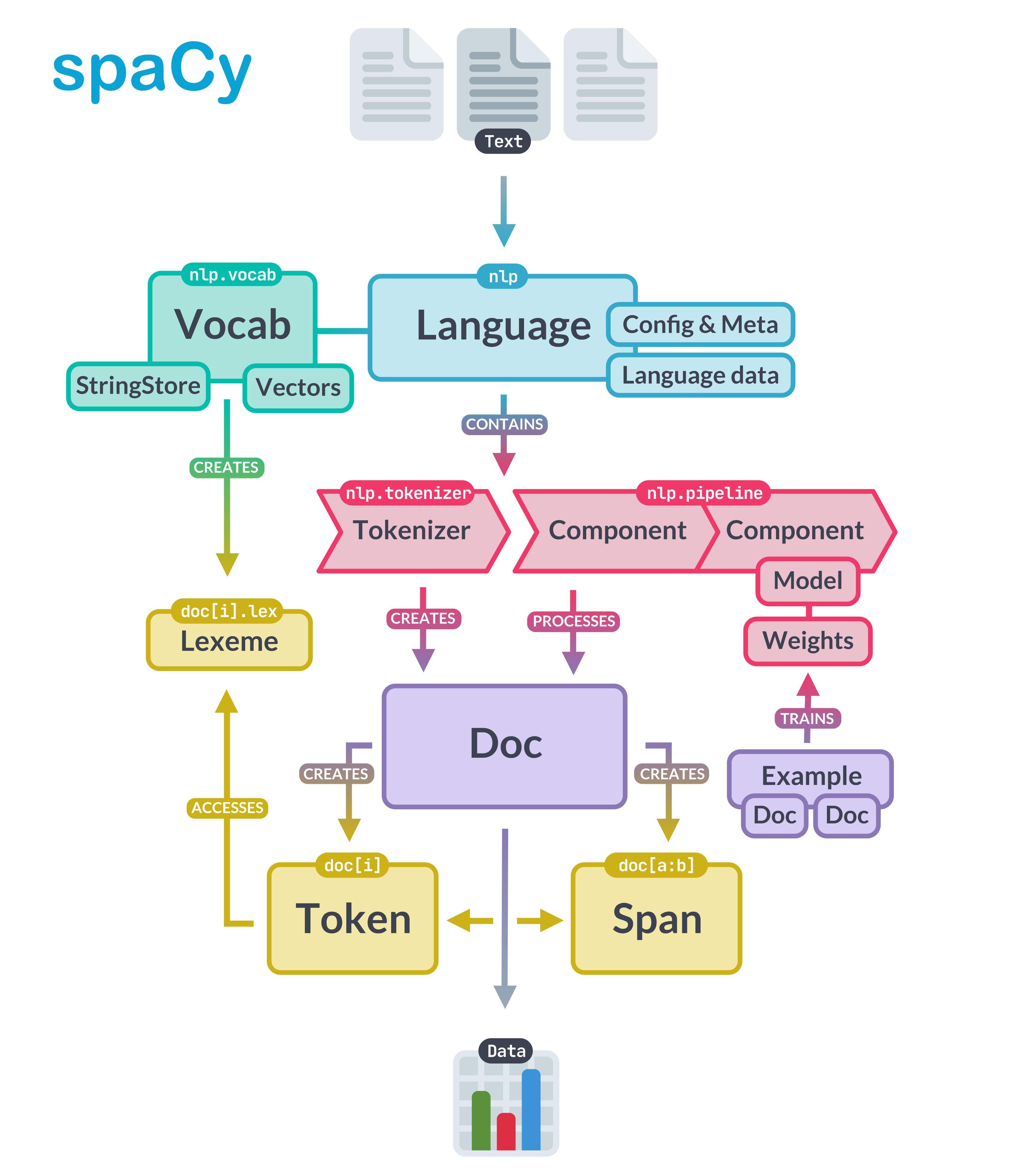
Procesamiento de Lenguaje Natural (NLP)
El Procesamiento de Lenguaje Natural (NLP, por sus siglas en inglés) es un campo de la inteligencia artificial y la lingüística computacional que permite a las máquinas comprender, interpretar y generar lenguaje humano. Esta tecnología es la base de muchas aplicaciones modernas, como chatbots, asistentes virtuales, motores de búsqueda, traducción automática y análisis de sentimientos.
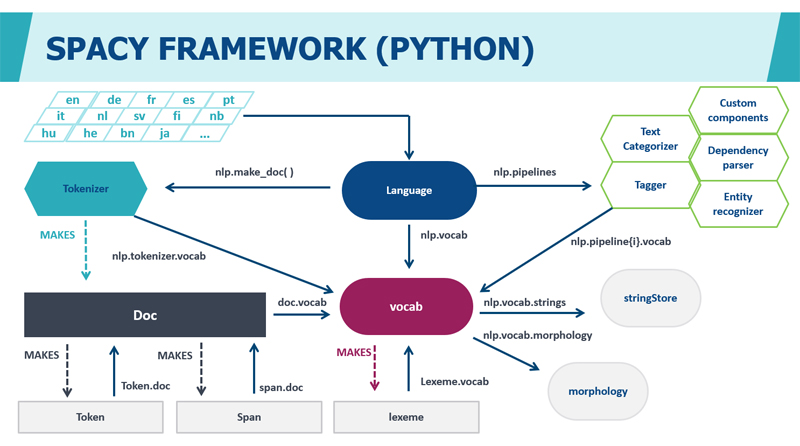
Librerías para NLP
El desarrollo de NLP ha sido facilitado por varias librerías especializadas que permiten procesar texto de manera eficiente. Algunas de las más populares son:
SpaCy: Optimizada para rendimiento y producción. Ofrece modelos preentrenados, procesamiento rápido y una API fácil de usar.NLTK (Natural Language Toolkit): Una de las librerías más antiguas y completas para NLP en Python. Proporciona herramientas para análisis léxico, sintáctico y semántico.Gensim: Se especializa en modelado de temas y procesamiento de grandes volúmenes de texto.Stanford NLP: Proporciona análisis gramatical avanzado y modelos estadísticos para múltiples idiomas.Transformers (Hugging Face): Permite el uso de modelos de aprendizaje profundo como BERT, GPT y T5 para tareas avanzadas de NLP.

Tokenización
La tokenización es el proceso de dividir un texto en unidades más pequeñas llamadas tokens. Un token puede ser una palabra, un signo de puntuación o incluso una oración.
Ejemplo con SpaCy:
Stemming
El stemming es la reducción de las palabras a su raíz mediante reglas heurísticas. No siempre produce palabras con significado real.
Ejemplo con NLTK:
Lemmatization
La lemmatización es más avanzada, ya que reduce una palabra a su forma base considerando su contexto gramatical.
Ejemplo con SpaCy:
POS Tagging (Part of Speech Tagging)
El etiquetado de partes del discurso (POS Tagging) asigna una categoría gramatical a cada palabra de un texto.
Ejemplo con SpaCy:
Word Vectors
Los word vectors representan palabras en un espacio multidimensional donde palabras con significado similar están más cercanas.
Ejemplo con SpaCy:
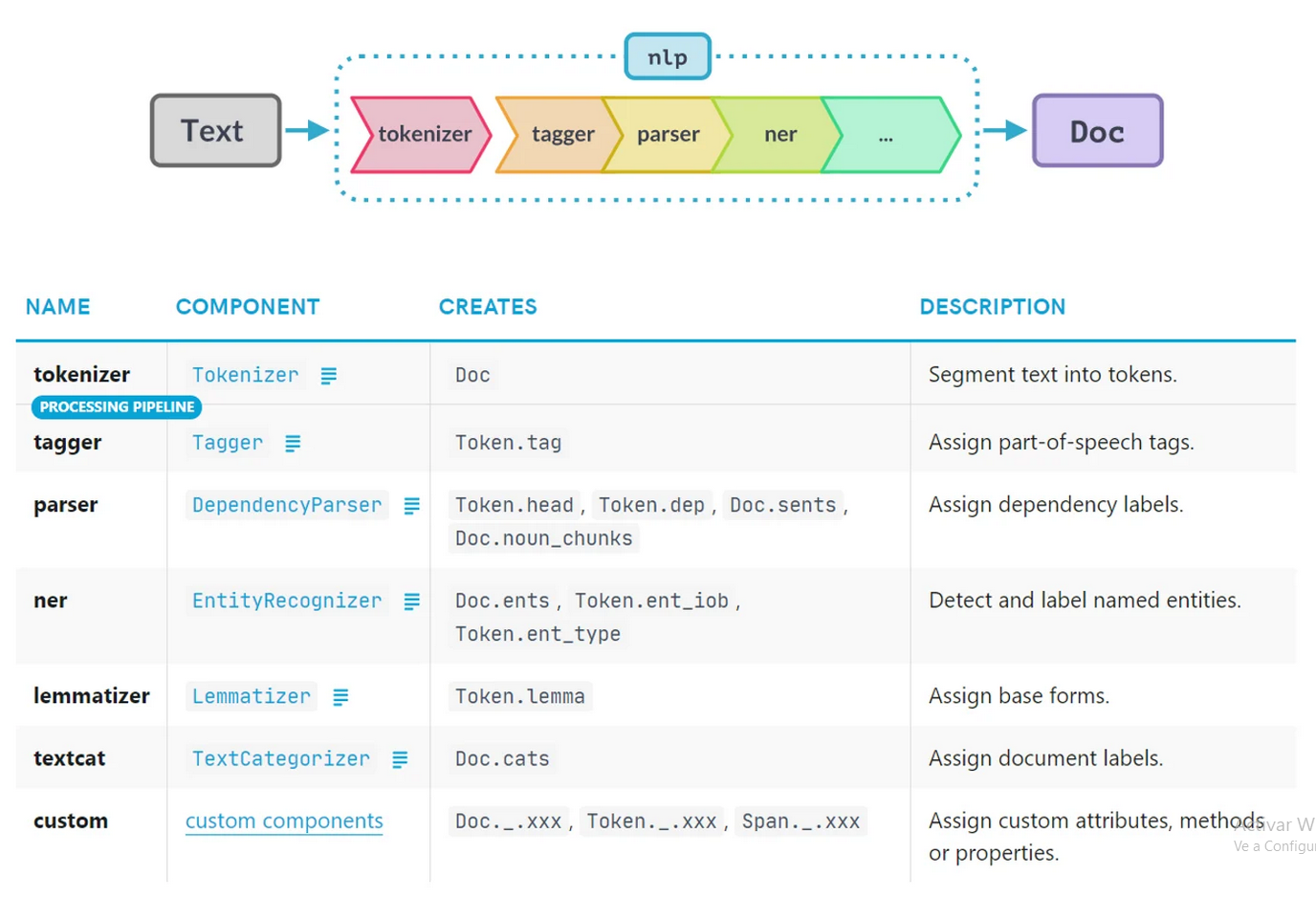
NLP Pipelines
Una pipeline de NLP es una serie de pasos por los cuales pasa un texto para su procesamiento.
Tokenizer: Divide el texto en tokens.Tagger: Asigna POS tags a los tokens.Parser: Analiza la estructura sintáctica.NER (Named Entity Recognition): Identifica entidades nombradas.
Ejemplo de pipeline en SpaCy:
Entity Ruler
Permite definir reglas personalizadas para la detección de entidades.
Ejemplo en SpaCy:
Matcher
El matcher permite buscar patrones específicos en un texto.
Ejemplo en SpaCy:
Custom Components
Los custom components en SpaCy permiten agregar funcionalidades personalizadas a la pipeline de procesamiento de texto. Estos componentes pueden realizar tareas específicas, como preprocesamiento de datos, validaciones adicionales o incluso cálculos personalizados basados en el contenido del texto. Se integran dentro de la pipeline y se ejecutan en orden junto con los otros procesadores como el tokenizer, POS tagger y Named Entity Recognizer (NER).
Estos componentes permiten extender las capacidades de SpaCy y adaptar su pipeline a necesidades específicas en distintos proyectos de NLP.
Expresiones Regulares en NLP
Las regex (expresiones regulares) son útiles para buscar patrones en texto, como correos electrónicos o fechas.
Ejemplo:
Usos Comunes de NLP
- Chatbots y asistentes virtuales (Alexa, Siri, Google Assistant)
- Análisis de sentimientos en redes sociales
- Traducción automática (Google Translate)
- Corrección gramatical (Grammarly)
- Clasificación de texto (spam vs. no spam)
Las aplicaciones de NLP abarcan múltiples áreas, desde la comprensión y generación de texto hasta el análisis semántico y la traducción automática. Entre las tareas más comunes se encuentran la clasificación de texto, el reconocimiento de entidades, la generación de lenguaje natural y la respuesta automática a preguntas. Gracias a la combinación de técnicas estadísticas, aprendizaje profundo y modelos basados en transformers, NLP sigue avanzando hacia una mayor precisión y eficiencia, facilitando la automatización de procesos lingüísticos complejos en diversas industrias, incluyendo la salud, el comercio, la educación y la seguridad informática.
Haz click aquí para ver algunos ejemplos de uso para NLP.