



Transformers
Los modelos basados en transformers han revolucionado el campo del aprendizaje profundo en los últimos años, y se han convertido en una de las tecnologías más influyentes en el procesamiento del lenguaje natural (NLP), la visión por computadora, la traducción automática y muchas otras áreas. En este artículo, exploraremos en detalle qué son los transformers, cómo funcionan, los diferentes tipos que existen y sus aplicaciones en el mundo del aprendizaje profundo.
Estructura y Funcionamiento
Los transformers son una arquitectura de red neuronal diseñada para manejar datos secuenciales, como texto o series temporales. La característica clave de los transformers es su capacidad para procesar secuencias de datos completas de una sola vez, en lugar de procesarlas de manera secuencial como lo hacen las redes neuronales recurrentes (RNN) o las convolucionales (CNN). Esto se logra a través de un mecanismo llamado "atención", que permite a la red enfocarse en partes específicas de la entrada.
La arquitectura transformer consta de dos componentes principales: el codificador y el decodificador. El codificador toma la entrada y la procesa para extraer características relevantes, mientras que el decodificador genera la salida deseada basándose en las características extraídas por el codificador. Esta estructura se utiliza en tareas de secuencia a secuencia, como la traducción automática.
Codificador y Decodificador en Transformers
En las arquitecturas de transformers, el codificador y el decodificador son componentes esenciales que trabajan juntos para procesar secuencias de datos. A continuación, se detallan sus funciones y cómo interactúan:
Captura Características: El codificador toma una secuencia de entrada y descompone esa secuencia en características significativas. Esto se logra mediante capas de atención y transformaciones lineales que permiten al modelo enfocarse en partes específicas de la secuencia.Atención Multi-Cabezal: El codificador utiliza la atención multi-cabezal para calcular las relaciones entre las palabras o elementos en la secuencia. Cada cabeza de atención aprende diferentes relaciones, lo que permite una comprensión más completa del contexto.Transformación Posicional: Las redes neuronales, por sí mismas, no tienen conocimiento sobre la posición de las palabras en una secuencia. Para abordar esto, el codificador agrega información posicional a las características, lo que permite al modelo considerar la posición relativa de los elementos.Codificación de Contexto: El resultado del codificador es una representación codificada de la secuencia de entrada. Esta representación conserva información importante sobre las relaciones entre elementos en la secuencia.
Generación de Salida: El decodificador toma la representación codificada generada por el codificador y produce una secuencia de salida. Esto se hace de manera autoregresiva, lo que significa que el decodificador genera un elemento a la vez y utiliza su propia salida anterior como entrada para generar el siguiente.Atención Contextual: Al igual que el codificador, el decodificador utiliza capas de atención para centrarse en partes relevantes de la secuencia de entrada codificada. Esto permite que el decodificador genere una salida coherente y contextualmente relevante.Predicción de Próximos Elementos: En muchas tareas, como la traducción automática, el decodificador genera un elemento en cada paso de tiempo hasta que se produce un token de finalización o se alcanza una longitud máxima de secuencia.
Aspectos Importantes de Transformers
- 𖦹
Atención Posicional: Los transformers incorporan información sobre la posición de las palabras o elementos en una secuencia mediante la adición de vectores de posición a las representaciones de entrada. Esto permite al modelo entender el orden de los elementos. - 𖦹
Escalabilidad: Los transformers son altamente escalables y pueden entrenarse en modelos gigantes con millones o incluso miles de millones de parámetros, lo que los hace adecuados para tareas de procesamiento de lenguaje natural a gran escala. - 𖦹
Transferencia de Aprendizaje: Los modelos pre-entrenados, como BERT y GPT, se han convertido en bloques de construcción fundamentales para muchas aplicaciones de aprendizaje profundo. Los modelos pre-entrenados se afinan (fine-tune) para tareas específicas con conjuntos de datos más pequeños. - 𖦹
Atención Global: Los transformers pueden considerar relaciones globales entre elementos en una secuencia, en lugar de depender únicamente de relaciones locales, como en las redes convolucionales. - 𖦹
Paralelización: Debido a su capacidad para procesar secuencias completas de datos de una sola vez, los transformers se pueden paralelizar eficientemente en hardware moderno, lo que acelera el entrenamiento y la inferencia. - 𖦹
Avances en Visión por Computadora: La aplicación de transformers en tareas de visión por computadora ha llevado a avances significativos, como Vision Transformers (ViTs), que rivalizan con las redes convolucionales en la clasificación de imágenes y la detección de objetos.
Los transformers son una arquitectura de aprendizaje profundo versátil y poderosa que ha impulsado avances significativos en una variedad de campos. Su capacidad para capturar relaciones a largo plazo, procesar secuencias de datos y buscar características en otras entradas los convierte en una herramienta fundamental en la caja de herramientas del aprendizaje profundo.
Vectores Query y Key
Dentro de la arquitectura de transformers, los vectores Query (consulta) y Key (clave) son componentes esenciales que desempeñan un papel fundamental en la atención (self-attention mechanism). Esta atención es un mecanismo crucial que permite a los transformers analizar relaciones entre diferentes partes de una secuencia de entrada y es la base de muchas de sus capacidades, como la traducción automática y el procesamiento de lenguaje natural.
Los vectores Query y Key son componentes utilizados en el cálculo de la atención en los transformers. Junto con los vectores Value (valor), se utilizan para calcular los pesos de atención que se aplican a cada elemento de la secuencia de entrada. Los tres vectores (Query, Key y Value) se obtienen a partir de la misma representación de entrada pero se transforman de manera diferente antes de realizar la atención.
- ◒
Vector Query (Q): El vector Query se utiliza para formular preguntas sobre la relación entre diferentes partes de la secuencia de entrada. Se calcula multiplicando la representación de entrada por una matriz de pesos (aprendida durante el entrenamiento). Cada vector Query se utiliza para comparar con los vectores Key y determinar qué elementos de la entrada son más relevantes para una posición específica. - ◕
Vector Key (K): El vector Key se utiliza para codificar información sobre la secuencia de entrada de manera que se puedan realizar comparaciones eficientes con los vectores Query. Similar al vector Query, se calcula multiplicando la representación de entrada por otra matriz de pesos.
El funcionamiento de los vectores Query y Key se basa en el cálculo de productos escalares (dot product) entre ellos. Estos productos escalares determinan la similitud entre los vectores Query y Key, y se utilizan para asignar pesos de atención a cada elemento de la secuencia de entrada. Los pasos principales son los siguientes:
Cálculo de los Vectores Query y Key: Se calculan los vectores Query (Q) y Key (K) a partir de la representación de entrada. Esto se hace multiplicando la representación de entrada por las matrices de pesos correspondientes.Cálculo de la Atención: Para calcular la atención, se realiza el producto escalar entre los vectores Query y Key transpuestos. Esto genera una matriz de puntuaciones de atención que refleja la similitud entre cada elemento de la secuencia con respecto a las preguntas formuladas en los vectores Query.Aplicación de la Softmax: Las puntuaciones de atención se normalizan utilizando la función Softmax, lo que da como resultado pesos de atención que suman uno. Esto determina cuánta atención se debe prestar a cada elemento de la secuencia.Cálculo de los Vectores Valor (V): Además de los vectores Query y Key, se calculan los vectores Valor (V) a partir de la representación de entrada. Estos vectores representan el contenido de la secuencia original.Cálculo de la Atención Ponderada: Se realiza la multiplicación de los pesos de atención obtenidos en el paso anterior por los vectores Valor. Esto da como resultado la atención ponderada, que es una combinación lineal de los elementos de la secuencia original, resaltando los elementos más relevantes según los vectores Query.
Los vectores Query y Key son esenciales en la arquitectura de transformers debido a su capacidad para modelar relaciones entre elementos de la secuencia de entrada. Esto permite a los transformers aprender dependencias a largo plazo y realizar tareas de procesamiento de lenguaje natural, traducción automática, resumen de texto y más.
Al ajustar los pesos de atención en función de la similitud entre los vectores Query y Key, los transformers pueden centrarse en partes específicas de la entrada, lo que les permite capturar patrones complejos y representar información de manera efectiva.
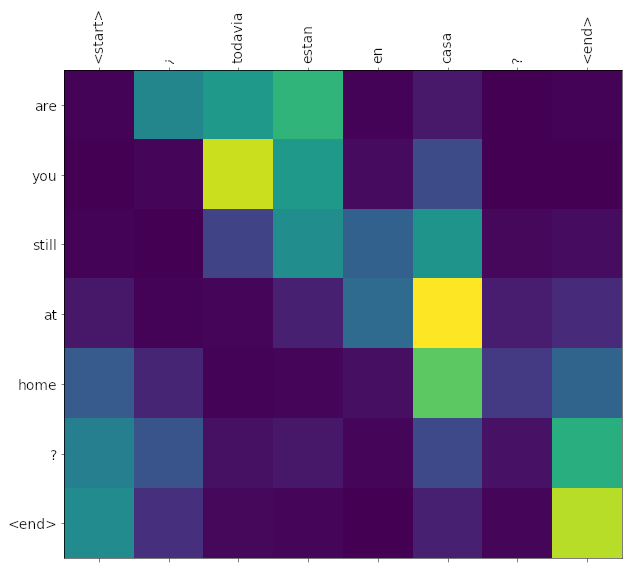
Imagina que estás traduciendo una oración de un idioma a otro utilizando un modelo de transformer. La oración en el idioma de origen es: "El gato está en la mesa". Quieres determinar qué palabras en la oración original son las más importantes para traducir la palabra "gato" correctamente al idioma de destino.
En este caso, el vector Query (consulta) se usa para formular una pregunta sobre la oración original. La pregunta sería algo como: "¿Qué palabras están relacionadas con 'gato' en la oración original?". El modelo crea un vector Query para esta pregunta.
El vector Key (clave) se utiliza para codificar información sobre todas las palabras en la oración original. Cada palabra en la oración tiene su propio valor en el vector Key.
Ahora, se calcula la atención comparando el vector Query con los vectores Key. Esto se hace mediante el cálculo de productos escalares (dot products) entre el vector Query y cada vector Key correspondiente a las palabras de la oración original. Los productos escalares indican la similitud entre el vector Query y cada palabra.
Por ejemplo, si el vector Query para la palabra "gato" es similar al vector Key para las palabras "gato" y "mesa", esos productos escalares serán más altos. Esto significa que el modelo considera que las palabras "gato" y "mesa" están relacionadas con "gato" en la oración.
Luego, se aplica la función Softmax a los productos escalares. La función Softmax normaliza estos valores y los convierte en pesos de atención. Los pesos de atención indican cuánta importancia se debe dar a cada palabra en la oración original en relación con la palabra "gato".
Si la palabra "gato" tiene un alto peso de atención, significa que es crucial para traducir "gato" correctamente.
Finalmente, se calcula la atención ponderada multiplicando los pesos de atención por los vectores Valor. Los vectores Valor representan el significado de cada palabra en la oración original.
Por ejemplo, si la palabra "gato" tiene un alto peso de atención, su vector Valor contribuirá más a la traducción final. Esto permite al modelo centrarse en las partes más relevantes de la oración original al traducir "gato" al idioma de destino.
Los vectores Query y Key permiten al modelo transformer analizar las relaciones entre palabras y decidir qué partes de la entrada son más relevantes para la tarea en cuestión. Esto facilita la traducción precisa y es fundamental en muchas aplicaciones de procesamiento de lenguaje natural y aprendizaje automático.
Tipos de Transformers
BERT (Bidirectional Encoder Representations from Transformers): Diseñado para comprender el contexto bidireccional en el procesamiento del lenguaje natural. Es ampliamente utilizado en tareas de NLP, como la clasificación de texto y la generación de texto.GPT (Generative Pre-trained Transformer): Utilizado para la generación de texto, GPT es conocido por su capacidad para producir texto coherente y contextualmente relevante.T5 (Text-to-Text Transfer Transformer): Un transformer que trata todas las tareas de procesamiento del lenguaje natural como una tarea de conversión de texto a texto, lo que lo hace altamente versátil.BERT Variaciones Especializadas: Se han desarrollado variantes de BERT para tareas específicas, como BioBERT para la biomedicina y SciBERT para la literatura científica.Transformer-XL: Diseñado para manejar secuencias más largas y resolver el problema de la dependencia de largo plazo en las RNN.Vision Transformers (ViTs): Aplicación de la arquitectura transformer en tareas de visión por computadora, como la clasificación de imágenes y la detección de objetos.BERT for Pre-training of Audio: Una extensión de BERT que se utiliza en el procesamiento de audio y el procesamiento de voz.Megatron: Diseñado para entrenar modelos a gran escala, es utilizado por empresas como Facebook para entrenar modelos de lenguaje gigantes.XLNet: Propone una arquitectura de transformer más poderosa que BERT, superando muchas limitaciones.DistilBERT: Una versión más pequeña y eficiente de BERT, adecuada para aplicaciones con recursos limitados.
Aplicaciones en Aprendizaje Profundo
Los transformers han habilitado una serie de avances en el aprendizaje profundo y se aplican en diversas áreas, incluyendo:
- ∘
Procesamiento del Lenguaje Natural (NLP): Para tareas de traducción automática, resumen de texto, análisis de sentimientos, chatbots y más. - ∘
Visión por Computadora: Para la clasificación de imágenes, la detección de objetos y la segmentación de imágenes. - ∘
Procesamiento de Audio: En el reconocimiento de voz, la generación de voz y la transcripción de audio. - ∘
Recomendación: Para sistemas de recomendación en plataformas de streaming y comercio electrónico. - ∘
Biomedicina: En tareas como el procesamiento de texto médico y la extracción de información de registros médicos. - ∘
Juegos: En el desarrollo de agentes de IA para juegos y juegos generados por IA. - ∘
Modelos de Lenguaje Multilingüe: Que abordan desafíos de procesamiento de lenguaje en varios idiomas.
Herramientas
La creación de modelos de transformers y su entrenamiento suele requerir el uso de librerías y herramientas específicas. Algunas de las librerías y herramientas más comunes para trabajar con transformers incluyen:
- 𖦹
Hugging Face Transformers: Hugging Face proporciona una de las librerías más populares y completas para trabajar con transformers en el aprendizaje profundo. Su librería Transformers ofrece una amplia variedad de modelos pre-entrenados, como BERT, GPT-2, RoBERTa, y muchos más, junto con herramientas para entrenar, ajustar y usar estos modelos en tareas específicas. - 𖦹
PyTorch y TensorFlow: PyTorch y TensorFlow son dos de los principales marcos de aprendizaje profundo utilizados para implementar arquitecturas de transformers. Ambos marcos tienen módulos y extensiones dedicados para crear y entrenar modelos de transformers. PyTorch es conocido por su flexibilidad y facilidad de uso, mientras que TensorFlow es ampliamente utilizado en la producción y tiene herramientas como TensorFlow Serving para servir modelos. - 𖦹
Transformers de Hugging Face: Además de su librería Transformers, Hugging Face ofrece un repositorio llamado "Transformers" que proporciona implementaciones de transformers en PyTorch y TensorFlow. Estos modelos pre-entrenados se pueden utilizar directamente o afinar (fine-tune) para tareas específicas. - 𖦹
AllenNLP: AllenNLP es un marco de investigación desarrollado por la Universidad de Allen para el Procesamiento del Lenguaje Natural (NLP). Ofrece componentes específicos para construir y entrenar modelos de transformers para tareas de procesamiento de lenguaje natural. - 𖦹
Fairseq: Fairseq es una librería de Facebook AI Research (FAIR) diseñada para tareas de traducción automática y procesamiento de lenguaje natural. Ofrece implementaciones de modelos de transformers, como BART y MarianMT, junto con herramientas para el entrenamiento y la inferencia. - 𖦹
TorchScript y TensorFlow Serving: Para implementaciones en producción de modelos de transformers, TorchScript (para PyTorch) y TensorFlow Serving (para TensorFlow) son herramientas comunes. Estas herramientas permiten empaquetar modelos entrenados y servirlos de manera eficiente en aplicaciones en tiempo real. - 𖦹
Herramientas de Aceleración: Para acelerar el entrenamiento y la inferencia de modelos de transformers, se pueden utilizar unidades de procesamiento de gráficos (GPU) o unidades de procesamiento de inteligencia artificial (IA). Las bibliotecas como NVIDIA CUDA y cuDNN ayudan a aprovechar al máximo el hardware acelerado por GPU. - 𖦹
Librerías de Procesamiento de Lenguaje Natural (NLP): Para tareas de procesamiento de lenguaje natural, como tokenización y procesamiento de texto, se utilizan librerías como spaCy, NLTK y Transformers Tokenizers (parte de Hugging Face Transformers).
Estas son algunas de las principales herramientas y librerías que los investigadores y desarrolladores utilizan para crear y trabajar con modelos de transformers. La elección de la librería y herramientas depende en gran medida de la preferencia personal, la comunidad y los requisitos específicos del proyecto.
Conclusiones
Los transformers representan una revolución en el aprendizaje profundo al permitir el procesamiento eficiente de datos secuenciales. Su versatilidad y rendimiento han llevado a avances significativos en una variedad de aplicaciones, desde el procesamiento del lenguaje natural hasta la visión por computadora y más allá. A medida que esta tecnología continúa evolucionando, es probable que veamos aún más innovaciones en el campo del aprendizaje profundo.