Apache Spark
Apache Spark es un motor de procesamiento de datos en paralelo, diseñado específicamente para grandes volúmenes de datos. Permite realizar cálculos distribuidos en un clúster de computadoras, ejecutando tareas de análisis de datos, procesamiento en tiempo real y aprendizaje automático de manera rápida y escalable. Spark facilita la distribución y paralelización de tareas para que puedan ejecutarse en múltiples nodos al mismo tiempo. Además, Spark es compatible con varios lenguajes de programación, como Python (a través de PySpark), Scala, Java y R.

Ubuntu
Ubuntu es un sistema operativo basado en Linux. Su función principal es gestionar los recursos físicos de una máquina (como la CPU, la memoria y el almacenamiento), proporcionando una plataforma sobre la cual se ejecutan aplicaciones y servicios. Aunque Ubuntu en sí no tiene ninguna funcionalidad específica para el procesamiento de big data, es un sistema operativo muy utilizado en servidores y en clústeres de computadoras que manejan grandes volúmenes de datos debido a su estabilidad, seguridad y flexibilidad.
Es común instalar Apache Spark en servidores con Ubuntu. Esto permite que Spark aproveche las capacidades de Ubuntu para gestionar los recursos de hardware, mientras Spark maneja el procesamiento distribuido de los datos.
En un entorno de big data, Ubuntu proporciona la base sobre la cual Spark se instala y ejecuta para distribuir y procesar datos masivos de forma rápida y eficiente.
Arquitectura
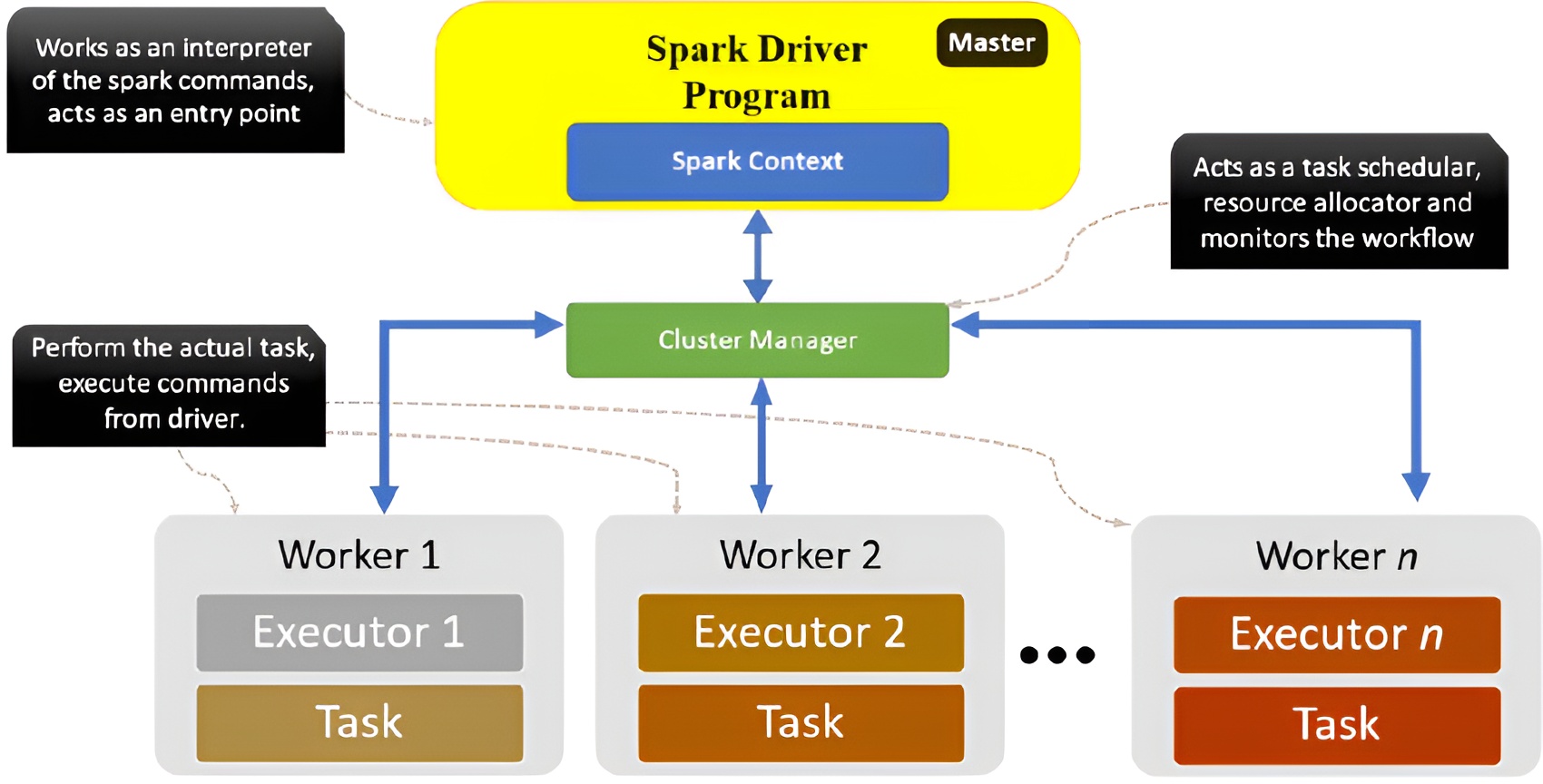
En Apache Spark (y en muchos otros sistemas distribuidos), el clúster se organiza en una arquitectura Master-Slave (Maestro-Esclavo), donde hay un nodo maestro y varios nodos trabajadores (workers). Esta estructura permite una distribución y administración eficiente del trabajo en el clúster.
Apache Spark se divide en:
- ▸
Nodo Maestro (Master): - 🔸El nodo maestro coordina y administra el clúster.
- 🔸Asigna tareas a los nodos trabajadores y realiza un seguimiento de su progreso.
- 🔸Maneja la división y distribución de los trabajos (o "jobs") que Spark recibe para procesar.
- 🔸Gestiona la división de tareas en subtareas más pequeñas y la asignación de estas a los nodos trabajadores.
- ▸
Nodos Trabajadores (Workers): - 🔸Los nodos trabajadores realizan el procesamiento real de los datos.
- 🔸Cada worker tiene múltiples ejecutores (executors) que ejecutan las tareas específicas asignadas por el nodo maestro.
- 🔸Los workers reciben sus tareas del nodo maestro y ejecutan operaciones en los datos, como filtros, mapeos, agregaciones, etc.
- 🔸Cada worker se encarga de una parte del conjunto de datos, procesándolos en paralelo con otros workers, lo que permite manejar grandes volúmenes de datos de manera rápida.
- ▸
Driver: - 🔸El Driver es la aplicación que envía el trabajo al clúster. Inicia el proceso de cálculo en Spark, definiendo la lógica del procesamiento y los datos que se van a analizar.
- 🔸Interactúa directamente con el nodo maestro para crear un DAG (gráfico acíclico dirigido) de tareas, que luego es gestionado por el maestro.
- ▸
Cluster Manager: - 🔸Apache Spark puede ejecutarse en varios sistemas de gestión de clústeres, como YARN (en Hadoop), Mesos o Kubernetes.
- 🔸El gestor del clúster asigna recursos a los nodos del clúster (como memoria y CPU), de modo que Spark pueda ejecutar tareas de manera eficiente.
Flujo de trabajo
- El Driver inicia una aplicación Spark, enviando el trabajo al nodo maestro.
- El nodo maestro recibe el trabajo, lo descompone en tareas y las distribuye entre los nodos trabajadores.
- Los workers ejecutan las tareas en paralelo, utilizando sus propios recursos de CPU y memoria.
- Los resultados parciales de cada worker se envían de regreso al maestro, que luego los combina para producir el resultado final.
Ventajas de la arquitectura Maestro-Trabajador:
Escalabilidad: Permite procesar grandes cantidades de datos distribuyendo el trabajo entre varios nodos.Tolerancia a fallos: Si un nodo trabajador falla, el maestro puede reasignar la tarea a otro nodo disponible.Flexibilidad: Se puede usar con distintos sistemas de gestión de clústeres y en la nube o en instalaciones locales.
Entonces, sí, hay un nodo maestro en la orquestación de clústeres en Spark. Este nodo maestro coordina y organiza el procesamiento, mientras que los nodos trabajadores ejecutan las tareas distribuidas, permitiendo manejar datos a gran escala con eficiencia y rapidez.
Pandas vs PySpark
PySpark y pandas son similares en cuanto a su propósito, ya que ambas herramientas se utilizan para manipular y analizar datos. Sin embargo, tienen diferencias clave, especialmente en el tipo de datos que manejan y el tamaño de los conjuntos de datos para los que están diseñados.
Las diferencias principales entre PySpark y pandas son:
Escalabilidad y manejo de grandes volúmenes de datos: - ◉
Pandas: Su principal estructura de datos es el DataFrame, que es una tabla en memoria con filas y columnas. Pandas proporciona una gran cantidad de métodos y funciones para trabajar con datos en formato tabular de manera muy eficiente. - ◉
PySpark: También utiliza DataFrames, pero estos son estructuras distribuidas que se procesan en paralelo en un clúster de Spark. Esto hace que algunos métodos y operaciones en PySpark sean diferentes o no tan directos como en pandas, ya que deben realizarse de forma distribuida. Estructura de datos: - ◉
Pandas: Es muy rápido en operaciones en una sola máquina, especialmente para conjuntos de datos pequeños y medianos. - ◉
PySpark: Aunque tiene una latencia más alta en la inicialización y ciertas operaciones, debido a la coordinación entre máquinas en el clúster, su ventaja es que puede procesar terabytes de datos en paralelo, lo que lo hace mucho más rápido que pandas para grandes volúmenes. Velocidad de procesamiento: - ◉
Pandas: Tiene una gran cantidad de funciones para manipular datos en memoria, y su sintaxis es bastante sencilla y directa. - ◉
PySpark: Tiene una sintaxis algo similar a pandas, pero algunas operaciones pueden ser menos intuitivas debido a la necesidad de realizar procesamiento distribuido. Además, muchas funciones deben expresarse usando el API de Spark, que tiene sus propias particularidades. Uso de funciones y operaciones: - ◉
Pandas: Para proyectos que pueden manejarse en una sola máquina y cuando el tamaño de los datos es lo suficientemente pequeño como para caber en la memoria RAM. - ◉
PySpark: Cuando trabajas con big data, necesitas procesamiento en paralelo o estás trabajando en un entorno de clúster.
Ejemplo de código de comparación
⌨️ Una comparación simple entre pandas y PySpark para una operación común (filtrar datos):
PySpark
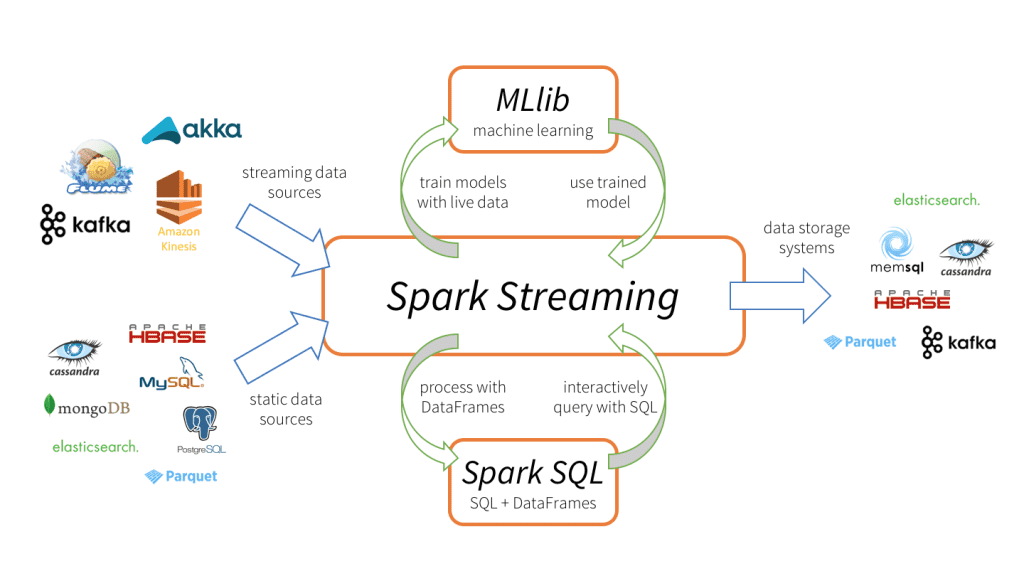
PySpark es una interfaz de Python para Apache Spark, un motor de procesamiento de datos de código abierto diseñado para analizar grandes volúmenes de datos de manera rápida y eficiente. Spark permite distribuir y procesar datos en paralelo en varios nodos de un clúster, lo cual lo hace ideal para manejar grandes conjuntos de datos. PySpark facilita el uso de Spark desde Python, permitiendo a los desarrolladores manipular grandes cantidades de datos y realizar tareas de machine learning, análisis de datos y ETL (extracción, transformación y carga) con un enfoque similar a pandas.
PySpark es especialmente útil cuando:
- Tienes grandes volúmenes de datos que no caben en la memoria de una sola máquina.
- Quieres realizar cálculos distribuidos de manera rápida y en paralelo.
- Buscas integrar machine learning y análisis de datos escalables en un clúster.
Para usar PySpark en tu entorno local o en un clúster, necesitas instalar PySpark.
Una vez instalado, puedes iniciar PySpark en un entorno interactivo de Python (por ejemplo, Jupyter Notebook) o ejecutar scripts de Python que usen PySpark.
⌨️ Aquí hay un ejemplo simple de cómo iniciar un
⌨️ PySpark permite cargar datos desde archivos CSV, JSON, Parquet y otras fuentes. Por ejemplo, para leer un archivo CSV:
⌨️ Luego puedes usar métodos similares a los de pandas para manipular los datos:
⌨️ PySpark también tiene una biblioteca de machine learning llamada
Para aprovechar al máximo PySpark, generalmente se usa en un clúster de Spark. Esto se puede configurar en servicios en la nube (como AWS o Google Cloud) o en sistemas distribuidos como Hadoop.
Ejemplos
Haz click aquí para ver algunos ejemplos de uso con PySpark.
Para más ejemplos, visita la siguiente página con documentación relacionada.
Configuración del cluster
Para configurar un clúster de Spark con un maestro y dos workers, hay algunos pasos adicionales además de simplemente instalar pyspark. La instalación de pyspark te permitirá ejecutar Spark en tu computadora, pero no configura un clúster completo. Aquí te explico los pasos detallados para lograrlo en tu distribución de Linux:
- Paso 1: Instalar Java
- Paso 2: Descargar e instalar Apache Spark
- Paso 3: Instalar PySpark y Jupyter
- Paso 4: Configurar el clúster de Spark
- Paso 5: Iniciar el clúster
- Paso 6: Ejecutar trabajos
- Paso 7: Detener el clúster
Ve a la página oficial de Apache Spark y descarga la versión más reciente (o una versión compatible con PySpark y Jupyter).
Configura las variables de entorno para que puedas acceder a Spark desde cualquier terminal:
Abre
En el archivo
Abre
Este archivo debe contener la lista de los nodos worker que participarán en el clúster.
Esto iniciará el master de Spark. El master estará escuchando por defecto en http://localhost:8080, aunque puedes cambiar la dirección o el puerto si lo necesitas.
Ahora, en cada uno de los nodos worker, necesitas iniciar los workers. Asegúrate de que cada worker tenga acceso a la máquina master y que puedan comunicarse a través de la red.
Ahora puedes verificar el estado de tu clúster. Ve a la interfaz web del master en tu navegador:
⦿
Si los workers están bien conectados, deberías ver el estado de los workers en la interfaz web.
Configurar el entorno de Jupyter para usar Spark
Para conectarte al clúster de Spark desde Jupyter, debes configurar las variables de entorno que Spark necesita para conectarse a tu master y workers. Hay varias maneras de hacerlo, pero una de las formas más simples es exportando estas variables de entorno antes de iniciar Jupyter.
Puedes establecer las variables de entorno necesarias para Spark directamente en la terminal o dentro de tu script de Jupyter. Estas variables indican a Spark que debe conectarse a tu clúster en lugar de ejecutarse en un modo local.
En tu terminal (donde vayas a iniciar Jupyter), exporta las siguientes variables antes de iniciar Jupyter:
Una vez que hayas exportado las variables de entorno, puedes iniciar Jupyter y conectarte al nodo master.
Cuando hayas terminado, puedes detener el master y los workers con los siguientes comandos: