejor modelo sin necesidad de conocer su nombre exacto.
Tareas aceleradas por GPU
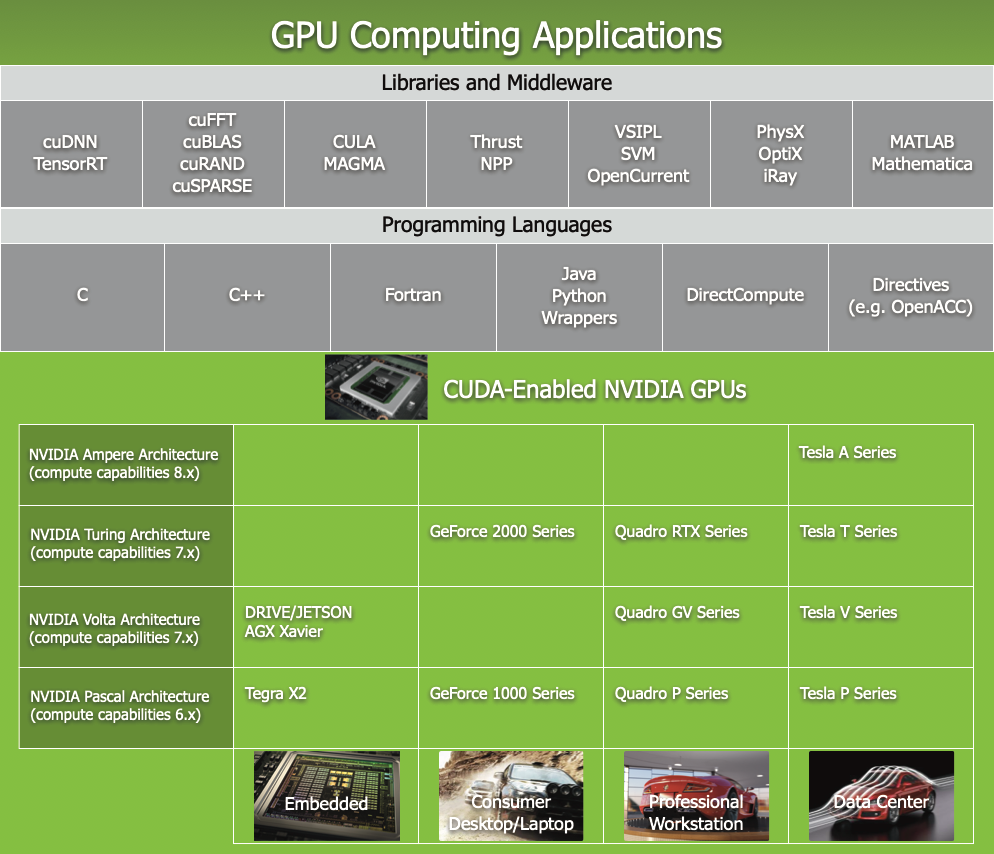
CUDA Toolkit es un conjunto de herramientas desarrollado por NVIDIA que permite a los desarrolladores aprovechar la potencia de las GPUs para ejecutar cálculos paralelos de alto rendimiento. Incluye compiladores, bibliotecas, y herramientas de depuración para desarrollar aplicaciones en CUDA (Compute Unified Device Architecture), un modelo de programación diseñado específicamente para procesadores gráficos de NVIDIA.
Funciones:
- Acelerar cómputo paralelo en tareas como aprendizaje profundo, simulaciones científicas y procesamiento de imágenes.
- Optimizar modelos de IA y Machine Learning, facilitando la ejecución de frameworks como PyTorch y TensorFlow con soporte para GPU.
- Mejorar el rendimiento de cálculos matemáticos intensivos mediante bibliotecas como cuBLAS (álgebra lineal), cuDNN (redes neuronales) y Thrust (programación paralela en C++).
- Facilitar la programación en GPU a través de un entorno que incluye NVCC (compilador CUDA), CUDA Runtime API y herramientas de profiling como Nsight.
Puedes obtener CUDA Toolkit directamente desde la página oficial de NVIDIA.
Pasos para usar CUDA
- Reiniciar la terminal
- Verificar la instalación de CUDA
- Instalar PyTorch con la versión de CUDA detectada
- Verificar que PyTorch reconoce CUDA
- Ejemplo de uso en Python con CUDA
Si usas un entorno virtual como Conda o venv, actívalo.
(Si usas otra versión, cambia cu128 por la que corresponda, como cu121 para CUDA 12.1).
Ejecuta el siguiente script en Python:
Aquí se hace uso del script previo para usar CUDA y cambiar entre CPU y GPU dinámicamente:
La librería transformers de Hugging Face permite cambiar entre CPU y GPU mediante el argumento device al crear el pipeline.
Si tienes una GPU compatible con CUDA, el dispositivo será "cuda", y debes pasar device=0 para indicar que se use la primera GPU disponible.
Si no tienes una GPU compatible o deseas ejecutar el modelo en la CPU, el dispositivo será "cpu", y debes pasar device=-1.
Langchain
LangChain es un marco de trabajo diseñado para desarrollar aplicaciones que utilizan modelos de lenguaje de manera más estructurada y eficiente. Facilita la integración de modelos de IA con bases de datos, APIs externas y herramientas avanzadas como recuperación de información (RAG), memoria de contexto y toma de decisiones.
Este framework es especialmente útil para construir chatbots, agentes autónomos, generación de texto basada en datos, automatización de tareas con IA y muchas otras aplicaciones. Se puede usar con múltiples modelos de lenguaje como GPT-4, Mistral, LLaMA, Claude, entre otros.
Principales funcionalidades:
Prompts Personalizados: LangChain permite definir plantillas de prompts para estructurar mejor las consultas que se envían a los modelos, optimizando su rendimiento y obteniendo respuestas más precisas.Memoria (Contexto de Conversación): Permite a los modelos recordar interacciones previas dentro de una conversación, lo que es clave para chatbots y asistentes de IA.- ⌭
Short-term memory: Recuerda solo las últimas interacciones. - ⌭
Long-term memory: Almacena conversaciones más largas, generalmente en bases de datos o archivos. Cadenas de Procesamiento (Chains): Permite combinar múltiples pasos en una única ejecución. Por ejemplo, recibir una consulta, reformatearla, obtener una respuesta de un modelo y devolver un resultado estructurado.Conectores a Bases de Datos (Vector Stores): LangChain permite usar bases de datos vectoriales como ChromaDB, FAISS, Weaviate, Pinecone, etc., para almacenar información en forma de embeddings y mejorar la búsqueda de datos en grandes volúmenes de texto.Agentes y Herramientas: LangChain permite crear agentes que pueden interactuar con múltiples herramientas y realizar tareas como consultas en bases de datos, llamadas a APIs, búsquedas web, cálculos matemáticos, etc.
Ejemplo:
Ejemplo de memoria en un chatbot:
Ejemplo:
Ejemplo con ChromaDB:
Ejemplo de agente:
Ejemplo 1
⌨️ El siguiente script en Python utiliza procesamiento de lenguaje natural (NLP) para resumir textos de manera inteligente y adaptada a la comprensión de diferentes grupos de edad.
Ejemplo 2
⌨️ Este script es una herramienta avanzada que combina la generación de resúmenes con la capacidad de responder preguntas sobre el contenido resumido. Utiliza modelos preentrenados de Hugging Face y la integración con LangChain para ofrecer una experiencia completa de procesamiento de lenguaje natural (NLP).
Ejemplo 3
Para el siguiente ejemplo, debes instalar Ollama en tu sistema y luego utilizarlo desde la terminal o en Python. Aquí tienes los pasos detallados:
Ollama está disponible para Windows, macOS y Linux. Descárgalo desde la web oficial.
Puedes ver la lista completa en Ollama Models.
Ejemplo de uso en Python:
⌨️ El siguiente script implementa un chatbot interactivo utilizando un modelo de lenguaje local a través de Ollama y el framework LangChain. El chatbot es capaz de mantener una conversación con el usuario, recordando el historial de la conversación para proporcionar respuestas contextualmente relevantes.
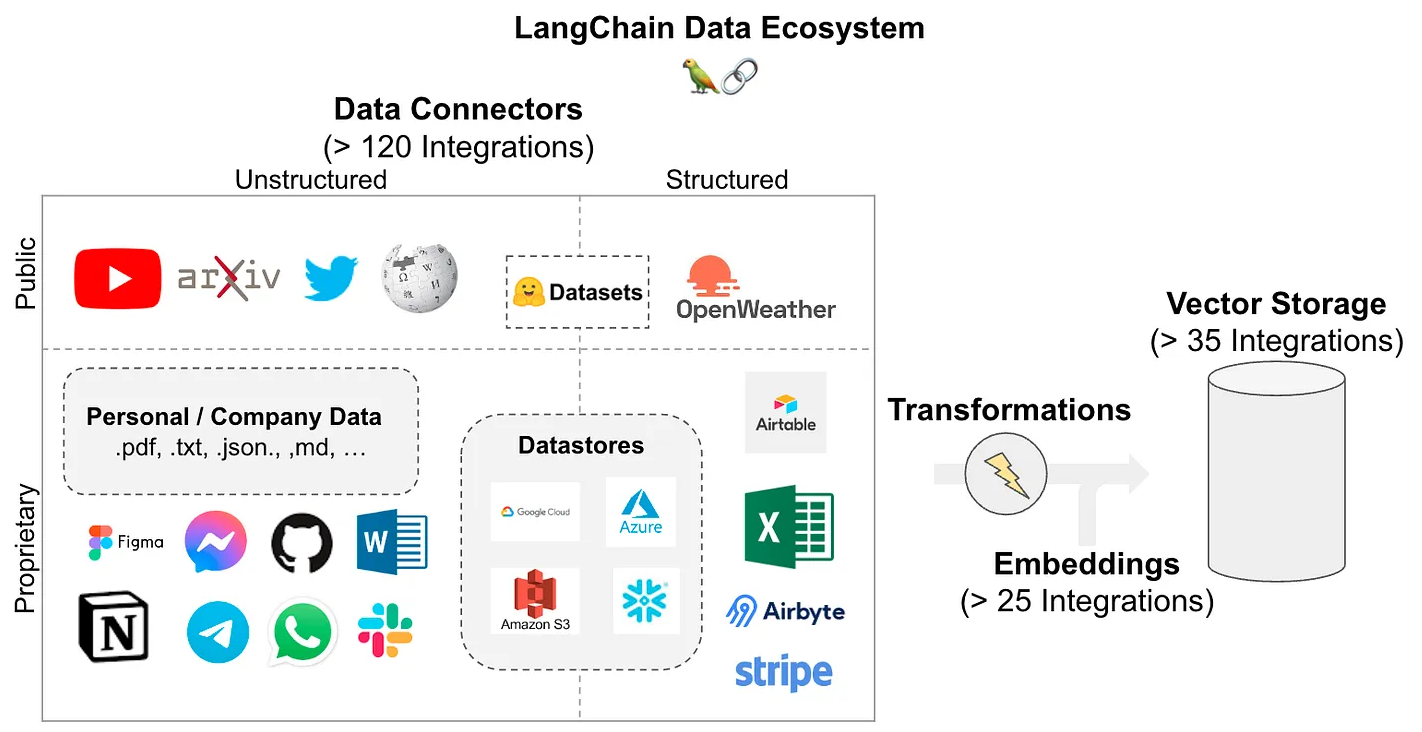
Langflow
Langflow es una herramienta de desarrollo de interfaces gráficas para aplicaciones de inteligencia artificial (IA), diseñada para facilitar la creación, gestión y visualización de flujos de trabajo que involucran modelos de lenguaje. Se basa en LangChain, una librería popular en Python para construir aplicaciones con modelos de lenguaje como GPT, Mistral y otros.
Langflow proporciona una interfaz visual intuitiva que permite a los desarrolladores y científicos de datos construir cadenas de procesamiento de texto sin necesidad de programar directamente en Python, aunque también permite integraciones avanzadas para usuarios más experimentados.
Es una herramienta diseñada principalmente para facilitar el diseño y la implementación de flujos de trabajo de inteligencia artificial (IA) de manera visual, eliminando la necesidad de escribir código manualmente. Permite a los usuarios integrar y probar modelos de lenguaje con gran facilidad, lo que acelera el proceso de desarrollo y experimentación. Además, Langflow es ideal para crear y compartir prototipos rápidamente, fomentando la colaboración entre desarrolladores y equipos de IA. También ofrece la capacidad de optimizar flujos de procesamiento de texto, permitiendo ajustes rápidos y pruebas iterativas para mejorar la eficiencia y precisión de los sistemas de IA.
Langflow es altamente flexible y se puede integrar con diversas herramientas y plataformas:
- ◘
Modelos de Lenguaje: GPT-4, Mistral, LLaMA, PaLM, entre otros. - ◘
Bases de Datos: PostgreSQL, MongoDB, Redis, entre otros. - ◘
APIs y Servicios Cloud: OpenAI API, Hugging Face, Google Cloud AI, AWS SageMaker. - ◘
Frameworks de Machine Learning: TensorFlow, PyTorch, Scikit-learn. - ◘
Aplicaciones Web y Backend: FastAPI, Flask, Django, Streamlit.
Ejemplo de uso
A continuación, te explico cómo puedes usar Langflow paso a paso:
Esto iniciará un servidor local.
Langflow ofrece una interfaz visual donde puedes arrastrar y soltar componentes para construir flujos de trabajo de IA.
Componentes principales de Langflow:
Editor Visual: Interfaz gráfica de arrastrar y soltar para construir flujos de trabajo de IA.Nodos y Conectores: Representan componentes como modelos de lenguaje, preprocesamiento de datos y conectores API.Biblioteca de Integraciones: Soporte para servicios de terceros y modelos personalizados.Gestor de Variables y Parámetros: Permite modificar configuraciones sin cambiar la estructura del flujo.Compatibilidad con LangChain: Facilita el uso de cadenas de procesamiento con capacidades avanzadas.
Langflow permite exportar e importar modelos en formato JSON, lo que facilita su implementación y reutilización en diferentes entornos. Para importar un modelo previamente guardado:
- Accede a la interfaz de Langflow.
- Para importar un modelo en Langflow, primero crea un nuevo flujo haciendo clic en "New Flow" en la interfaz principal. Una vez que tengas tu flujo en blanco, dirígete a la parte superior de la pantalla donde dice "Untitled document" (o el nombre actual del flujo), haz clic para desplegar el menú y selecciona la opción "Import".
- Carga el archivo JSON del modelo previamente guardado.
- Ajusta los parámetros si es necesario y ejecuta el flujo.
Tambien es posible integrar Langflow en un entorno de desarrollo usando LangChain, cargando modelos y flujos en Python para personalización avanzada.
Haz click aquí para ver un ejemplo de uso en LangChain.
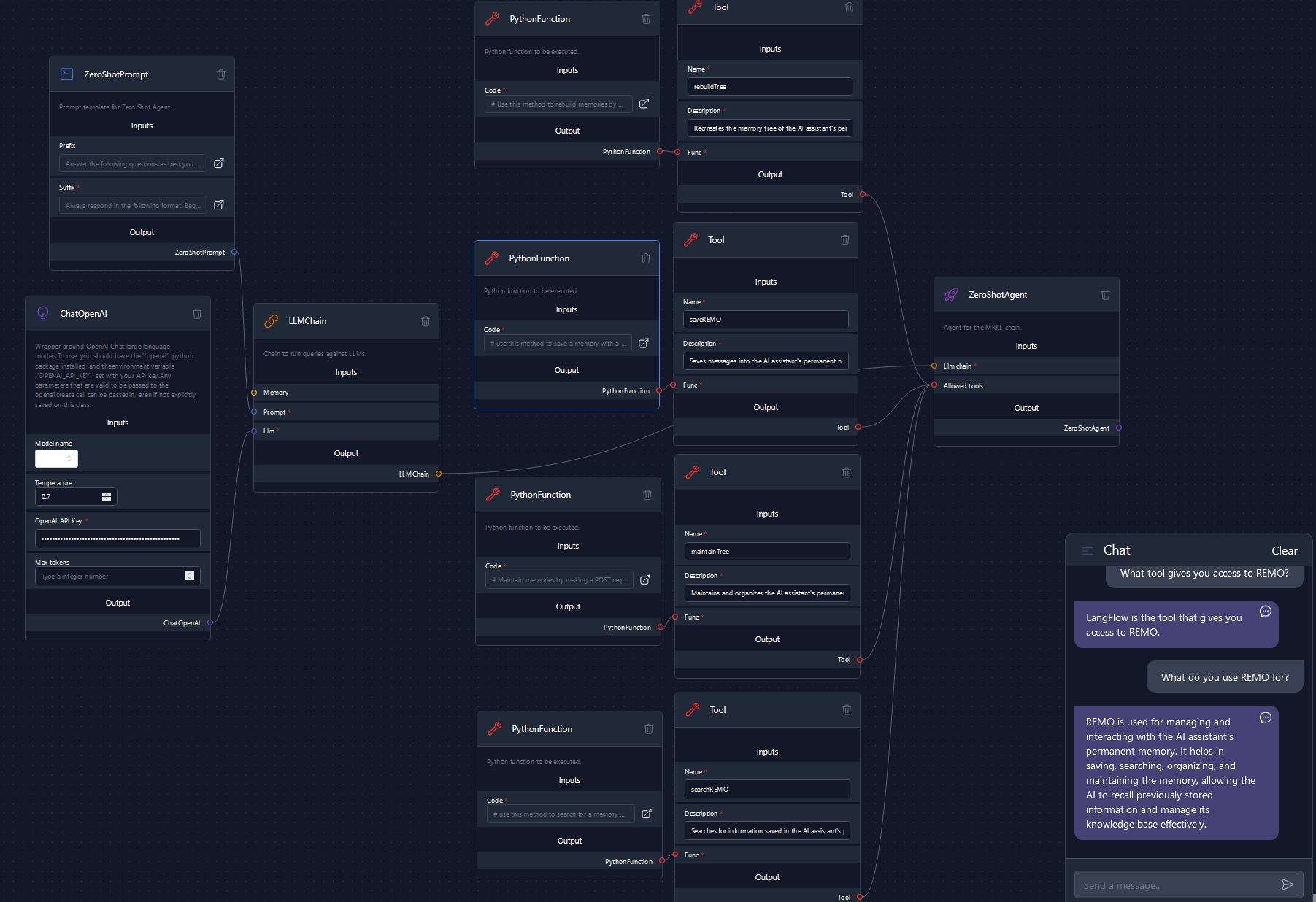
Voiceflow
Voiceflow es una plataforma de desarrollo de asistentes conversacionales que permite diseñar, probar e implementar chatbots y asistentes de voz sin necesidad de programación avanzada. Su enfoque principal es la creación de experiencias interactivas con inteligencia artificial (IA), optimizadas para interfaces de voz y texto.
Voiceflow se ha convertido en una herramienta popular para diseñadores, desarrolladores y empresas que desean construir asistentes conversacionales con facilidad y rapidez.
Se usa para crear chatbots y asistentes virtuales que pueden integrarse en diversas plataformas y dispositivos. Sus principales aplicaciones incluyen:
Automatización de atención al cliente: Facilita la creación de asistentes capaces de responder preguntas frecuentes y resolver problemas sin intervención humana.Asistentes de voz y chatbots para empresas: Permite diseñar experiencias conversacionales para mejorar la interacción con los clientes.Educación y entrenamiento: Se utiliza para crear asistentes de aprendizaje interactivo y herramientas de formación.Integración con dispositivos inteligentes: Compatible con asistentes de voz como Amazon Alexa y Google Assistant.Prototipado rápido de experiencias de IA conversacional: Ideal para diseñadores de UX/UI que desean probar interacciones conversacionales sin programar desde cero.
Además está compuesto por varios elementos clave que permiten su funcionamiento. Su editor visual de flujos permite diseñar conversaciones de manera intuitiva mediante una interfaz de arrastrar y soltar. Los nodos de conversación representan interacciones esenciales como preguntas, respuestas, lógica condicional y acciones, lo que facilita la estructuración del flujo del chatbot. Además, la plataforma ofrece integraciones con APIs, permitiendo la conexión con bases de datos y servicios externos para ampliar la funcionalidad del asistente. La gestión de variables y datos posibilita el almacenamiento de información relevante para personalizar las respuestas, mejorando la experiencia del usuario. Voiceflow también cuenta con un simulador y herramientas de prueba en tiempo real para evaluar y ajustar las interacciones antes de su despliegue. Finalmente, su capacidad de despliegue multicanal permite implementar los asistentes en diversas plataformas sin necesidad de código adicional, garantizando una amplia compatibilidad y accesibilidad.
Voiceflow ofrece compatibilidad con diversas plataformas y servicios, lo que amplía su versatilidad:
- ◘
Plataformas de mensajería: WhatsApp, Facebook Messenger, Telegram, Slack. - ◘
Asistentes de voz: Amazon Alexa, Google Assistant. - ◘
APIs y Webhooks: Integración con servicios personalizados mediante API REST y webhooks. - ◘
CRM y herramientas empresariales: Salesforce, Zendesk, HubSpot. - ◘
Sistemas de IA y NLP: OpenAI, Google Dialogflow, IBM Watson.
Voiceflow permite exportar proyectos y flujos conversacionales en varios formatos para su reutilización e integración en otros sistemas, además de ofrecer la posibilidad de conectar con APIs externas y bases de datos para mejorar la personalización de las respuestas de los chatbots.
Para más información, puedes visitar su página oficial: Voiceflow.
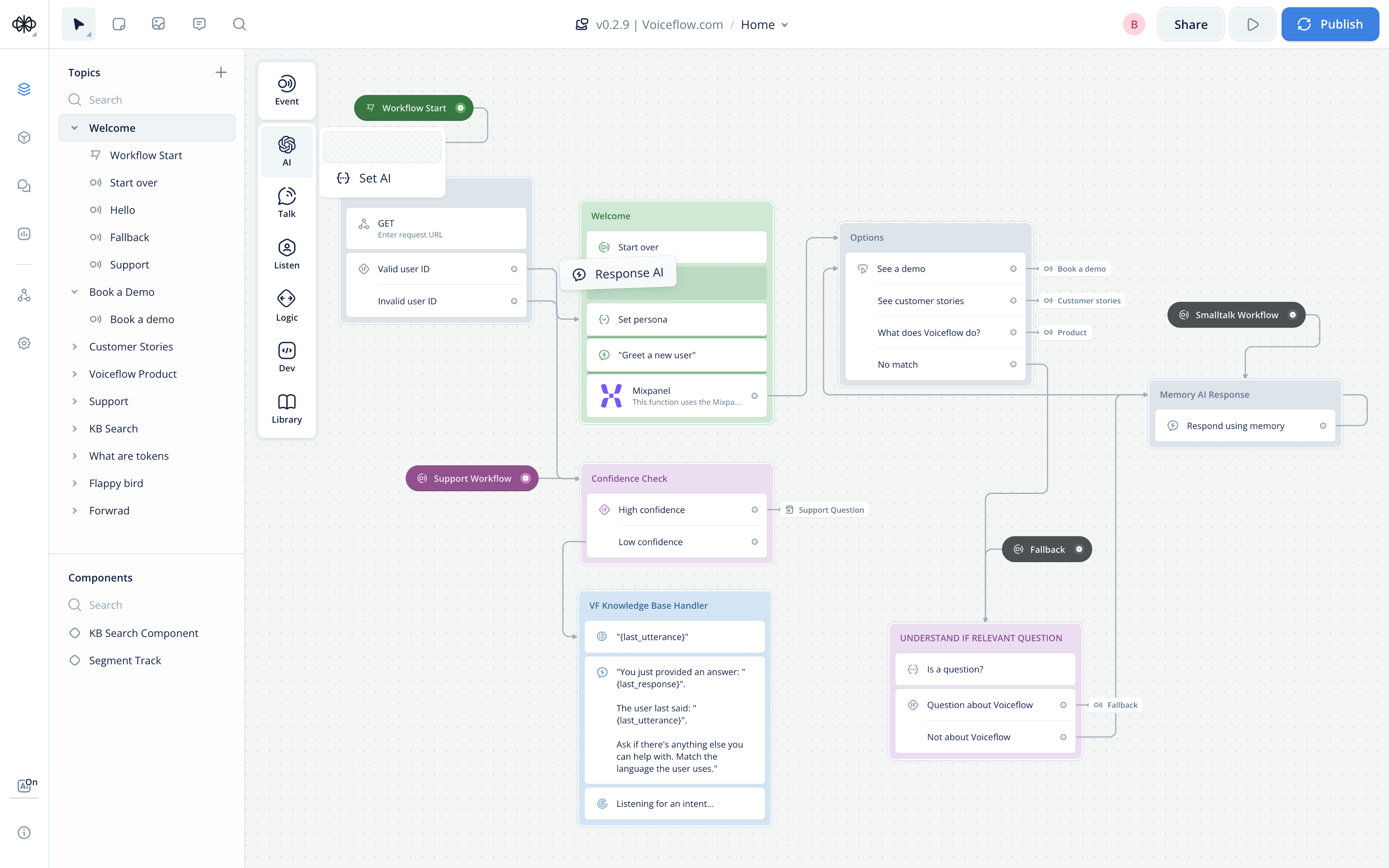
Make
Make es una plataforma avanzada de automatización que permite integrar diversas aplicaciones y servicios sin necesidad de programación. Su enfoque se basa en la creación de flujos de trabajo visuales mediante una interfaz intuitiva de arrastrar y soltar. Make facilita la comunicación entre distintas herramientas, optimizando procesos y mejorando la eficiencia en tareas repetitivas.
También permite conectar una amplia variedad de aplicaciones a través de APIs y conectores preconfigurados. Funciona mediante la creación de "escenarios", que son flujos de trabajo compuestos por módulos que representan diferentes aplicaciones y acciones. Cada escenario puede configurarse para ejecutarse en intervalos de tiempo específicos, activarse por eventos o ejecutarse manualmente.
La plataforma ofrece integración con cientos de aplicaciones populares como Google Sheets, Slack, Salesforce, HubSpot, Notion, entre otras. Además, permite el uso de webhooks y consultas HTTP para integrar sistemas personalizados o que no cuenten con conectores nativos.
Make ofrece un plan gratuito con límites en la cantidad de ejecuciones y funciones avanzadas. Para empresas y usuarios con necesidades más exigentes, dispone de planes de pago con características adicionales, mayor capacidad de integraciones y soporte avanzado.
Entre sus capacidades más destacadas se encuentra la posibilidad de crear automatizaciones sin conocimientos técnicos, lo que la hace accesible para una amplia gama de usuarios. Su escalabilidad permite manejar grandes volúmenes de datos y ejecutar múltiples procesos de manera simultánea, asegurando una integración eficiente entre diferentes sistemas.
Además, Make tiene la capacidad de integrarse con herramientas de inteligencia artificial y machine learning, lo que permite a los usuarios potenciar sus flujos de trabajo con capacidades avanzadas de análisis de datos, predicción y automatización inteligente. Estas integraciones posibilitan que los procesos interpreten información en tiempo real, tomen decisiones fundamentadas en modelos predictivos y optimicen su rendimiento de manera continua mediante algoritmos de aprendizaje automático. También ofrece la programación de tareas recurrentes o activadas por eventos en tiempo real, lo que brinda mayor control y automatización en distintos escenarios empresariales.
Funciones principales de Make:
- 𖦹
Automatización de Flujos de Trabajo: Permite conectar diferentes aplicaciones y servicios en secuencias lógicas para realizar tareas de manera automática. - 𖦹
Editor Visual: Una interfaz intuitiva que facilita la creación de flujos sin necesidad de escribir código. - 𖦹
Ejecutores y Disparadores: Permite configurar eventos y acciones que activan los escenarios automáticamente. - 𖦹
Integraciones con APIs y Webhooks: Posibilita la conexión con servicios externos personalizados. - 𖦹
Condiciones y Filtros Avanzados: Permite definir reglas para la ejecución de los flujos según criterios específicos. - 𖦹
Gestor de Datos: Ofrece herramientas para manipular, transformar y almacenar información de manera eficiente.
Ejemplo de configuración
Para configurar un escenario en Make, primero se accede a la plataforma y se crea un nuevo "escenario". Luego, se seleccionan y conectan las aplicaciones o servicios que se desean integrar. A continuación, se configuran los disparadores y acciones que definirán el flujo de trabajo, aplicando condiciones y filtros según las necesidades específicas del proceso. Una vez configurado, el escenario se guarda y se ejecuta para validar su funcionamiento y asegurar que cumple con los objetivos establecidos.
La exportación de modelos en Make se realiza compartiendo escenarios con otros usuarios o generando enlaces de acceso. Además, es posible clonar y modificar flujos para adaptarlos a diferentes necesidades empresariales.
Para más información, puedes visitar su página oficial: Make.
LiveKit
LiveKit es una plataforma de código abierto diseñada para la transmisión de audio y video en tiempo real a través de redes IP. Su infraestructura está optimizada para ofrecer baja latencia y alta escalabilidad, lo que permite la creación de aplicaciones interactivas como videollamadas, transmisiones en vivo, conferencias virtuales y experiencias de realidad aumentada.
LiveKit opera mediante WebRTC, un protocolo de comunicación en tiempo real ampliamente utilizado para la transmisión de medios. Su arquitectura descentralizada y basada en la nube permite a los desarrolladores integrar fácilmente sus servicios en aplicaciones web y móviles.
La integración con LiveKit se realiza mediante SDKs disponibles en diversos lenguajes de programación como JavaScript, Go y Swift, lo que facilita su implementación en una variedad de entornos y dispositivos. Además, ofrece soporte para la personalización de flujos de transmisión y control avanzado de sesiones multimedia.
Funciones principales de LiveKit:
- 𖦹
Transmisión en Tiempo Real: Permite la transmisión de audio y video con baja latencia. - 𖦹
Escalabilidad Dinámica: Soporta la gestión de miles de usuarios concurrentes sin afectar el rendimiento. - 𖦹
Compatibilidad con WebRTC: Facilita la integración con navegadores y aplicaciones móviles sin necesidad de plugins adicionales. - 𖦹
Control de Calidad Adaptativo: Ajusta la calidad de transmisión según la conexión de los usuarios para garantizar una experiencia óptima. - 𖦹
Soporte para Multiparty y Broadcast: Permite la creación de videollamadas grupales y eventos en vivo. - 𖦹
Seguridad y Encriptación: Implementa protocolos de seguridad avanzados para proteger la transmisión de datos.
LiveKit es una plataforma altamente flexible que permite construir soluciones de comunicación en tiempo real con un alto grado de personalización. Su arquitectura distribuida permite manejar cargas de trabajo de gran escala sin comprometer la calidad del servicio. Además, admite la integración con inteligencia artificial para funciones avanzadas como subtítulos automáticos, traducción en tiempo real y reconocimiento de voz. La optimización de recursos y su compatibilidad con redes 5G la convierten en una solución robusta para entornos exigentes como conferencias globales y plataformas de transmisión de contenido.
Para más información, puedes visitar su página oficial: LiveKit.

Chatbase
Chatbase es una plataforma que permite la creación, entrenamiento y análisis de chatbots con inteligencia artificial. Su objetivo principal es optimizar la experiencia conversacional mediante el uso de modelos avanzados de procesamiento del lenguaje natural (NLP). Gracias a su capacidad de personalización y escalabilidad, es una herramienta valiosa para empresas y desarrolladores que buscan mejorar la interacción con los usuarios.
Se utiliza para diseñar y mejorar chatbots en múltiples plataformas, proporcionando herramientas avanzadas de análisis e inteligencia artificial. Su funcionalidad permite optimizar la precisión de las respuestas y personalizar la interacción con los usuarios. Algunas de sus principales aplicaciones incluyen el soporte automatizado al cliente, la generación de respuestas inteligentes y la mejora continua de los asistentes mediante el análisis de conversaciones en tiempo real.
Un aspecto clave de Chatbase es su capacidad para evaluar el rendimiento de los chatbots. A través de métricas detalladas y reportes analíticos, los desarrolladores pueden identificar errores, mejorar la precisión de las respuestas y ajustar los modelos de conversación para una mayor eficiencia.
Chatbase es altamente flexible y compatible con diversas plataformas de mensajería y herramientas de inteligencia artificial. Se integra con servicios populares como WhatsApp, Facebook Messenger, Slack y Telegram, facilitando la implementación de asistentes conversacionales en diferentes entornos. Además, es compatible con sistemas de NLP como Google Dialogflow y OpenAI, lo que permite utilizar modelos avanzados de lenguaje para potenciar la interacción.
Las integraciones con CRM y bases de datos empresariales como Salesforce y HubSpot permiten que Chatbase extraiga y analice información para mejorar la personalización de las respuestas. Su capacidad para conectarse con APIs externas amplía aún más su funcionalidad, permitiendo el acceso a información en tiempo real y la automatización de procesos dentro de los chatbots.
Chatbase cuenta con varios elementos clave que hacen que su uso sea eficiente y flexible. Su sistema de entrenamiento de modelos permite mejorar la precisión de las respuestas mediante la retroalimentación de las conversaciones en tiempo real. A través del análisis de interacciones, Chatbase identifica patrones y optimiza la estructura de los diálogos para una mejor experiencia del usuario.
El motor de análisis y métricas es otro componente esencial de la plataforma. Proporciona información detallada sobre el rendimiento del chatbot, identificando áreas de mejora y detectando posibles errores en la conversación. Además, ofrece herramientas de segmentación de usuarios, lo que permite personalizar las respuestas según el contexto y el perfil del usuario.
La integración con múltiples canales garantiza que los chatbots creados con Chatbase puedan ser utilizados en diversas plataformas sin necesidad de configuraciones complejas. Desde sitios web hasta aplicaciones de mensajería, la versatilidad de Chatbase facilita su implementación en entornos empresariales y comerciales.
Para más información, puedes visitar su página oficial: Chatbase.

Ejemplo de uso
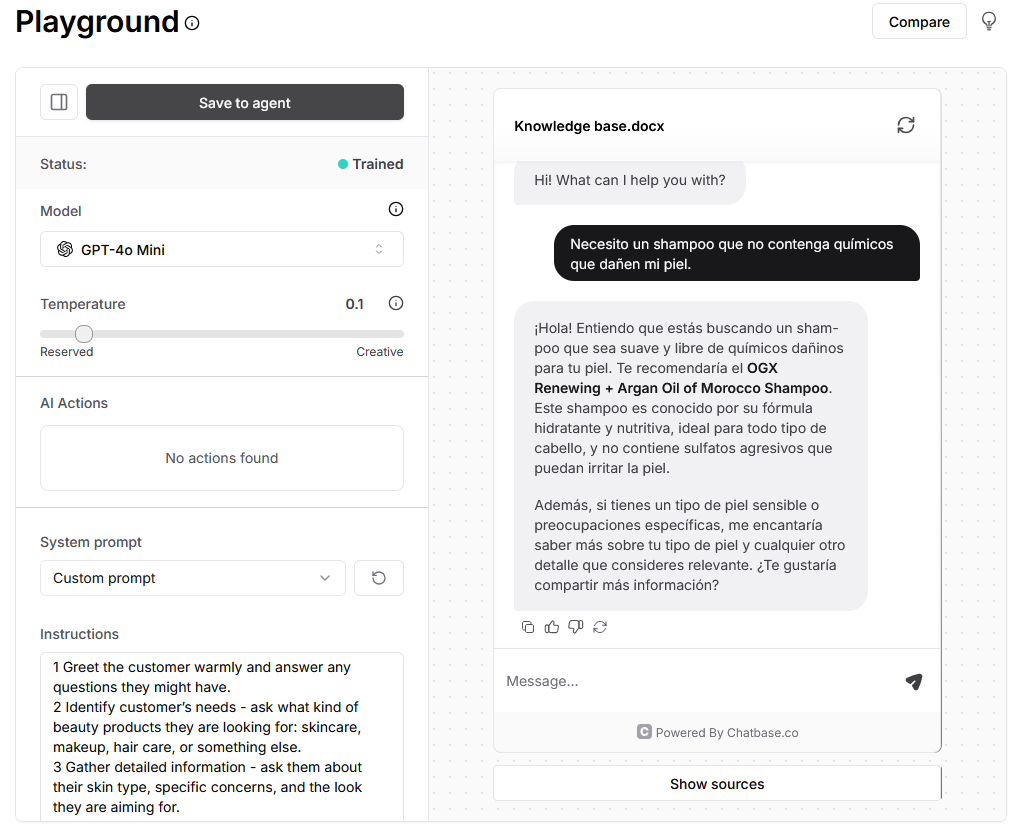
Para crear un chatbot en Chatbase, comienza accediendo a la plataforma y configurando un nuevo agente vinculado a la knowledge base de tu sitio web. Este paso es esencial para que el chatbot pueda acceder a la información relevante de tu marca y proporcionar respuestas precisas a tus clientes. Una vez configurado, asigna un prompt claro y efectivo, similar al que se muestra en este ejemplo, para guiar las interacciones del chatbot y asegurarte de que ofrezca respuestas alineadas con los valores y datos de tu empresa. Este enfoque garantiza que tu chatbot no solo sea funcional, sino también un representante confiable de tu marca.
Dante
Dante permite a empresas y desarrolladores construir asistentes virtuales personalizados capaces de responder preguntas, automatizar tareas y mejorar la experiencia del usuario en diversos sectores. Su funcionalidad se extiende al servicio al cliente, la generación de contenido automatizado y la optimización de flujos conversacionales en plataformas digitales.
Uno de los aspectos más destacados de Dante es su capacidad para aprender y mejorar continuamente mediante el análisis de conversaciones previas. Esto permite que los chatbots evolucionen con el tiempo, ajustando sus respuestas y optimizando su desempeño para satisfacer mejor las necesidades de los usuarios.
Dante es compatible con diversas plataformas y herramientas de inteligencia artificial, lo que facilita su integración en entornos empresariales y comerciales. Se puede conectar con sistemas de mensajería como WhatsApp, Facebook Messenger, Telegram y Slack, permitiendo una implementación rápida y eficaz. Además, es compatible con soluciones de CRM como Salesforce y HubSpot, facilitando la gestión de datos y la automatización de procesos.
Dante también se puede integrar con plataformas de análisis de datos y servicios de NLP como OpenAI, Google Dialogflow y Microsoft Azure, ampliando sus capacidades para comprender y generar lenguaje natural de manera avanzada. Esto lo convierte en una solución versátil para empresas que buscan mejorar su comunicación con los clientes mediante chatbots inteligentes.
Dante cuenta con varios elementos clave que lo hacen una plataforma potente y eficiente:
Editor Visual de Flujos Conversacionales: Permite diseñar interacciones mediante una interfaz intuitiva.Procesamiento del Lenguaje Natural (NLP): Utiliza modelos avanzados para comprender y generar respuestas precisas.Análisis y Reportes: Proporciona métricas detalladas sobre el rendimiento del chatbot, permitiendo su mejora continua.Integraciones con APIs: Facilita la conexión con bases de datos y otros servicios para enriquecer la interacción.Despliegue Multicanal: Permite implementar chatbots en distintas plataformas sin necesidad de desarrollos adicionales.
Para más información, puedes visitar su página oficial: Dante AI.
Diferencias entre Chatbase y Dante
Chatbase y Dante son dos plataformas diseñadas para la creación y gestión de chatbots, pero con enfoques y capacidades distintas. Chatbase es una herramienta basada en inteligencia artificial que permite entrenar y personalizar chatbots de manera sencilla, enfocándose en la automatización del servicio al cliente y la optimización de respuestas mediante el análisis de conversaciones. Por otro lado, Dante es una plataforma más avanzada que no solo permite la creación de chatbots, sino que también integra modelos de procesamiento del lenguaje natural (NLP) y herramientas de análisis más sofisticadas, lo que le permite aprender y mejorar continuamente con el tiempo.
Ambas plataformas tienen funciones clave en común, como la capacidad de integrar chatbots en diferentes canales de comunicación, incluyendo WhatsApp, Facebook Messenger, Telegram y sitios web. Sin embargo, Dante destaca por su capacidad de integración con plataformas más avanzadas como OpenAI, Google Dialogflow y Microsoft Azure, lo que le permite aprovechar modelos de IA más potentes. Además, Dante ofrece un editor visual más intuitivo para diseñar flujos conversacionales complejos, mientras que Chatbase se enfoca más en la facilidad de uso y en la rápida implementación de chatbots sin necesidad de conocimientos avanzados de programación.
En cuanto a sus diferencias principales, Chatbase está diseñado para empresas y desarrolladores que buscan una solución rápida y eficiente para la atención al cliente, con métricas detalladas para mejorar la precisión de las respuestas. En cambio, Dante es más flexible y escalable, permitiendo crear chatbots con mayor grado de personalización y capacidades avanzadas, como el análisis de emociones en las conversaciones y la automatización de tareas más complejas.
Respecto a su modelo de precios, ambas plataformas ofrecen versiones gratuitas con funciones limitadas y planes de pago que desbloquean herramientas más avanzadas. Chatbase suele ser más accesible para pequeñas empresas y emprendedores, mientras que Dante, al ofrecer más funcionalidades y soporte para modelos avanzados de IA, puede tener un costo más elevado en sus planes premium.
En términos de funcionalidades, Dante tiene una ventaja al ofrecer más herramientas para personalizar y mejorar la interacción de los chatbots, permitiendo incluso importar modelos previamente entrenados y analizar métricas avanzadas sobre el desempeño de las conversaciones. Chatbase, en cambio, se centra en la facilidad de uso y en la integración con plataformas de mensajería, lo que la hace una opción ideal para quienes buscan una implementación rápida sin necesidad de conocimientos técnicos profundos.