



Speech Recognition
SpeechRecognition es una librería de Python diseñada para convertir voz en texto de manera eficiente. Funciona como una interfaz para múltiples motores de reconocimiento de voz, incluyendo Google Web Speech API, Sphinx, Microsoft Bing Voice Recognition, entre otros. Su capacidad para procesar audio en distintos formatos y su facilidad de integración la convierten en una herramienta útil para el desarrollo de asistentes virtuales, transcripción automática y otras aplicaciones de inteligencia artificial basadas en voz.
SpeechRecognition admite múltiples idiomas, aunque su soporte varía según el motor de reconocimiento utilizado. Por ejemplo, Google Web Speech API ofrece compatibilidad con más de 100 idiomas, mientras que PocketSphinx, una de las opciones offline, tiene soporte limitado a algunos idiomas como inglés y español.
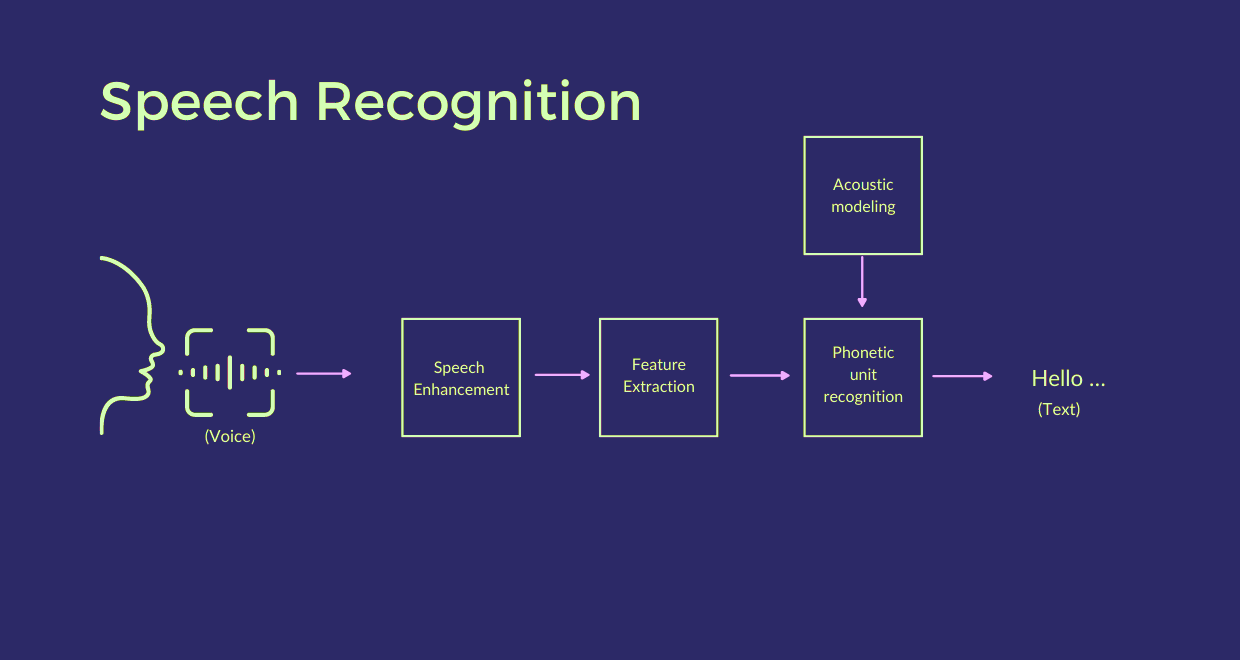
Procesamiento de Voz
El procesamiento de voz implica la conversión de señales de audio en texto. Para lograrlo, se toman en cuenta varios factores técnicos:
Sample Rate: Indica la cantidad de muestras por segundo en un archivo de audio. Un valor común es 44.1 kHz (44,100 muestras por segundo).Sample Width: Representa el número de bytes utilizados para almacenar cada muestra de audio.Canales: Un archivo de audio puede ser mono (un canal) o estéreo (dos canales).Frames: Son los fragmentos en los que se divide el audio para su análisis.
La calidad y precisión del reconocimiento dependen en gran medida de estos parámetros, ya que afectan la claridad y fidelidad de la voz capturada.
Tipos de Archivos de Audio Soportados
La librería puede procesar archivos de audio en diversos formatos, incluyendo:
WAV: Formato sin compresión con alta calidad de audio.AIFF: Similar a WAV pero con mayor compatibilidad en dispositivos Apple.FLAC: Formato comprimido sin pérdida de calidad.OGG: Alternativa comprimida y abierta al MP3.
Instalación de paquetes
Ejemplo de Uso
PocketSphinx es un motor de reconocimiento de voz offline compatible con SpeechRecognition. A continuación, se muestra un ejemplo de cómo utilizarlo:
Este código carga un archivo de audio en formato WAV, lo procesa con PocketSphinx y devuelve el texto reconocido. Es una opción útil para proyectos que requieren reconocimiento de voz sin conexión a internet.
Haz click aquí para ver algunos ejemplos de uso con Reconocimiento de voz.
