Conceptos Básicos del Networking
El networking, en el contexto de la informática y las tecnologías de la información, se refiere a la práctica de conectar dispositivos y sistemas entre sí para facilitar la comunicación y el intercambio de recursos. El término abarca una amplia gama de actividades relacionadas con la creación, administración y mantenimiento de redes de computadoras, tanto a nivel local como global.
El networking puede tener diferentes propósitos y aplicaciones, que van desde compartir archivos e impresoras en una red local hasta acceder a recursos y servicios a través de Internet.
Control de flujo y congestión
Control de flujo
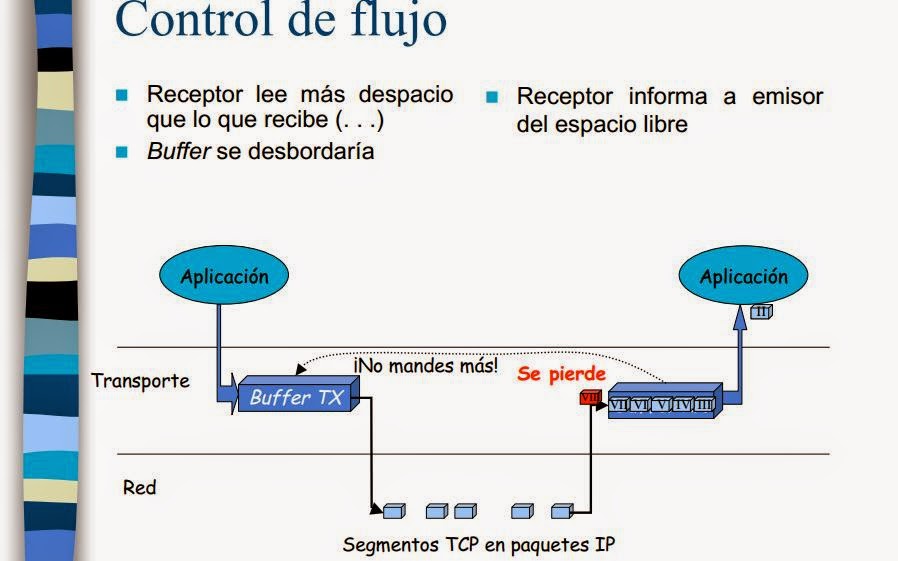
El Control de flujo es el proceso mediante el cual se regula el flujo de datos entre un emisor y un receptor para evitar que el receptor se vea abrumado por una cantidad excesiva de datos. Se implementa utilizando técnicas como el control de ventanas y el control de flujo de retroceso.
Control de Ventanas (Windowing): Control de Flujo de Retroceso (Back Pressure Flow Control):
En TCP, el control de ventanas es un método que permite a un emisor enviar múltiples segmentos de datos antes de esperar una confirmación de recepción del receptor.
El emisor y el receptor acuerdan un tamaño de ventana que determina cuántos segmentos pueden enviarse antes de recibir una confirmación.
Después de enviar una ventana de datos, el emisor espera un ACK (acknowledgment) del receptor. Si recibe el ACK, envía la próxima ventana de datos. Si no recibe ACK, reenvía los segmentos no confirmados.
El tamaño de la ventana puede ajustarse dinámicamente según la congestión de la red y el rendimiento de los nodos.
El control de flujo de retroceso es un mecanismo para evitar que un receptor abrumado por datos envíe más datos al emisor.
Cuando un receptor está sobrecargado, envía una señal de retroceso al emisor, indicando que reduzca la velocidad de envío.
En TCP, esto se logra mediante la utilización del campo de ventana de recepción (window size) en el encabezado TCP. El receptor informa al emisor cuántos bytes puede recibir en ese momento.
Si la ventana de recepción se reduce, el emisor reduce la cantidad de datos enviados para evitar la congestión en el receptor.
Control de congestión
Control de congestión son las medidas tomadas para evitar que una red se sature debido a un exceso de tráfico. Esto incluye algoritmos de enrutamiento inteligente, gestión de colas en los dispositivos de red y la implementación de políticas de priorización de tráfico.
Gestión de Colas: Implementación de Políticas de Priorización de Tráfico:
La gestión de colas en dispositivos de red es esencial para manejar eficientemente el flujo de datos en una red. En routers y switches, se implementan colas para almacenar temporalmente los paquetes cuando hay congestión en la red. Cuando un dispositivo recibe paquetes más rápido de lo que puede enviarlos, estos paquetes se colocan en una cola de espera. La gestión de colas implica determinar cómo se tratan los paquetes en la cola, como cuál se envía primero y cuál se descarta cuando la cola está llena. Los algoritmos de gestión de colas, como FIFO (First-In-First-Out), Round Robin, y PQ (Priority Queuing), determinan cómo se procesan los paquetes en la cola y pueden priorizar ciertos tipos de tráfico sobre otros.
La implementación de políticas de priorización de tráfico es crucial para dar preferencia a ciertos tipos de tráfico sobre otros en situaciones de congestión. Por ejemplo, el tráfico de voz y video puede tener prioridad sobre el tráfico de datos menos sensible al retardo. Esto se puede lograr mediante la asignación de diferentes colas de prioridad para diferentes tipos de tráfico, o mediante el uso de mecanismos como el DiffServ (Differential Services) que establecen clases de tráfico y asignan niveles de prioridad a estas clases. Además, las políticas de control de admisión pueden limitar la cantidad de tráfico que se permite en la red para evitar la congestión.
Protocolos de detección de errores
Los protocolos de detección de errores son mecanismos utilizados en las comunicaciones digitales para garantizar la integridad de los datos transmitidos. Ayudan a detectar si ha habido algún tipo de corrupción en los datos durante su transmisión desde el emisor al receptor. Funcionan agregando información adicional a los datos transmitidos, lo que permite al receptor verificar si los datos han sido alterados durante la transmisión.
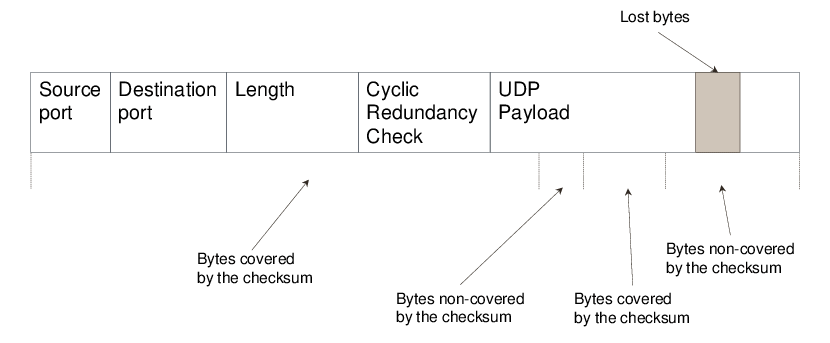
Checksums: Los checksums son valores numéricos derivados de los datos transmitidos. El emisor calcula un checksum basado en los datos y lo envía junto con los datos. El receptor recalcula el checksum al recibir los datos y lo compara con el checksum recibido. Si los checksums no coinciden, se asume que ha ocurrido un error.CRC (Cyclic Redundancy Check): El CRC es un algoritmo más sofisticado que los checksums y se basa en la división polinomial. El emisor y el receptor acuerdan un polinomio generador. El emisor divide los datos por este polinomio y envía el residuo junto con los datos. El receptor realiza la misma operación y compara el residuo calculado con el recibido para detectar errores.Paridad: En la paridad, se agrega un bit adicional a los datos para garantizar que el número total de bits de valor "1" sea par o impar. Si el receptor encuentra un número impar de bits de valor "1", sabe que ha ocurrido un error.
Protocolos de resolución de problemas de red (RARP, ARP, NARP)
RARP (Reverse Address Resolution Protocol): Se utiliza para encontrar la dirección de capa de enlace (MAC) de un dispositivo cuando se conoce su dirección IP.ARP (Address Resolution Protocol): Se utiliza para asociar direcciones IP con direcciones de hardware (MAC) en una red local.NARP (Node Address Resolution Protocol): Similar a ARP, pero se utiliza para encontrar la dirección IP de un nodo cuando se conoce su dirección MAC.
Protocolos de control de enlace (LLC, LCP)
LLC
LLC (Logical Link Control) es un protocolo de la capa de enlace de datos que proporciona servicios de control de errores y control de flujo.
El protocolo de control de enlace lógico (LLC) opera en la capa de enlace de datos (capa 2) del modelo OSI. Su función principal es facilitar un servicio de control de enlace lógico para los protocolos de red que operan en la capa de red (capa 3). Esto implica multiplexar y demultiplexar varios protocolos de capa de red, como IP o IPX, en un solo enlace de datos. Además, LLC proporciona funciones como detección y recuperación de errores, control de flujo y control de acceso al medio. En esencia, LLC establece y mantiene la conexión entre dispositivos de la capa de red, asegurando una comunicación confiable y eficiente.
LCP
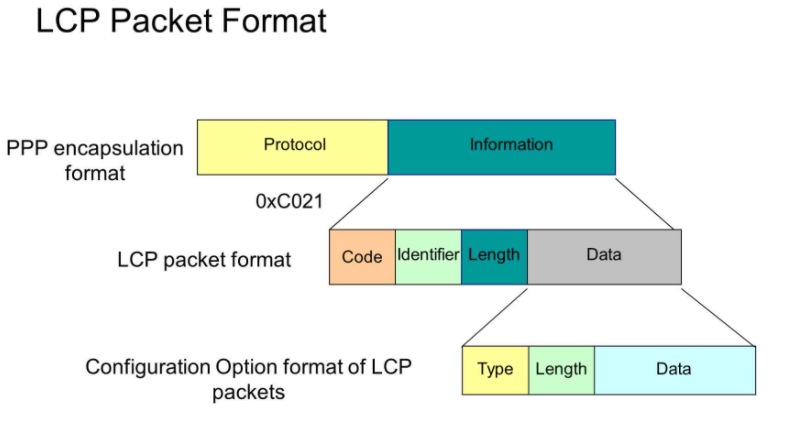
LCP (Link Control Protocol) es un protocolo utilizado para establecer, configurar y probar conexiones de enlace en redes de conmutación de paquetes, como las redes PPP (Point-to-Point Protocol).
El protocolo de control de enlace (LCP) también opera en la capa de enlace de datos (capa 2) del modelo OSI y es un componente esencial del conjunto de protocolos PPP (Point-to-Point Protocol). LCP se encarga de establecer, configurar y probar la conexión física entre dispositivos que utilizan PPP, comúnmente empleados en conexiones punto a punto como las dial-up o de línea dedicada. Negocia los parámetros de la conexión, como la autenticación, la compresión de datos, la dirección IP y otros aspectos de la configuración. Además, supervisa continuamente la calidad de la conexión y puede cerrarla si se detectan problemas.
LCP es el responsable de la configuración y el mantenimiento de las conexiones PPP, garantizando su estabilidad y seguridad. En conjunto, LLC y LCP desempeñan funciones críticas en la configuración, administración y mantenimiento de conexiones de red, asegurando una comunicación confiable y eficiente a través de la capa de enlace de datos.
En conjunto, LLC y LCP desempeñan funciones críticas en la configuración, administración y mantenimiento de conexiones de red, asegurando una comunicación confiable y eficiente a través de la capa de enlace de datos.
Protocolo de configuración de dirección dinámica (DDCP)
Protocolo utilizado para asignar direcciones IP automáticamente a dispositivos en una red, así como también proporcionarles información de configuración adicional, como la dirección del servidor DNS y la puerta de enlace predeterminada.
Algoritmo de acceso aleatorio persistente (PRMA) y CSMA/CD
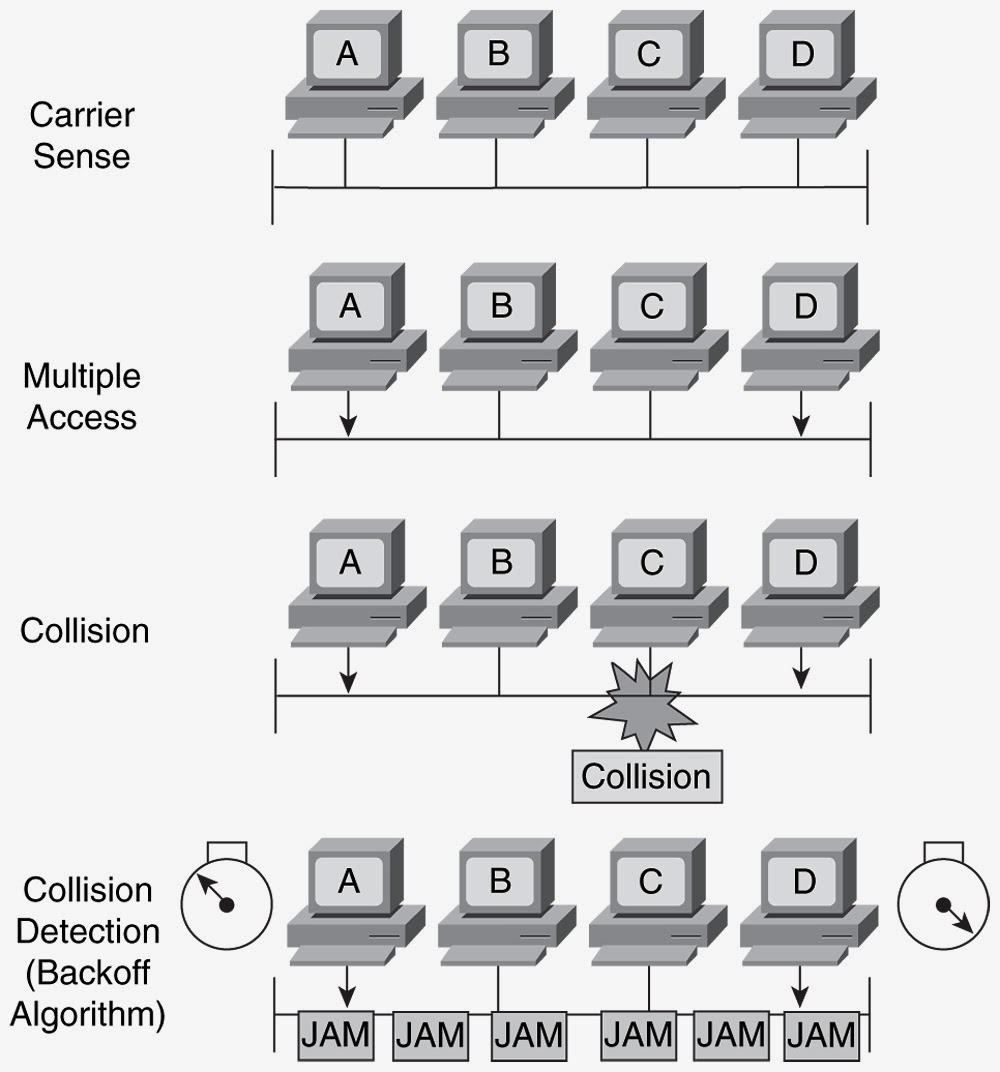
PRMA (Persistent Random Access): Algoritmo utilizado en sistemas de comunicación inalámbrica para coordinar el acceso al medio de comunicación.CSMA/CD (Carrier Sense Multiple Access with Collision Detection): Algoritmo utilizado en redes Ethernet para evitar colisiones en la transmisión de datos. Los dispositivos verifican el medio antes de transmitir y, si detectan actividad, esperan un breve período antes de intentar transmitir nuevamente.
- 〤
Carrier Sense (CS): - ∘ Antes de transmitir datos, un dispositivo Ethernet escucha el medio compartido para detectar si hay alguna señal transmitida por otro dispositivo.
- ∘ Si el medio está en silencio (no hay señal detectada), el dispositivo puede iniciar su transmisión. Si detecta actividad en el medio, espera un tiempo aleatorio antes de volver a verificar el estado del canal.
- 〤
Multiple Access (MA): - ∘ Varios dispositivos pueden intentar transmitir datos en el mismo medio compartido.
- ∘ El acceso al medio es compartido y cualquier dispositivo puede intentar transmitir en cualquier momento.
- 〤
Collision Detection (CD): - ∘ Si dos dispositivos comienzan a transmitir al mismo tiempo y sus señales colisionan en el medio compartido, ambos dispositivos detectan la colisión.
- ∘ Cuando un dispositivo detecta una colisión, interrumpe su transmisión y envía una señal especial llamada jamming signal para notificar a los otros dispositivos de la colisión.
- ∘ Después de enviar la señal de jamming, los dispositivos esperan un tiempo aleatorio antes de intentar retransmitir.
Plano de datos y control en redes
El plano de datos se refiere al camino a través del cual fluyen los datos en una red, desde el emisor hasta el receptor.
El plano de control se refiere al conjunto de funciones y protocolos que gestionan y controlan el funcionamiento de la red, incluida la señalización, el enrutamiento y la administración del tráfico.
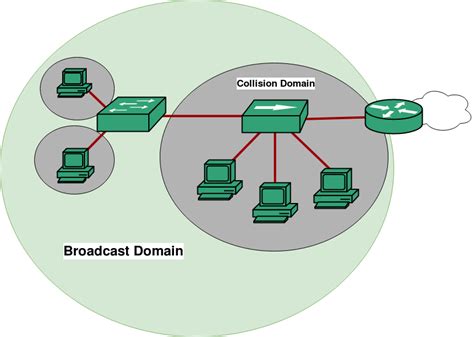
Dominio de Broadcast y Dominio de Colisión
En términos simples, un dominio de broadcast es un área de una red donde un mensaje de broadcast enviado por un dispositivo alcanzará a todos los demás dispositivos en esa área.
La División del Dominio de Broadcast es una técnica utilizada para segmentar una red en dominios de broadcast más pequeños, lo que ayuda a reducir la congestión de la red y mejora el rendimiento. Se puede lograr mediante la subdivisión de la red en VLANs (Virtual Local Area Networks) o mediante el uso de enrutadores para separar físicamente las partes de la red.
Cada interfaz del router representa un límite entre diferentes dominios de broadcast.
Un dominio de colisión es un área de una red donde los paquetes de datos pueden colisionar entre sí si varios dispositivos intentan transmitir datos al mismo tiempo.
Un dominio de colisión está delimitado por los dispositivos que están conectados en un mismo segmento físico de red. Los segmentos físicos de red incluyen cables Ethernet compartidos, hubs y puertos de switches configurados en modo de hub (modo de puerto no conmutado).